
|
|
Номер Общий стаж заработная , ,рсспон- работы/х), плата и,, руб. *J "i Vi дейта лет ' 1 20 190 400 36 100 3800 2 21 180 441 32 400 3780 3 2 130 4 16 900 260 4 18 160 324 25 600 2880 5 1 90 1 8 100 90 6 3 НО 9 12 10) 330 7 i i00 1 10 000 100 8 2 100 4 10 000 200 9 18 150 324 22 500 2700 10 28 220 784 48 400 6160 11 4 120 16 14 400 480 12 6 110 36 12 100 660 13 1 НО 1 12 100 110
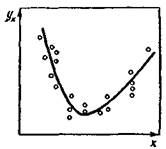
14 15 200 225 40 000 3000 15 25 210 625 44100 5250 16 7 170 49 28 900 1190 17 21 160 441 25 600 3360 18 12 160 144 25 600 1Ш 19 14 120 196 14 400 1680 20 9 140 81 19 600 1260 21 13 130 169 16 900 1690 22 15 100 225 25 600 2400 23 19 200 361 40 000 3800 24 23 180 529 32 400 4140 25 10 120 100 14 400 1200 л = 25 2*i=308 2"i = 3720 24 - 5490 2"» = 588 200 2 = 52 44° J= 12,32 7= 1*8,80 ные) для выборки в 25 человек, а на рис. 9 эти численные данныз представлены в виде так называемой диаграммы рассеяния, или разброса. Вообще говоря, визуально не всегда можно определить, существует или нет значимая взаимосвязь между рассматриваемыми признаками и насколько она значима, хотя очень часто уже на Диаграмме просматривается общая тенденция в изменении значений признаков и направление связи между изучаемыми признаками. Уравнение регрессии. Статистическая зависимость одного или большего числа признаков от остальных выражается с помощью уравнений регрессии. Рассмотрим две величины х и у,, такие, например, как на рис. 9. Зафиксируем какое-либо значение переменной х, тогда у принимает целый ряд значений. Обозначим у среднюю величину этих зна'чений у при данном фиксированном: х. Уравнение, описывающее зависимость средней величины ух от х, называется уравнением регрессии у по х: yx = F{x). Аналогичным образом можно дать геометрическую интерпретацию регрессионному уравнению" х„ = Ф(у). Уравнение регрессии описывает числовое соотношение между величинами, выраженное в виде тенденции к возрастанию (или убыванию) одной переменной величины при возрастании (убывании) другой. Эта тенденция проявляется на основе некоторого числа наблюдений, когда из общей массы выделяются, контролируются, измеряются главные, решающие факторы. Характер связи взаимодействующих признаков отражается в ее форме. В этом отношении полезно различать линейную и нелинейную регрессии. На рис. 10, 11 приведены графики линейной и криволинейной форм линий регрессии и их диаграммы разброса для случая двух переменных величин. Направление и плотность (теснота) линейной связи между двумя переменными измеряются с помощью коэффициента корреляции. Меры взаимозависимостидля интервального уровня измерения.Наиболее широко известной мерой связи служит коэффициент корреляций Пирсона (или, как его иногда называют, коэффициент корреляции, равный произведению моментов). Одно из важнейших предположений, на котором покоится использование коэффициента г, состоит в том, что регрессионные уравнения для изучаемых переменных имеют линейную форму23, т. е. y,=*y~+bt(x-x) (18> либо Zy^x + btiy-lj), (19) где у — среднее арифметическое для переменной у; х — среднее арифметическое для переменной х; bi и Ьг — некоторые коэффициенты. Поскольку вычисление коэффициента корреляции и коэффициентов регрессии Ь, и Ь2 проводится по схожим формулам, то, вы-
попыткой аппроксимации существующей зависимости. 2' В нелинейном случае его разумнее рассматривать как показатель тенденции и лишь отчасти как меру тесноты этой связи.
Рис. 9. Диаграмма рассеяния для распределения заработной платы к общего стажа работы Ряс. 10. Линии регрессии для распределения заработной платы и общего стажа работы х — стаж работы, лет; у — заработная ллата, руб. Рис. П. Линия регрессии криволинейной формы к диаграмма рассоя-лия числяя г, получаем сразу же и приближенные регрессионные модели ". Выборочные коэффициенты регрессии и корреляции вычисляют-! ся по формулам
Здесь si — дисперсия признака х; si — дисперсия признака у. Be-i личина Sxy называется ковариацией хну. •' Линия регрессии, которая «наилучшим» образом соответствует эмпирическим данным, находится с помощью так называемого метода наименьших квадратов, а именно так, чтобы сумма квадратов отклонений каждой точки (на диаграмме разброса) от линии регрессии была минимальной. Расчет г для несгруппированных данных. Для вычислительных целей эти выражения в случае песгруппированных данных можно переписать в следующем виде:
Рассчитаем коэффициент корреляции и коэффициенты регрессии для данных табл. 7: , _ 25-52 440 —308-3720 _ 165 240 _ „ „„ 1~ 25-5490 — ЗОв* ~42i86~'d' ' 2 ~ 25-588 200 — 3720» ~~ ЬС6 600 "" ' ' г==________ 165240__ 086 42 386-866 600 ~"'ои- Тогда уравнение регрессии имеет вид 0 = 148,8 + 3,9(^-12,3), х = 12,3 + 0,19(0 -148,8). Линии регрессии у = Fix) изображены на рис. 10. Отсюда видно, что между заработной платой и общим стажем работы существует прямая зависимость: по мере увеличения общего стажа работы на предприятии растет и заработная плата. Величина коэффициента корреляции довольно большая и свидетельствует о положительной связи между переменными величинами. Следует отметить, что вопрос о том, какую переменную в данном случае принимать в качестве зависимой величины, а какую — в качестве независимой, исследователь решает на основе качественного анализа и профессионального опыта. Коэффициент корреляции по определению является симметричным показателем связи: г*, = гух- Область возможного изменения коэффициента корреляции г лежит в пределах от +1 до —1. Вычисление г для сгруппированных данных. Для сгруппированных данных примем ширипу интервала по каждой переменной за единицу (если по какой-либо переменной имеются неодинаковые размеры интервала, то возьмем из них наименьший). Выберем также начало координат для каждой переменной где-нибудь возле среднего значения, оцененного на глаз. Для условных данных, помещенных в табл. 8, за нулевую точку отсчета выберем значение у, равное 64, а по х — значение 134,5. Тогда коэффициент корреляции определяется по следующей формуле: H i 2 2павл-лЬА
нение от условной средней по признаку у; щ — частота наблюдений по клеткам таблицы; А 21 »л /» \/ Ъх = J-L.------ ; Ьи = I 2, пиаЛ п; Для вышеприведенного примера порядок вычислений представлен & 4 в табл. 9. Для определения 2 2 njjaxay вычислим последователь- но все произведения частоты в каждой клетке таблицы на ее координаты. Так nnaXlaVl= 6f(+2)(-l)] = -12, «««.,«,,, = 20 [(+.1) (- 1)1 = - 20, "г2в*гау2 = 24[(+1)(0)] = 0,
Подсчитаем К и by: Ьх = -17/185 = -0,09; Ь„= 97/185 = 0,52. Определяем sx и sB:
Г = 185 • 0,96 • 0,92 ' ' Таким образом, величина связи достаточно велика, как, впрочем, я следовало ожидать на основе визуального анализа таблицы. Статистическая значимость г. После вычисления коэффициента корреляции возникает вопрос, насколько показателен этот коэффициент и не обусловлена ли зависимость, которую он фиксирует, случайными отклонениями. Иначе говоря, необходимо проверить гипотезу о том, что полученное значение г значимо отличается от 0. Если гипотеза Яо (г = 0) будет отвергнута, говорят, что величина коэффициента корреляции статистически значима (т. е. эта величина не обусловлена случайпостью) нри уровне значимости а. Для Случая, когда п < 50, применяется критерий t, вычисляемый по формуле t =*]/"-£>(»—2) df = n-2. (23) Распределение t дано в табл. В приложения. Если п > 50, то необходимо использовать Z-критерий г = Т7уЬ- <24> В табл. А приложения приведены значения величины ZKt для соответствующих а. Вычислим величину Z для коэффициента корреляции по табл. 7 (вычисление проделаем лишь для иллюстрации, так как число наблюдений п = 25 и нужно применять критерий t). Величина г (см. табл. 7) равна 0,86. Тогда 0,86 _ & 0 z- 1/У2ГП -4- Для уровня значимости а = 0,01 ZKf == 2,33 (см. табл. А приложения). Поскольку. Z>ZKP, мы должны копстатировать, что коэффициент корреляции г = 0,86 значим и лишь в 1% случаев может оказаться равным нулю. Аналогичный результат дает и проверка по критерию t для а = 0,01 (односторонняя область); tKV == 2,509, t выборочное равно 8,08. Другой часто встречающейся задачей является проверка равенства па значимом уровне двух коэффициентов корреляции. Н„ : г, = = г2 при заданном уровне а, т. е. различия между г, и гг обусловлены лишь колебаниями выборочной совокупности. Критерий для проверки значимости следующий; Z = ----- ,// < у,/ ' у ; где значения zrj и гГ2 находят по табл. Д приложения для rt и г2. Значения 2ир определяют по табл. А приложения аналогично вышеприведенному примеру. Частная и множественная регрессия и корреляция. Ранее памп было показано, как можно по опытным данным найти зависимость одной переменной от другой, а именно как построить уравнение регрессии вида у = а + Ьх. Если исследователь изучает влияние нескольких переменных х,, х%, ..., хк на результатирующий признак у, то возникает необходимость в умении строить регрессионное уравнение более общего вида, т. е. y=a + bixi + b1x1+, ..., +bkxk, (26> где a, bt, b2, ,.., bk — постоянные коэффициенты, коэффициенты регрессии. В связи с уравнением (26) необходимо рассмотреть следующие вопросы: а) как по эмпирическим данным вычислить коэффициенты регрессии а, Ь,, Ьг, ..., bh; б) какую интерпретацию можпо приписать этим коэффициентам; в) оценить тесноту связи между у и каждым из xt в отдельности (при элиминировании действия остальных); г) оценить тесноту связи между у и всеми переменными Xi, ..., Хк в совокупности. Рассмотрим этот вопрос па примере построепия двухфакторного регрессионного уравнения. Предположим, что изучается зависимость недельного бюджета свободного времени (у) от уровня образования (х,) и возраста (х2) определенной группы трудящихся по данным выборочного обследования. Будем искать эту зависимость в виде-линейного уравнения следующего вида: у = а + btXt + Ьгхг. При расчете коэффициентов уравнения множествеппой регрессии полезно преобразовать исходные эмпирические данные следующим образом. Пусть в результате обследования п человек получены эмпирические значения, сведенные в следующую таблицу (в каждом столбце представлены несгруппированные данные): Номер респондента у х, х, 1 Ji хп xiL 2 у z г,а хп п Уп хш хгп Каждое значение переменной в таблице преобразуем по формулам *U-*t. „ . vi-~y Это преобразование называется нормированием переменных. В результате искомое регрессионное уравнение примет вид У = C,Zi + C»Zj. Коэффициенты с4 и сг находятся по следующим формулам; •
1 - ri* Са = с, и с2 называются стандартизированными коэффициентами регрессии. Следовательно, зная коэффициенты корреляции между изучаемыми признаками, можно подсчитать коэффициенты регрессии. Подставим конкретные значения tit из следующей таблицы": у 1 0,556 —0,131 xL 1 —0,027 х% 1 Среднее 31,6 9,0 30,2 Среднее квадратическое от Тогда _ 0,556- (-0,131) (-0,027) _ 0 „ Аналогично сг = —0,12, и уравнение регрессии запишется в виде у = 0,55zt - 0,12z2. Коэффициенты исходного регрессионного уравнения b0, bt и Ъг находятся по формулам h = *i &У (29) Ь, = с2(^-\; (30) Ьо = у — blxl — Ьгхг.
Подставляя сюда данные из вышеприведенной таблицы, получим b, = 3,13; 62 = —0,17; Ь, = 8,56. Как же следует интерпретировать это уравнение? Например, Значение b2 показывает, что в среднем недельный бюджет свободного времени при увеличении возраста на один год и при фиксированном признаке xt уменьшается на 0,17 час. Аналогично интерпретируется bt. (Исходные эмпирические данные можно изобразить на диаграмме рассеяния аналогично тому, как это сделано на рис. 10, но уже в трехмерном пространстве ly, xt, хг).) Коэффициенты bt, 62 можно в то же время рассматривать и как показатели тесноты связи между неременными у и, например, xi при постоянстве Хг. Аналогичную интерпретацию можно применять и к стандартизированным коэффициентам регрессии с(. Однако поскольку с( вычисляются исходя из нормированных переменных, они являются безразмерными и позволяют сравнивать тесноту связи между переменными, измеряемыми в различных единицах. Например, в вышеприведенном примере Xi измеряется в классах, ах» — в годах. c, и С] позволяют сравнить, насколько z» теснее связан с у, Поскольку коэффициенты Ь< и с< измеряют частную одностороннюю связь, возникает необходимость иметь показатель, характеризующий связь в обоих направлениях. Таким показателем является частный коэффициент корреляции г —Vh---- А--- ryl ~ гуггц Для рассматриваемого примера гу1_ х = 0,558, rn. f = —0,140. Для любых трех переменных хи хг, х, частный коэффициент корреляции между двумя из них при элиминировании третьей строится следующий образом: ,_____________ ri2 ~ Г1згаз_________________________________________ /ол\ /(1-гЬ)(1-гЬ) Аналогично можно определить и частные коэффициенты корреляции для большего числа переменных (г12, и..»). Однако ввиду громоздкости вычисления они применяются достаточно редко. Для характеристики степени связи результатирующего признака у с совокупностью независимых переменных служит множественный коэффициент корреляции R%v(i...hh который вычисляется по формуле (иногда он выражается в процентах) 1 -Кх... *>=(!-r»i)(l -г,1, ^...(i -r^.M...(ft_,)). (32)
Так, для вышеприведенного примера он равен Фив =1 - (1 - U) (1 - г*,.,) = 1 - (1 - 0,556') (1 - 0,140*) = = 0,323 (нли ~32%). Множественный коэффициент корреляции показывает, что включение признаков х, и х2 в уравнение j/ = 8,35 + 3,14xl-0,166a:l на 32% объясняет изменчивость результатирующего фактора. Чем больше /?i, тем полнее независимые переменные х,, ..., хк описывают признак у. Обычно R служит критерием включения или исключения новой переменной в регрессионное уравнение. Если R мало изменяется при включении новой переменной в уравнение, то такая переменная отбрасывается. Корреляционное отношение. Наиболее общим показателем связи при любой форме зависимости между переменными является корреляционное отношение г\г. Корреляционное отношение т\у/х определяется через отношение межгрупповой -дисперсии к общей дисперсии по признаку у: _* 2 "vi (Hi ~ уУ ч!*—^т5*-—т*----------------- г (33) 2 ".,(*-•*)' где у~( — среднее значение i-ro у-сечения (средпее призпака у для объектов, у которых х = х,, т. е. столбец «Ы; х{ — среднее значение i-ro аг-сечения (т. е. строка «i»); nVi —число наблюдений в у-сечении; пХ{ — число наблюдений в х-сечении; у — среднее значение у. Величина т)*/х показывает, какая доля изменчивости значепий у обусловлена изменением значения х. В отличие от коэффициента корреляции %/х не является симметричным показателем связи, т. е. tjJ/k ф f\x/u. Аналогично определяется корреляционное отношение х но у ". Пример. По данным таблицы сопряженности (табл. 9) найдем tiJ5/x. Вычислим общую среднюю - 38 ■ 15 + 12 • 25 .- , Тогда « _ 10 (21 - 17,4)3 + 28 (15- 17,4)' + 12 (20- 17,4)' л /< Сравнение статистических показателей г и ц1. Приведем срав-
пительную характеристику коэффициента корреляции (будем сравнивать г*) и корреляционного отношения ц1: а) г* = 0, если х и у независимы (обратное утверждение не б) г2 = Tj*/X = 1 тогда и только тогда, когда имеется строгая ли в) г2 = х\ 1/х < 1 тогда и только тогда, когда регрессия хну стро- г) г2 < г\х/у <Z 1 указывает на то, что нет функциональной зави Таблица 9. Вычисление т)1
Середина интервала х. Середина ин- рт" i n тервала и{ _______________________________________________________________________________ х{ 10 20 | 30 В 38 В 12 пу (0 28 12 7t 21 15 20 50 Коэффициенты взаимозависимости для порядкового уровня измерения. К этой группе относятся коэффициенты ранговой корреляции Спирмена г„ Кендалла т и f. Коэффициенты ранговой корреляции используются для измерения взаимозависимости между качественными признаками, значения которых могут быть упорядоче-иы или проранжированы по степени убывания (или нарастания) данпого качества у исследуемых социальных объектов. Коэффициент ранговой корреляции Спирмена г.. Этот коэффициент вычисляется по следующей формуле:
Пример. По данным табл. 10 выясним, в какой степени связаны жизненные планы детей, отличающихся по социальному происхождению. Для этого проранжируем значения процентных распределений для каждой из двух групп детей. В графе «из крестьян» (табл. 10) встречаются два одинаковых числа (51, 0). В подобных случаях обоим числам присваивают ранг, равный среднему арифметическому из этих рангов, т. е. (3 + 4)/2 = Такую величину г, можно интерпретировать как высокую степень связи между жизненными планами детей рабочих и крестьян. Однако большая величина г, не должна скрывать тот факт, что жизненные планы молодежи в табл. 10 распадаются на две группы. Для одной группы (нижняя часть таблицы) ранги полностью совпадают, а для другой (верхняя часть) — нет. Таблица 10 •
Социальное происхождение Жизненные плавы ------------------------ Ранг I i/Br df <*' Из рабо- иа Чих крестьян Получить высшее образование 57,5 51,0 1 3,5 —2,5 6,25 Получить интересную любимую 57,3 59,0 2 1 11 работу Побывать в других странах 53,8 52,0 3 2 11 Создать себе хорошие жилищные 49,7 51,0 4 3,5 0,5 0,25 условия Добиться хорошего материального 48,5 50,0 5 5 0 0 обеспечения Повысить свою квалификацию 42,0 45,0 6 6 0 0 Получить среднее образование 22,6 32,0 7 7 0 0 Поехать на одну из новостроек 19,4 25,0 8 8 0 0 • Лисовский В. Эскиз к портрету. М., 1969, с. 42. Распределение респондентов в таблице приведено в процентах к численности групп «ив рабочих», «из крестьян» соответственно. Поскольку респонденты могли выбирать при опросе более чем один жизненный план, то сумма по столбцам не равна 100%.
Значимость коэффициента корреляции Спирмена для I < 100 можно определить по табл. Г приложения, где приведены критические величины г,. Если I > 100, то критические значения находятся по табл. А приложения. Наблюдаемые значения критерия вычисляются по
формуле у п — 1 Например, возвращаясь к данным табл. 10, где I < 100, по табл. Г приложения найдем, что для того, чтобы г, был значим на уровне 0,01, он должен быть равен или превосходить 0,833. Эмпирическое значение г, = 0,9, и поэтому делается вывод, что имеется значимая связь между предпочтениями жизненных планов двух групп респондентов. Аналогичным образом легко убедиться, что г, = 0,15 при I = 4 статистически незначим. Коэффициент ранговой корреляции т Кендалла. Подобно г., коэффициент Кендалла используется для измерения взаимосвязи между качественными признаками, характеризующими объекты одной и той же природы, ранжированные по одному и тему же критерию, т изменяется от +1 до —1. Для расчета та используется формула т«" Как вычисляется 5, поясним на примере данных табл. 10. Таблица упорядочена так, что в графе «Ранг I» ранги расположились в порядке возрастания их значений. Берем значение ранга, стоящего в графе «Ранг II» па первом месте, 3,5; из расположенных ниже данного ранга семи других четыре значения его превышают, а два — мепыне его. Число 4 записывается в графу S*, а 2 в колонку «S7'. Аналогичный подсчет делается для второго ранга со значением 1. Число рангов, расположенных ниже данного значения и превышающих его, равно 6, а число рангов, меньших Данного,— 0 и т. д. Остальные вычисления ясны из следующей таблицы: sf s-sf-sr sf s~ s+-s- 4 2 2 3 0 3 5 0 5 10 1
_ 23 _ п Q
Таким образом, т„ дает более осторожную оценку для степени связи Двух признаков, чем г,. При расчете тв не учитывались равные ранги. Например, л табл. 10 имеются два равных ранга со значением 3,5. Если число равных рангов велико, то необходимо вычислить т по следующей формуле; «»°/fl *,, <37> V[-Yi(i-i)-Tx\[-^ni-i)-Tv\ где Тх= l/2H>tx(tx— 1) (£х— число равных рангов по первой переменной); Ту = 1/22 tytty— I) (£„ — число равных рангов по второй, переменной). Для предыдущего примера tx=i, ty = 2, тогда Тх — 0, Г„=1. Значимость коэффициента корреляции Кендалла т„ при I > 10 определяется по формуле Z = Гипотеза о том, что т« = 0, будет отвергнута для данного а, если |Zl>ZBP(a/2). Для вышеприведенного примера z = У -jg--8(8—1)(2,8 + 5) По табл. А приложения для a = 0,05 находим ZKf(a/2), равное 1,96. Поскольку расчетное значение Z = 2,84 и, следовательно, больше ZKP, заключаем с вероятностью 95%, что То^О. Коэффициенты корреляции Спирмена и Кендалла используются как меры взаимозависимости между рядами рангов, а не как меры связи между самими переменными. Так, в табл. 10 ранги отражают иерархию жизненных планов, но совершенно не говорят о том, что дети рабочих почти в равной мере хотят получить как высшее образование, так и интересную работу (разница 0,2%), а дети крестьян в большей степени стремятся к высшему образованию (разница 8%). Кроме того, какая-нибудь из групп респондентов может считать, что выделенные категории вообще не отражают их жизненных планов, но проранжировали предложенные варианты. Если для целей исследования можно предположить эти моменты несущественными, то оправданно применение ранговой корреляции. Коэффициенты Спирмена и Кендалла обладают примерно оди-паковыми свойствами, но т в случае многих рангов, а также при введении дополнительных объектов в ходе исследования имеет определенные вычислительные преимущества2*. Другая мера связи между двумя упорядоченными переменными — у- Она, так же как и предыдущие коэффициенты, изменяется
от +1 до —1 и может быть подсчитана при любом числе связанных рангов. Формула для вычисления f записывается в виде р+___ о— »-lf+^- (39> Для иллюстрации правил вычислепия Sf по сгруппированным данным обратимся к примеру (табл. 11). Таблица 11. Распределение ответивших на вопрос: «Устраивает ли Вас Ваша настоящая работа» — в зависимости от стажа работы в бригаде *
Альтернативы1_____________________ г„м»» ответа I i I ьуияя до 1года | 1—2года 2—5 лет| 5 и более
Не устраивает 78 75 196 67 416
* Данные ив исследования «Формирование трудового коллектива на промышленной предприятии», проведенного ИСИ АН СССР в 1982 г.
S = ____= _____ ___—-. -L. ., ^^^^ —ТТТТ ТТРРГТТТТ + ————— ————- ' 7S [\"Щ\ \\'/Щш I 73 15 \WS 61 IB 75 195 67
S~= тггтттг ттттттт пттттт = + гтттттттт тттптт =------------------- + ттттттт ===----------- '------- 16 15 196 67 76 75 196 67 16 15 196 67 ImiiiHIilninilllhiuillI I Illiiiiilllllnnilli I I Illniiilll I | СХЕМА 2. Схема вычисления 5+ и S- Так: 5+ = 194(75 + 196 + 67) + 146(196 + 67) + 389 • 67 = 130 709, S~ = 119(78 + 75 + 196) + 389(78 + 75) + 146 • 78 = 112 436. Подставляя эти величины в формулу для f, находим •у = Проверку статистической значимости проводят по формуле
Гипотеза На о равенстве нулю коэффициента отвергается, .если Z>ZHp(a/2). Для ваших данных 7_„1 /" Л*+ .9- _ n 07 I/ 130 709 + 112436- _ fl q?, £ - У у „(1-у*> ~ °.°7 К 1264(1-0,07)" - U>y7d' Для a = 0,05 по табл. А приложения ZKP(q./2) = 1,96. Таким образом, Z < ZKV, и, следовательно, у нас нет оснований отвергнуть гипотезу Но: f = 0, т. е. лишь в 5 % случаев следует ожидать, что Т будет отличен от нуля. Множественный коэффициент корреляции W. Этот коэффициент, иногда называемый коэффициентом конкордации, используется для измерения степени согласованности двух или нескольких рядов про-ранжированных значений переменных. Коэффициент W вычисляется по формуле W= где к — число переменных; п — число индивидов или категорий, которые ранжируются; 5=2 (сумма рангов по строке — а)г; а — среднее из суммы рангов. Таблица 12. Вычисление множественного коэффициента ранговой корреляции
Респондент ----------------------- j--------------------- j Сумма рангом ______________ А | Б 1 В________________ 1-й 1 2 1 4 2-й 3 4 5 12 3-й 5 5 4 14 4-й 4 3 3 10 5-й 2 1 2 5
5 = (4-9)г+(12-9)2+(14-9)1 + (10-9)1+(5-9)2 = 76; W - 32-5-(5>-1) U'04- Значимость полученной величины W для п > 7 проверяется по критерию х2- Х2= со степенью свободы п — \. Для примера х2 = Ю)133, степень свободы (и — 1) = 4. Для a = 0,05 из табл. Б приложения находим %2 =• ■= 9,488. Поскольку наблюдаемое значение х* больше критической точки, отвергаем гипотезу о том, что не существует значимой связи между рассматриваемыми переменными30. Коэффициенты взаимозависимости для номинального уровня измерения. Связь в табл. 2X2. Простейшая задача о взаимозависимости возникает тогда, когда имеются два признака, каждый из которых принимает два значения (табл. 13). Таблица 13. Распределение отношения к правилам уличного движения в зависимости от пола
Отношение к правилам уличного __________________________ „ движения в течение месяца, % мужской [ женский_______ Нарушение 20 0 20 Соблюдение 30 50 80
Не А с d с+ d
Для характеристики степени связи двух признаков применяется коэффициент Ф, определяемый формулой Ф ■= ad~hc (42) -]/(а-\-Ь)(а-\-с)(Ь.+ й)(с + й) ' ' Коэффициент Ф равен 0, если нет соответствия между двумя дихотомическими переменными, и равен 1 или —1, когда имеется полное соответствие между ними. В силу трудностей с интерпретацией знака коэффициента для катетеризованных (номинальных) переменных часто используют в анализе лишь абсолютную величину— |Ф|. Ф легко интерпретируется, поскольку показано, что он представляет собой просто коэффициент корреляции г, если значения каждой дихотомической переменной обозначить 0 и 1. Как уже отмечалось, Ф вычисляется для категоризованных данных, представляющих естественные дихотомии: пол, раса, и т. п. Приведение количественных переменных к дихотомическому виду связано с выбором граничной точки разделения (например, мужчины до 30 лет и мужчины старше 30 лет). Искусственная дихотоми-зация, столь часто необходимая в конкретном исследовании при изучении взаимосвязи признаков, может привести к тому, что одна
часть дихотомической переменной по своему воздействию будет более значима для одной связи, другая — для другой, а это даст ошибочный результат. Измерение связи в табл. с X к. Рассмотрим теперь более общую ситуацию, когда две переменные классифицированы на две или более категории. Запишем это таким образом; пп nit... nlh nt. ncl nci ... nck nc. n.\ re. j ... w.ft n где Пц частоты; nt. — маргинальные суммы частот по строкам; n.j — маргинальные суммы частот по столбцам. На с. 169—172 для выяснения отклонения от независимости распределения значений в подобном случае использовался критерий /2. Однако сама величина X2 не очень подходит в качестве меры связи, поскольку сильно зависит от числа категорий. Нормированным коэффициентом корреляции для таблицы с X к является коэффициент сопряженности Пирсона (Р); 
Не нашли, что искали? Воспользуйтесь поиском по сайту: ©2015 - 2026 stydopedia.ru Все материалы защищены законодательством РФ.
|
 25 В действительности эти регрессионные уравнения всегда являются лишь
25 В действительности эти регрессионные уравнения всегда являются лишь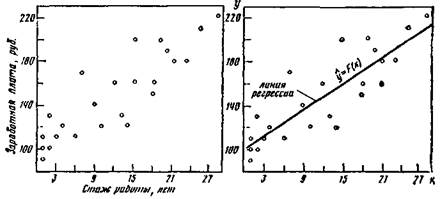
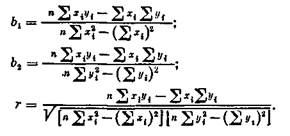
 где a» — отклопепие от условной средней по признаку х; а, — откло-Таблица 8. Вычисление г по сгруппированным данным
где a» — отклопепие от условной средней по признаку х; а, — откло-Таблица 8. Вычисление г по сгруппированным данным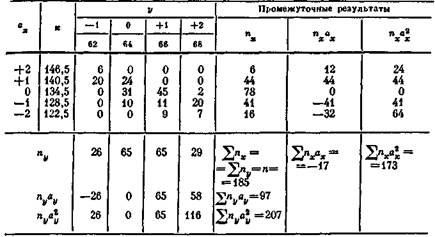
 ^fl.r6gy4= 7[(-2)(+2)I = -28
^fl.r6gy4= 7[(-2)(+2)I = -28 sz = У173/185-(-0,09)г = 0,90,
sz = У173/185-(-0,09)г = 0,90, «„ = У207/185-(0,52)2 = 0,92. В соответствии с формулой вычисляем — 129—185 (-0,09) -0,52 = _ л 73
«„ = У207/185-(0,52)2 = 0,92. В соответствии с формулой вычисляем — 129—185 (-0,09) -0,52 = _ л 73 1Ь Численные данные взяты из книги «Методика и техника статистической обработки первичной социологической информации» (М., 1968, с, 182),
1Ь Численные данные взяты из книги «Методика и техника статистической обработки первичной социологической информации» (М., 1968, с, 182), * Стандартизированные коэффициенты регрессии с< находят также широкое применение при интерпретации так называемых причинных диаграмм. (См.: Статистические методы анализа информации всоциологических исследованиях. М., 1979, гл, 15),
* Стандартизированные коэффициенты регрессии с< находят также широкое применение при интерпретации так называемых причинных диаграмм. (См.: Статистические методы анализа информации всоциологических исследованиях. М., 1979, гл, 15), 27 Другие более сложные примеры вычисления t)2 см.: Статистические методы аиализа информации в социологических исследованиях, с. 102.
27 Другие более сложные примеры вычисления t)2 см.: Статистические методы аиализа информации в социологических исследованиях, с. 102. тде di = i — kl — разность между i-ми парами рангов; I — число сопоставляемых пар рангов. Величина г, может изменяться в пределах от +1 до —1, когда два ряда проранжировапы в одном порядке. При полном взаимном беспорядочном расположении рангов г, равен нулю.
тде di = i — kl — разность между i-ми парами рангов; I — число сопоставляемых пар рангов. Величина г, может изменяться в пределах от +1 до —1, когда два ряда проранжировапы в одном порядке. При полном взаимном беспорядочном расположении рангов г, равен нулю. Если подсчитать г, для каждой группы отдельно, то в первом случае, очевидно, г, — 1, а во втором г, = 0,15, по статистически незначимо отличается от 0.
Если подсчитать г, для каждой группы отдельно, то в первом случае, очевидно, г, — 1, а во втором г, = 0,15, по статистически незначимо отличается от 0. 28 Если при рапжировании возникает иного одинаковых (или, как говорят, связанных) рангов, то формула (34) неприменима,
28 Если при рапжировании возникает иного одинаковых (или, как говорят, связанных) рангов, то формула (34) неприменима, Тогда, подставив соответствующие значения в формулу (36), получим
Тогда, подставив соответствующие значения в формулу (36), получим • ~ >/,-8(8-1) ~ ' '
• ~ >/,-8(8-1) ~ ' ' Стаж работы
Стаж работы Устраивает 194 146 389 119 848
Устраивает 194 146 389 119 848 Сумма | 272 | 221 | 585 | 186 | 1264
Сумма | 272 | 221 | 585 | 186 | 1264 Процесс вычисления S+ и 5" наглядно представлен на схеме (схема 2).
Процесс вычисления S+ и 5" наглядно представлен на схеме (схема 2).
 + ктй т I w I m I I m kivsj звз \ w | | w \ rvs \ЩЩ m
+ ктй т I w I m I I m kivsj звз \ w | | w \ rvs \ЩЩ m



 194 I 146 I 339 kflffe I 194 I 146 ^Ж=1 119 1 I 194 %146U3B9 I 119
194 I 146 I 339 kflffe I 194 I 146 ^Ж=1 119 1 I 194 %146U3B9 I 119 Z-yV n(l-v') '
Z-yV n(l-v') ' Удовлетворенность по признакам А, Б, В
Удовлетворенность по признакам А, Б, В
 я = 5 2 = 45
я = 5 2 = 45 Для данных табл. 12 а = 45/5 = 9;
Для данных табл. 12 а = 45/5 = 9; Пол
Пол Всего 50 50 100
Всего 50 50 100 Представим данные о группировке по этим двум признакам так:
Представим данные о группировке по этим двум признакам так: А а Ъ а+Ь
А а Ъ а+Ь Сумма | а+с b+d \ п(либо 100%)
Сумма | а+с b+d \ п(либо 100%) * Более подробные сведения об обработке ранжировапных данных см.: ГОСТ 23554.2—81. Экспертные методы оценки качества промышленной продукции, М., 1982.
* Более подробные сведения об обработке ранжировапных данных см.: ГОСТ 23554.2—81. Экспертные методы оценки качества промышленной продукции, М., 1982.