
|
|
Графическая интерпретация эмпирических зависимостейЧастотные распределения изображаются также в виде диаграмм и графиков. Главным достоинством графического изображения является его наглядпость. Графическая интерпретация эмпирических зависимостей основана на знании технических правил построения рядов, типов и свойств теоретических распределений. Здесь мы рассмотрим графики вариационных рядов: гистограмму, полигон и кумуляту распределения. Гистограмма. Гистограмма — это графическое изображение интервального ряда. По оси абсцисс откладывают границы интервалов, на которых строят прямоугольники с высотой, пропорциональной: плотностям распределения соответствующих интервалов (пропорциональной числу единиц совокупности, приходящейся на единицу длины интервала). При равных интервалах плотности распределе-
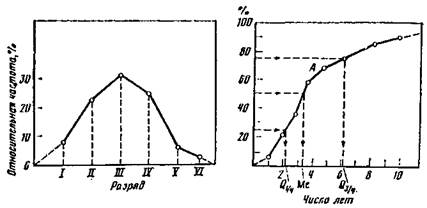
Рис. 1. Гистограмма распределения соотношопия брачпых возрастов разводящихся супругов пия пропорциональны частотам, которые и откладываются по оси ординат (рис. 1, табл. 2). На гистограмме общее число лиц в каждой категории выражается площадью соответствующего прямоугольника, а общая площадь равна численности совокупности (так как гистограмма иа рис. i строится по относительным частотам, то площадь равна единице (100%)). Поэтому для интервалов 4—6, 6—8, 8—10 в табл. 2, ко-
Таблица 2. Распределение брачных возрастов разводящихся супругов * Муж старше Шены (на сколько лет) Показателя мснь- )л _ Ше 1—2 2-3 3-4 4-6 в-8 8-10 более Года Число людей в 12 И 19 14 7 1 13 % к общему числу 7,2 14,5 1.4,2 22,9 1Г>,9 8,4 1,2 15,7 Накопленная частота С IS 29 48 G2 09 70 83 Накопленная относи- 7,2 21,7 34,9 57,8 74,7 83,1 84,3 100 * Социальные исследования. М., 1965, яып. 1, с. 163. торые в 2 раза больше предыдущих, нужно брать высоты прямоугольников в 2 раза меньшие. При нанесении на графике последнего открытого интервала «10 лет и более» условно будем считать верхней его границей 40 лет. Тогда ширина интервала равна 30 годам, а плотность распределения — около 0,5% (15,7 : 30 » 0,5). Полигон распределения. Для построения полигона величина признака откладывается на оси абсцисс, а частоты или относительные частоты — на оси ординат. Из точек, соответствующих значениям признака, восстанавливаются перпендикуляры, равные по высоте частотам. Вершины перпендикуляров соединяются прямыми линиями. Для интервального ряда ординаты, пропорциональные частоте (или относительной частоте) интервала, восстанавливаются перпендикулярно оси абсцисс в точке, соответствующей середине даиного интервала. Следующие данные распределения рабочих в возрасте до 24 лет по тарифным разрядам (высококвалифицированные рабочие сельхозмашиностроения)" дают возможность построить полигон распределения (рис. 2): Разряд Т II Ш IV V VI Численность, % к итогу 8,4 22,6 31,9 24,1 6,2 0,3 Накопленные частоты 8,4 31,0 62,3 87,0 93,2 93,5 Условно принято крайние ординаты признака соединять с сере-» динами примыкающих интервалов (на рис. 2 эти замыкающие линии нанесены пунктиром). Однако для распределения, где концентрация событий увеличивается на концах полигона, такое изображение может привести к ложным представлениям о существе явления. Кумулята. Для графического изображения вариационных рядов используются также кумулятивные кривые. При построении куму-ляты, как и гистограммы, на оси абсцисс откладываются границы интервалов (либо значения дискретного признака), а на оси ординат — накопленные частоты (либо относительные частоты), соответствующие верхним границам интервалов. Таким образом, отяичие кумуляты от гистограммы в том, что на графике кумуляты столбики, пропорциональные частотам, последовательно накладываются один на другой, так что высота последнего столбика является суммой высот столбиков гистограммы. Кумулята округляет индивидуальные значения признака в пределах интервала и представляет собой возрастающую ломаную линию. Кумулята позволяет быстро определить процент лиц, находящихся ниже или выше заданной величины признака. Например, по данным табл. 3, процент семейств, в которых муж старше супру-» гц не более, чем на 5 лет, равен 65 (рис. 3, точка А), 13 Проблемы использования рабочей силы в условиях научно-технической ре-иолюции. М., 1973, с. 168. Сумма всех относительных частот не равиа 100%, поскольку опущена графа «вне разряда»,
Гие.2. Полигон распределения работающих по тарифным разрядам Рис.3. Куыулята распределения соотношения брачных возрастов разводящихся супругов Вид (форма) кривых распределений.Кривые, полученные вро. вультате графического представления эмпирических данных, могут иметь разнообразную форму. Среди пих можно выделить относительно небольшое количество простых типов. Некоторые возможные формы распределений приведены на рис. 4. Анализ формы кривых иногда помогает в выявлении внутренней, скрытой структуры исследуемой совокупности. Например, можно предположить, что форма кривой в обусловлена наложением двух кривых: а и б, иначе говоря, предположить, что существует третья скрытая перемепная (или группа переменных), детерминирующая расчленение совокупности на две группы. Существует множество конкретных примеров того, как графиче* ский анализ стимулирует дальнейшее развитие исследовательской мысли. Теоретическое распределение. Сбор эмпирической информации может быть осуществлен двумя путями: исследованием всей совокупности социальных объектов, которые являются предметом изучения в пределах, очерченных программой социологического исследования, и изучением лишь части этих объектов. В первом случае исследование называется сплошным, а множество социальных объектов — генеральной совокупностью, во втором исследование на-«ывается выборочным, а выделенная часть объектов — выборкой " Одна из основных, задач статистики состоит в том, чтобы по данным выборки оценить параметры генеральной совокупности. Гистограмма и полигон распределения, построенные на основе эмпирических данных выборки, позволяют выявить лишь прибли*
Тис.4. Различные формы кривыхрас- Рнс.5. Теоретическая кривая распре- женную картину реального распределения в генеральной совокупности. При увеличении выборочной совокупности и все большем дроблении величины интервалов эмпирическое распределение в виде гистограммы или полигона все более приближается к некоторой кривой, называемой кривой распределения. Если группировочпый признак является непрерывной величиной, то в предельном случае при постепенном уменьшении величиии интервала полигону и гистограмме будет соответствовать некоторая Гладкая кривая (рис. 5). Эта кривая распределения, являющаяся предельным случаем полигона данного эмпирического распределения, называется по установившейся терминологии кривой плотности распределения. "Обозначим соответствующую функцию fix). В терминах теории вероятностей плотность распределения можно трактовать следующим образом: вероятность (р) того, что случайная величина (£) примет значение из достаточно малого интервала (XiXi+i), равна произведению длины интервала на высоту пря-агоугольника (/(#()), т. е. p(xt < I < xi+i) ж /(*,)(*,+, - х„). Для иптервала произвольной длины суммированием этих значений получим, что ь p(a<t<b) = $f(x)dx. a Отсюда приходим к определению фундаментального понятия теории вероятностей — функции распределения (F) случайной вв-личины (£), которая но определению есть Знание функции распределения дает исчерпывающее представление о поведении совокупности в отношении изучаемого признака, поэтому определение типа распределения признаков представляет одну из задач исследования массовых явлений. Л. Средние величины и характеристики рассеяния значений признака Группировка и построение частотного распределения — лишь первый этап статистического анализа полученных данных. Следующим шагом обработки является получение некоторых обобщающих. >арактеристик, позволяющих глубже понять особенности объекта наблюдения. Сюда относится прежде всего среднее значение признака, вокруг которого варьируют остальные его значения, и степень колеблемости рассматриваемого признака. В математической статистике различают несколько'видов средних величин: среднее арифметическое, медиана, мода и т. д.; существует также несколько показателей колеблемости (мер рассеяния): вариационный размах, среднее квадратическое отклонение, среднее абсолютное отклонение, дисперсия и т. п.17 Среднее значение признака. Среднее есть абстрактная типическая характеристика всей совокупности. Оно уничтожает, погашает, сглаживает случайные и неслучайные колебания, влияние индиви-луальных особенностей и позволяет представить в одной величине некоторую общую характеристику реальной совокупности единиц. Основное условие научного использования средних заключается в том, чтобы каждое среднее характеризовало такую совокупность единиц, которая в существенном отношении, и в первую очередь- в отношении осредняемых значений признака, была бы качественно однородной. Среди всего многообразия средних практически наиболее часто используемой считается среднее арифметическое. Среднее арифметическое. Среднее арифметическое есть частное от деления суммы всех- значений признака на их число. Обозначается оно х. Формула для вычисления имеет вид п где х,, ..., хп — аначения признака, п — число наблюдений. По следующим данным вычислим среднее число газет, читаемых ежедневно индивидами в выборке из 10 человек: Покер опрошенного i 123456789 10 in Число читаемых газет х{ 3445424553 2х; = 39 i=l Ло формуле для х находим * = -^- = 3,9 (газеты). " Здесь я далее в этой главе речь идет о так называемых выборочных характеристиках (средней, дисперсии н т. д.). Формула (1) для сгруппированных данных преобразуется в слс-« дуюшую: h П ИАЧ- И« + • • • + "fc' где nt — частота для i-ro значения признака. Бели находят среднюю для интервального ряда распределения, то в качестве значения признака для каждого интервала условно принимают его середину. Процедуру вычисления среднего по сгруппированным данным удобно выполнять по следующей схеме (табл. 3). Таблица 3. Скеиа вычисления среднего арифметического
ваются все интервалы Х| П| Х|П| *
Пример. Вышеприведенные дапные о количестве прочитанных газет (см. с. 159) сгруппируем следующим образом: Номер опрошенного ( С 110 2357 480 Число читаемых газет xL 2 33 4444 555 4 Отсюда вычислим х: 2-1 + 3-2 + 4-4+5-3 „ „ , . х =-------- ±------ ^------- ±------- = 3,9 (газеты). Медиана. Медианой называется значение признака у той единицы совокупности, которая расположена в середине ряда частотного распределения. Бели в ряду четное число членов (2к), то медиана равна среднему арифметическому из двух серединных значений признака. При нечетном числе членов (2к + 1) медианным будет значение призна--ка у (k + i) объекта. Предположим, что в выборке из 10 человек респонденты про-ранжированы по стажу работы ыа данном предприятии:
В интервальном ряду с различными значениями частот вычисле-пие медианы распадается на два этапа: сначала находят медианный интервал, которому соответствует первая из накопленных частот, превышающая половину всего объема совокупности, а затем находят значение медианы по формуле 1 Ме = хо + 8^—------ -, (2) где х0 — начало (нижняя граница) медианного интервала; б — величина медианного интервала; л = 2га( — сумма частот (относительных частот) интервалов; пн — частота (относительная), накопленная до медианного интервала; пи, — частота (относительная) медианного интервала. Проведем вычисление по данным табл. 2, где в нижней строке приведены накопленные относительные частоты. Первая из них, превышающая половину совокупности (100/2 = 50%), равна 57,9%. Следовательно, медиана принадлежит интервалу 3—4 года. Поэтому ^-35 Л/* = 3 + 1 Таким образом, для данной выборки медиана, равная 3,7 года, показывает, что 50% семей имеют соотношение возрастов, меиьшее »1 ой величины, а другие 50%—большее. Медиана может быть легко определепа графически по кумуляте распределения (см. рис. 3). Медиана может быть применена для дискретных переменных, хотя дробные значения часто не имеют непосредственной содержательной иптерпретации. По данным распределения рабочих по тарифным разрядам (см. с. 156) вычислим медиану этого распределения, используя приведенную выше формулу ". Получим Л/е = 2,5 + 1 -^%=~ = 3,1. Узпалп, что 50% рабочих имеют разряд, меньший 3,1, и 50% — больший. " Предполагается, что медианный интервал разряда равен 2,5—3,5, Медиана, как уже отмечалось, делит упорядоченный вариационный ряд на две равные по численности группы. Наряду с медианой можно рассматривать величины, называемы» квантилями, которые деляг ряд распределения на 4 равные частиг на 10 и т. д. Квантили, которые делят ряд на 4 равные по объему совокупности, называются квартилями. Различают нижний Q<t, и верхний. <?•/. квартили (рис. 6). Величина Q% является медианой. Вычисление квартилей совершенно аналогично вычислепию медианы: Qi/. = хо + о-------------- ;---------- ; w) "Q _ п "4~(2ni)-"H . Q»ti = xo + 6 --------------- г---------- г (*> nQ где Хо — минимальная граница интервала, содержащего нижний (верхний) квартиль; пн — частота (относительная частота), накопленная до квартильного интервала; nQ — частота (относительная частота) квартильного интервала; б — величина квартильного интервала. Процентили делят множество паблюдепий на 100 частей с равным числом наблюдений в каждой. Децили делят множество наблюдений на десять равных частей. Квантили легко вычисляются по распределению накопленных частот (по кумуляте). Мода. Модой в статистике называется наиболее часто встречающееся значение признака, т. е. значение, с которым наиболее вероятно можно встретиться в серии зарегистрированных наблюдений. В дискретном ряду мода (Мо) — это значение с наибольшей частотой. В интервальном ряду (с равными интервалами) модальным является класс с наибольшим числом наблюдений. Значение моды находится в его пределах и вычисляется по формуле Мо = х0 + 6 2пш~п -» где ха — нижняя граница модального интервала; 6 — величина интервала; п~ — частота интервала, предшествующего модальному; пмо — частота модального класса; п+ — частота интервала, следующего за модальным. В совокупностях, в которых может быть произведена лишь операция классификации объектов по какому-нибудь качественному признаку, вычисление моды является единственным способом указать некий центр тяжести совокупности. К недостаткам моды следует отнести следующие: невозможность совершать над ней алгебраические действия; зависимость ее величины от интервала группировки; возможность существования в ряду распределения нескольких модальных значений признака (см., например, рис. 4, в). С равнение средних. Целесообразность использования того или иного типа средней величины зависит по крайней мере от следующих условий: цели усреднения, вида распределения, уровня измерения признака, вычислительных соображений. Цель усреднения связана с содержательной трактовкой рассматриваемой задачи. Однако форма распределения может существенно усложнить исследование средних. Если для симметричного распределения (см. рис. 4, а) мода, медиана и среднее арифметическое тождественны, то для асимметричного распределения это не так. На выбор средней может повлиять и вид распределения. Например, для ряда с открытыми конечными интервалами нельзя вычислять среднее арифметическое, но если распределение близко к симметричному, можно подсчитать тождественную ему в этом случае медиану. Показателиколеблемости (вариация) значений признаков.Для характеристики рядов распределения оказывается недостаточным указание только средней величины данного признака, поскольку два ряда могут иметь, к примеру, одинаковые средние арифметические, но степень концентрации (или, наоборот, разброса) значений признаков вокруг средней будет совершенно различной. Характеристикой такого разброса служат показатели колеблемости — разность между максимальным и минимальным значениями признака в некоторой совокупности (вариационный размах), а также другие показатели: среднее абсолютное (линейное) отклонение, среднее квад-ратическое отклонение и т. п. Дисперсия. Дисперсией называется величипа, равная среднему значению квадрата отклонений отдельных значений признаков от средней арифметической. Обозначается дисперсия sl ивычисляется ло формуле
Геометрически среднее квадратическое отклонение является показателем того, насколько в среднем кривая распределения размыта относительно ее среднего арифметического. Измеряется в тех же единицах, что и изучаемый признак. При ручном счете для упрощения вычислений дисперсию (s) рассчитывают по формуле методом отсчета от условного нуля. Для интервального ряда с равными интервалами процедура следующая. Сначала вычисляются центры интервалов. Относительно какого-либо отобранного серединного интервала ряда, например А, вверх и вниз выписывается натуральный ряд чисел (а<) соответственно со знаком «плюс» и «минус»: 0, +1, +2 и т. д.; —1, —2 и т. д. (табл. 4). Далее вычисляются величины aj, а^, а%пх. В качестве промежуточного результата по формуле (7) получаем среднее арифмети- ческое. Величина дисперсий получается подстановкой промежу* точных величин из табл. 4 в формулу (8). Среднее арифметическое находится по формуле " h *=-^------ б + Л = ^|^_ + 42,5 = 40,1(лет). (7) Тогда дисперсия равна $2 = 1>ЬЧ §2 _ (- _ Л)2= 512 52 _ (40д _ 42)5)2 = 616 (8) п — 1 1У1 — 1 s = /НТВ = 7,8 (лет). Приведенные вычисления показывают, что при средпем возрасте-40 лет все остальные члены совокупности имеют возраст, который в среднем отклоняется от 40 лет на 7,8 лет, т. е. примерло на 20%. Таблица 4 *. Пример вычисления дисперсии
* Численные данные о распределении кандидатов наук по возрастным группам в отделении 9Н0Н0МИНИ, истории, философии и права АН УССР (Организация науки/ Под ред. Г: М. Доброва, М., 1970, с. 148—149).
У\\х,—х\п. •» Необходимо отметить, что средние арифметические, подсчитанные по формулам (7) и' (1), тождественны между собой так же, как и дисперсии, найденные по формулам (6) и (8), Отличаются они лишь формой записи. i64
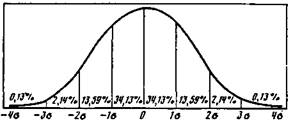
Рие.в. Нижний и верхний квартили, медиана Рис.7. Кривая нормального распределения Рие.8. Кривая нормального распределения и доли частот под ней где \xt — x\ означает, что суммируются значения отклонений без учета знака этих отклонений; л = 2л<— объем совокупности. Вместо среднего арифметического в формуле 9 часто берут моду или медиану. Для симметричных распределений мода, медиана и среднее арифметическое совпадают и выбор средней не представляет труда. Для асимметричного распределения иногда отдают предпочтение медиане. Величина среднего квадратического отклонения всегда больше d и для достаточно большой выборочной совокупности с распределением признака, близкого к нормальному, связана с 3. соотношением *«1,25<J. (10) Например, для данных табл. 4 вреднее линейное отклонение, подсчитанное по формуле 9, равно d = 6,3 года. Тогда « = 1,25-6,3 = 7,87, что с учетом погрешности вычислений совпадает с найденным ранее средним квадратическим отклонением. Таким образом, для предварительного анализа можно заменить вычисление s менее трудоемким вычислением 3. Коэффициент вариации. Среднее линейное и среднее квадрати-ческое отклонение являются мерой абсолютной колеблемости признака и всегда выражаются в тех же единицах измерения, в которых выражен изучаемый признак. Это не позволяет сопоставлять между собой" средние отклонения различных признаков (в случае разных единиц измерения) в одной и той же совокупности, а также одного и того же признака в разных совокупностях с различными средними. Чтобы иметь такую возможность, средние откло- пепия часто выражаются через соотнесение в процентах к среднему арифметическому, т. е. в виде относительных величин. Отношение среднего линейного или среднего квадратического отклонения к среднему арифметическому называется коэффициентом вариации (V): y; = -L.100%; (11) X V"d = 4--l00%. (12) X Очевидно, что тот из рядов имеет большее рассеяние, у которого коэффициент вариации больше. Рассмотренные выше показатели вариации применимы лишь к количественным признакам, а точнее к признакам, измеренным не ниже чем по интервальной шкале. Применение этих мер для низших уровней, строго говоря, некорректно и требует тщательной интерпретации полученных результатов. Вариации качественных признаков. Если признак имеет к взаимоисключающих градаций, то для вычисления индекса качественной вариации применяется процедура, поясняемая следующим примером. Пусть получено следующее распределение ответов (взаимоисключающих) на вопросы А, В и С (колонка 1): 1 2 А 30 40 В 20 40 С 70 40 Ш 120 Во вторую колонку запишем такие частоты, которые получились бы при равномерном заполнении всех трех вопросов, т. е. 120/3 = 40. Теперь вычислим величину Т (30-20)+(30-70)+ (20-70) ,m Rt- ,0/ .,„ J = (40-40)+ (40-40)+ (40-40) " 10° /о = 85-4% • (13) Этот показатель называется индексом качественной вариации и указывает на степень неоднородности полученных ответов. Если бы все ответы попали лишь в одну градацию, то / *= 0, что означало бы полное единство в ответах, хот», конечпо, индекс совершенно не учитывает того, в какую именно градацию попали все эти ответы. Совершенно аналогично индекс вычисляется при любом числе градаций. Но для альтернативных признаков вариация обычно под-считывается по формуле (14). Опа отличается от J на константу, называется дисперсией, выражается в абсолютных числах и обозначается s1:
Другой мерой вариации признака (независимо от уровня измерения) может служить так называемая энтропия — мера неопределенности, вычисляемая по формуле H h Н = — 2mJlogmi = logn--- ^-^Wjlogn;. (15) i=l i=l Логарифм в этой формуле может быть взят по любому основанию. Энтропия обладает следующими свойствами: а) энтропия равна нулю лишь в том случае, если вероятность полу б) наибольшей энтропией обладает признак, когда все значения #т,х = log /С. Отсюда видно, что максимальная энтропия увеличивается с ростом числа градаций в признаке. 
Не нашли, что искали? Воспользуйтесь поиском по сайту: ©2015 - 2026 stydopedia.ru Все материалы защищены законодательством РФ.
|

 u Методы построения выборки, подробно изложены в гл. б.
u Методы построения выборки, подробно изложены в гл. б.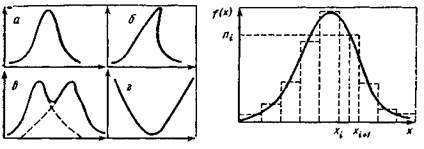
 Середина ин- Частота (относи- Произведение
Середина ин- Частота (относи- Произведение Последовательно высгнгы- xt n^ х^
Последовательно высгнгы- xt n^ х^ Существует ряд упрощенных приемов вычисления средних. На с. 163 как промежуточный этап рассмотрено вычисление средвего методом отсчета от условного нуля.
Существует ряд упрощенных приемов вычисления средних. На с. 163 как промежуточный этап рассмотрено вычисление средвего методом отсчета от условного нуля. Ранг опрошенного 1234 5 В 7 89 10
Ранг опрошенного 1234 5 В 7 89 10 Стаж 15 13 10 91 7 6 5 4 3-1
Стаж 15 13 10 91 7 6 5 4 3-1 Серединные ранги 5 и 6, поэтому медиана равна
Серединные ранги 5 и 6, поэтому медиана равна Корень квадратный из дисперсии называется средним квадратиче-ским отклонением и обозначается s.
Корень квадратный из дисперсии называется средним квадратиче-ским отклонением и обозначается s.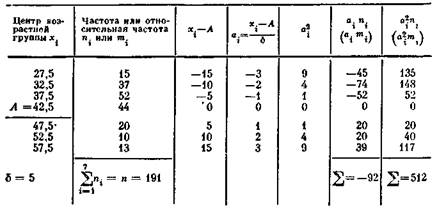
 Среднее абсолютное отклонение. Эта мера вариации представляет собой среднее арифметическое из абсолютных величин отклонений отдельных значений признака от их среднего арифметического * _
Среднее абсолютное отклонение. Эта мера вариации представляет собой среднее арифметическое из абсолютных величин отклонений отдельных значений признака от их среднего арифметического * _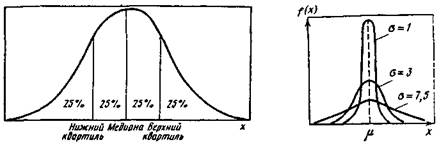
 ("l + пг) п \ п ) v I
("l + пг) п \ п ) v I