
|
|
Сравнение двух выборок по характеру распределенияРассмотренные выше методы сравнения двух выборок проверяют предположение либо о действии систематического, контролируемого, фактора (по критерию Стьюдента оценивается различие средних), либо о действии разного набора случайных факторов (критерий Фишера пытается обнаружить отличие дисперсий), либо обеих причин вместе (с помощью непараметрических статистик). Специфические методы χ² Пирсона и λ Колмогорова – Смирнова позволяют проверять гипотезы о соответствии друг другу двух частотных распределений и тем самым улавливать не только отличия в общих тенденциях, но и частные особенности отдельных классов вариант.
Критерий χ² Пирсона
Критерий позволяет выяснить, насколько полученный экспериментатором фактический материал подтверждает теоретическое предположение, в какой мере анализируемые данные совпадают с теоретически ожидаемыми. Возникает задача статистической оценки разницы между фактическим и теоретическим распределениями. С формальных позиций сравниваются два вариационных ряда, две выборки: одна – эмпирическое распределение, другая представляет собой выборку с теми же параметрами (n, M, S и др.), что и эмпирическая, но ее частотное распределение построено в точном соответствии с выбранным теоретическим законом (нормальным, Пуассона, биномиальным и др.), которому предположительно подчиняется поведение изучаемой случайной величины. Нулевая гипотеза предполагает отсутствие различий между сравниваемыми распределениями. Для ее проверки и служит "критерий согласия" χ² Пирсона:
где a — фактическая частота наблюдений, A — теоретически ожидаемая частота для данного класса. Расчетное значение критерия сравнивают с критическим значением для принятых уровня значимости (α) и числа степеней свободы (df) (табл. 9П). Если вычисленная величина χ2 равна или превышает табличную χ²(α, df), решают, что эмпирическое распределение от теоретического отличается достоверно. Тем самым гипотеза об отсутствии этих различий будет опровергнута. Если же χ² < χ²(α, df), нулевая гипотеза остается в силе. Обычно принято считать допустимым уровень значимости α = 0.05, так как в этом случае остается только 5% шансов, что нулевая гипотеза правильна и, следовательно, есть достаточно оснований (95%), чтобы от нее отказаться. Как и раньше, для определения числа степеней свободы из общего объема выборки нужно вычесть число ограничений (т. е. число параметров, использованных для расчета теоретических частот). Однако необходимо помнить, что в случае с критерием хи-квадрат для определения числа степеней свободы используют не объем выборки n, а число классов частотного распределения k. Для альтернативного распределения (k = 2) в расчетах участвует только один параметр, объем выборки, следовательно, число для него df = k–1 = 2–1 = 1. Для проверки равномерности распределения результатов дигибридного скрещивания (известно четыре класса) df = k–1 = 4–1 = 3. Для проверки соответствия вариационного ряда распределению Пуассона используются уже два параметра – объем выборки и среднее значение (численно совпадающее с дисперсией); число степеней свободы df = k–2. При проверке соответствия эмпирического распределения вариант нормальному или биномиальному закону число степеней свободы берется как число фактических классов минус три условия построения рядов – объем выборки, средняя и дисперсия, df = k–3. Сразу стоит отметить, что критерий χ² работает только для выборок объемом не менее 25 вариант, а частоты отдельных классов должны быть не ниже 4. Общий порядок работы таков. Сначала строится вариационный ряд, т. е. частотное (a) распределение для фактических данных. Затем формулируются теоретические соображения о том, какой тип распределения реализуется в изучаемой совокупности. В соответствии с этим выдвигается нулевая гипотеза: "эмпирические частоты соответствуют данному типу распределения" или, что то же самое, "в генеральной совокупности реализован такой-то тип распределения". На следующем этапе формируется "теоретическая выборка". Для этого, во-первых, требуется явно вычислить теоретические частости (p), соответствующие значениям вариационного ряда. Пожалуй, это самый ответственный момент всех расчетов, поскольку ранее высказанная идея воплощается в числа – теоретические частости данного значения. После этого рассчитываются частоты распределения выбранного теоретического типа (A) для конкретных параметров исходной выборки. Завершается процедура расчетом величины критерия хи-квадрат (χ²), ее сопоставлением с табличным значением (χ²(α, df)). В итоге формулируется статистический вывод о соответствии или не соответствии эмпирических рядов теоретическому распределению. Это дает возможность прийти к тому или иному биологическому заключению. В качестве первого примера решим задачу, соответствует ли закону Пуассонараспределение числа повторных отловов альбатросов (табл. 6.4). В этом случае рассматривается процесс, этапами которого выступают события "отлов птицы". В чреде таких событий встречаются редкие – "отлов меченной особи". Биологическая подоплека состоит в следующем: случайны ли повторные отловы птиц, или есть факторы, ответственные за нарушение случайности? Например, птицы могут приманиваться и стремиться попасть вновь либо могут стараться избежать повторного отлова. В обоих случаях птицы буду "умышленно" попадаться чаще или реже, нарушая случайность повторного отлова и искажая тем самым форму распределения, которое будет отходить от формы, предписанной законом Пуассона. Согласно нулевой гипотезе, птицы ведут себя случайно, их встречаемость соответствует этому закону. Алгоритм расчетов теоретических частот для распределения Пуассона достаточно прост и основан на формулах, не требующих предварительного расчета теоретических частостей p:
где М – средняя арифметическая ряда, x – значение ряда (число объектов в пробе), Ax – теоретическая частота значения x, n – объем выборки (число проб), e = 2.7183…– основание натурального логарифма. Параметры данного вариационного ряда были рассчитаны в разделе Основные типы распределений: M = 0.968. Теоретическая частота нулевого значения равна:
Таблица 6.4
частота значения x = 1:
и т. д. (табл. 6.4, графа 3). По окончании вычислений получаем два ряда частот, отличия между которыми оцениваются по критерию хи-квадрат. Перед расчетом значения критерия следует убедиться, что выполнены требования к данным для расчета критерия χ²: – объем выборки более 25 вариант, n>25, – суммы эмпирических и теоретических частот равны объему выборки n = Σa = ΣA (с точностью не ниже 1–2%), – все классы эмпирического и теоретического рядов имеют частоты более 4, aj>4; если какие-либо классы имеют меньше 4 вариант (у нас значения 3 и 4 имею частоты 2 и 1), то они должны быть объединены (суммированы) с соседними, что и показано в таблице с помощью фигурных скобок. Далее вычисляем значения критерия: для первой строки
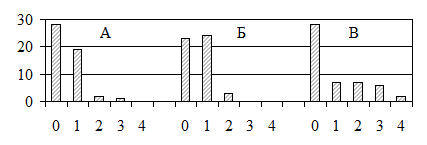
и т. д. (графа 4), итого χ² = 2.31. Число степеней свободы находим как число окончательных классов (3) минус число ограничений (средняя и объем выборки): df = k–2 = 3–2 = 1. Табличное значение χ²(0.05,1) = 3.84. Полученная величина (2.31) меньше табличной (3.84), следовательно, нулевая гипотеза не отвергается: эмпирическое распределение достоверно не отличается от распределения Пуассона. Иными словами, у нас нет оснований утверждать, что вероятность повторного отлова изменяется: нельзя утверждать, что операция отлова птиц привлекает или пугает. Кстати, соответствие эмпирического ряда распределению Пуассона можно проверить и другим способом: сравнив по критерию Фишера величины средней арифметической и дисперсии для числа степеней свободы df1 = n–1, df2 = n–1. В нашем случае M = 0.968, S² = 1.257; F = 1.257/0.968 = 1.157. Поскольку эта величина меньше табличной (F(0.05,31,31) = 1.84), сравниваемые показатели достоверно не отличаются, а равенство средней и дисперсии характерно лишь для распределения Пуассона. В качестве второго примера рассмотрим анализ пространственного размещения особей. Как известно, есть три важнейших типа размещения: регулярное (соответствующее жестким конкурентным отношениям), агрегированное (скученность особей вблизи от источников необходимых ресурсов) и случайное (когда нет острой конкуренции или дефицита ресурсов). Зная тип размещения особей, можно многое сказать об их биологии. Судить о характере пространственного размещения можно по распределению встреч особей по небольшим одинаковым пробным площадкам, на которые разбивается исследуемая территория (рис. 6.2). Равномерное территориальное размещение особей дает унимодальное распределение встреч (одна вершина повышенных частот) (рис. 6.2, В). Если наблюдается агрегация, имеет место бимодальное распределение (много площадок без особей, много площадок с несколькими особями и мало площадок с единичными экземплярами) (рис. 6.2, Б). Когда же размещение животных или растений по территории местообитания случайно, при обобщении получается частотное распределение Пуассона (рис.6.2, А). Поэтому, проверяя соответствует ли этому закону эмпирическое распределение особей по площадкам, мы тем самым проверяем гипотезу о случайном размещении организмов в пространстве. Возьмемся проверить, действительно ли на иллюстрации "случайное размещение" из монографии А. М. Гилярова (1990, с. 41, рис. 8) точки размещены случайно? Разбиваем территорию на пробные площади, нарисовав сетку. Подсчитываем число площадок (a), на которых встретилось разное число точек (x), формируем вариационный ряд (табл. 6.5).
Рис. 6.2. Территориальное размещение особей и соответствующие распределения Таблица 6.5
Определяем объем выборки (n = 50), среднюю арифметическую (M = 0.52). Предполагая распределение Пуассона, рассчитываем по алгоритму теоретические частоты (A), объединяем классы, где частоты меньше 4, вычисляем χ², отыскиваем табличное значение χ²(0.05,1) = 3.84. Поскольку полученное значение критерия (5.99) больше табличного (3.84), эмпирическое распределение отличается от распределения Пуассона. На иллюстрации отображено не случайное размещение особей в пространстве, поскольку пустых площадок слишком мало, а единичных слишком много; размещение точек тяготеет к агрегированному. Такому типу лучше соответствует биномиальное распределение с неравными вероятностями исходов. Теория статистического оценивания строится на идее нормального распределения. Многие из параметров и критериев предлагаются ею в предположении, что изучаемые признаки имеют нормальное распределение. По большому счету, используя статистические методы для описания непрерывных признаков, нужно быть уверенным, что они действительно подчиняются нормальному закону, а в случае дискретных признаков – биномиальному. Для такой проверки нулевая гипотеза звучит так: "полученное распределение соответствует нормальному (биномиальному)" или "выборка взята из генеральной совокупности, подчиняющейся закону нормального (биномиального) распределения". Все вычислительные операции для случаев нормального и биномиального распределений совпадают. Рассмотрим проверку на не-нормальность распределения массы тела бурозубок. Расчеты начинаются с построения вариационного ряда и поиска центральных значений для каждого класса (табл. 6.6 и 6.7). Далее по формуле А = с∙p, где p – ординаты нормальной кривой; с – константа ряда, определяемая по формуле dx – классовый интервал (в данном случае он равен 0.7); п – объем выборки (63). Для нашего примера Теоретическая частота для f = 0.15 составит: А = 49.16∙0.1539 = 7.55 ≈ 8 (графа 6). В результате вычислений получаем теоретическую выборку с параметрами M = 9.29 г, S = 0.897 г, п = 63,частоты которой соответствуют нормальному распределению (см. рис. 3.3, с. 63). Таблица 6.6
Теперь остается оценить отличия частот обоих рядов по критерию хи-квадрат. Но перед этим необходимо убедиться в совпадении суммы эмпирических и теоретических частот (по 63 варианты) и в том, что минимальная частота в отдельных классах обоих рядов не ниже 4. Поскольку в крайних классах частоты были ниже, проводим их объединение (отмечено скобками), после чего число классов снизилось до k = 5. Далее вычисляем критерий хи-квадрат: для первого касса (9–10)²/10 = 0.1. Значение критерия составило χ² = 1.36. Число степеней свободы (при трех ограничениях и пяти классах) равно df = 5–3 = 2. Табличное значение (табл. 9П) χ²(0.05,2) = 5.99. Поскольку полученное значение (1.36) меньше табличного (5.99), нулевая гипотеза сохраняется, распределение бурозубок по массе тела достоверно от нормального не отличается. Аналогичные расчеты для дискретного признака (плодовитость лисиц), имеющего предположительно биномиальное распределение(дискретный аналог нормального), представлены в табл. 6.7. Так, при параметрах M = 5 экз., S = 1.33 экз. для второго интервала получаем: t = |8–5|/1.33 = 1.5. Таблица 6.7
Соответствующая ордината нормальной кривой равна p = 0.1295 (графа 4), теоретическая частота составит: А = с∙p = 56.38∙0.1295 = 7.3 ≈ 7 (графа 5), поскольку значение c = 1∙75/1.33 = 56.38. В результате вычислений получаем частоты (A) распределения (с параметрами М = 5, S = 1.33, n = 75), строго соответствующего биномиальному (см. рис. 3.4, с. 69). Объединим классы с частотами менее 4 и рассчитаем значение критерия χ² = 2. Число степеней свободы (при трех ограничениях и пяти классах) равно df = 5–3 = 2. Поскольку это значение (χ² = 2) меньше критического табличного (χ2(0.05,2) = 5.99), нулевая гипотеза не может быть отклонена, значит, распределение лисиц по плодовитости достоверно от биномиального не отличается. В рассмотренных примерах проводилась проверка соответствия эмпирического распределения тому или иному типу распределения, заданному статистическим законом. На основании этого закона и рассчитывались ожидаемые частости p. Однако, метод χ² позволяет проверять гипотезы, диктуемые не только формальными статистическими законами, но и содержательными (биологическими) соображениями. Основанием для подобных гипотез могут быть биологические законы расщепления признаков в гибридных поколениях, представленность морф, соотношение разнополых и разновозрастных групп в популяции, соотношения видов в ценозах и пр. Таким случаям соответствуют признаки с альтернативным и полиномиальным распределением. Для расчета теоретически ожидаемых частостей p используются идея о полной группе событий (сумма частостей для всех возможных событий равна 1) и содержательные соображения. Рассмотрим применение критерия хи-квадрат при анализе альтернативной изменчивости. В одном из опытов по изучению наследственности у томатов было обнаружено 3629 красных и 1176 желтых плодов. Теоретическое соотношение частот при расщеплении признаков во втором гибридном поколении должно быть 3:1 (75% к 25% или в долях: p1 = 0.75 p2 = 0.25). Выполняется ли оно? Иными словами, взята ли данная выборка из той генеральной совокупности, в которой соотношение частот 3:1? Для того чтобы это проверить, сформируем уже знакомую таблицу (табл. 6.8), заполнение которой аналогично рассмотренным, только для расчета теоретической частоты используется формула: А = n∙p, где p – теоретические частости; n – объем выборки. Например, A2 = n∙p2 = 4805∙0.25 = 1201.25 ≈ 1201. Таблица 6.8
Далее вычисляем хи-квадрат: χ² = 0.71 и число степеней свободы (при двух классах и одном ограничении, объеме выборки) df = k–1 = 2–1 = 1. По табл. 9П находим критическое значение χ²(0.05,1) = 3.84. Поскольку полученная величина (0.71) меньше табличной (3.84), различия сравниваемых распределений статистически недостоверны. Иначе говоря, фактические частоты хорошо согласуются с теоретически ожидаемыми. По данным первой строки таблицы видно, что полученное значение χ2 соответствует уровню значимости большей α = 0.30 (напомним, что порогом, как было установлено выше, является α = 0.05). Значит, совпадение между фактическими результатами и ожидаемыми достаточно велико. Полученные данные не отвергают принятую гипотезу о том, что в нашем случае имеется отношение 3:1. Здесь следует еще раз обратить внимание читателей на то обстоятельство, что сохранение нулевой гипотезы нельзя считать доказательством справедливости нулевой гипотезы. Результатами представленных вычислений теория о расщеплении по фенотипам в отношении 3:1 (0.75:0.25) не доказана, хотя и не опровергнута. Статистика доказывает только факт отличий, но не их отсутствие. Чтобы доказать теорию, нужно предположить анти-теорию (для нашего примера соотношение 1:1) и опровергнуть ее с помощью статистических приемов. На лекциях по биометрии для биофака присутствуют 64 студентки и 12 студентов. Требуется определить, подтверждают ли эти данные факт преобладания на биофаке девушек или налицо просто случайное отличие цифр. Теоретическое отношение признаков, т. е. соотношение полов в популяции людей студенческого возраста, 1:1. Подтверждается ли оно? Иными словами, выдвигается нулевая гипотеза, что данная выборка взята из генеральной совокупности, в которой соотношение полов 1:1. Таблица 6.9
Сравнение вычисленного (35.6) и критического значений (χ²(0.05,1) = 3.84) явно свидетельствует о существенном отклонении фактического соотношения полов от гипотезы – 1:1. Вероятность правильности нулевой гипотезы (т. е. что в данном случае действительно имеет место численное равенство полов) оказалась много меньше 0.01. Соответственно, доверительная вероятность, т. е. вероятность несоответствия между числом девушек и юношей, составляет более 0.99, т. е. достаточно велика. Итак, есть все основания говорить о статистически достоверном преобладании девушек среди студентов биофака. Из какой же генеральной совокупности они отбираются, если достоверно не из той, где Ж:М = 1:1? Видимо, речь идет о группе людей гуманитарно-эстетического душевного склада, для которых созерцательность предпочтительнее предметной деятельности. Понятно, что среди парней таких немного. Принципы исследования полиномиальных распределений остаются прежними, возрастает число классов и степеней свободы. Метод хи-квадрат позволяет сравнивать между собой не только теоретический и фактический ряды данных, но пару (и более) эмпирических выборок. Для ее решения эмпирические частоты каждого ряда сопоставляются со средними теоретическими частотами, рассчитанными на основе нулевой гипотезы "все выборки взяты из одной и той же генеральной совокупности", т. е. "все распределения одинаковы", или "доли вариант с данным значением в разных распределениях одинаковы". Этим методом можно сравнивать между собой признаки, имеющие любые типы распределения. Фактические данные наблюдений группируются в таблицу (a), далее рассчитываются средние теоретические частости (p), затем теоретические частоты (A) и критерий χ². Рассмотрим алгоритм на примере изучения фенетической структуры популяций красной полевки с разным уровнем численности зверьков. Получены частоты встречаемости пяти комплексов фенов от 1 до 5 (признаки: число перфораций черепа в разных областях). Например, первым комплексом фенов обладали 146 особей из первой популяции и 208 из второй (табл. 6.10). Выдвинуто предположение, что различия в частотах фенов случайны. В соответствии с этим допущением частости фенов каждого из пяти типов в двух сравниваемых популяциях должны быть равны. Сначала определяем усредненные (теоретические) частости (pi) для всех фенетических комплексов, поделив суммы особей в группах (Σi) на объединенный объем выборок (N = 600): pi = Σi/N. Так, для второй группы фенов: p2 = 190/600 = 0.317. Таблица 6.10
Далее находим частоты всех фенов с поправкой на разные объемы выборок. Общая формула для вычисления усредненных частот, как и раньше, имеет вид: Аji = nj∙pi, где Аji – теоретическая частота для i-го значения j-й выборки, pi – теоретические (усредненные) частости, nj – объем выборки. Усредненные (теоретические) частоты представлены в таблице 6.10 справа внизу от реальных значений частот. Например, ожидаемая частота второй группы во второй выборке составит A2,2 = 0.317∙312 = 98.8, для пятой группы – A2,5 = 0.008∙312 = 2.6. Критерий хи-квадрат вычисляется по обычной формуле. При этом отыскиваются разности только между эмпирическими и теоретическими частотами для каждой выборки отдельно. Например, для первого класса первой выборки имеем:
В завершение значения χ², полученные для разных выборок, складываются. В нашем случае χ² = 10.9+9.87 = 20.8. Расчет числа степеней свободы производится по формуле df = (k–1)∙(r–1), где k – число значений (классов) вариант, в данном случае 5 классов фенов, r – число сравниваемых выборок, в нашем примере их две. Отсюда df = (5–1)(2–1) = 4. Табличное значение χ²(0.05,4) = 16.92. То, что фактическая величина (20.8) больше табличной, позволяет отвергнуть нулевую гипотезу и сделать вывод о том, что частота (распределение) фенов в сравниваемых популяциях достоверно отличается, причем в основном за счет встречаемости первых двух групп фенов. Отмеченные различия обусловлены увеличением фенетического (генетического) разнообразия первой популяции, отличавшейся более высокой численностью. 
Не нашли, что искали? Воспользуйтесь поиском по сайту: ©2015 - 2026 stydopedia.ru Все материалы защищены законодательством РФ.
|
 ,
, (частота нулевого класса),
(частота нулевого класса), (частота прочих классов),
(частота прочих классов), = 11.93803 ≈ 12,
= 11.93803 ≈ 12,
 7
7
 = 11.55602 ≈ 11
= 11.55602 ≈ 11

 19
19
 вычисляются нормированные отклонения середины каждого классового интервала (xj) от общей средней M (S – стандартное отклонение). В нашем случае M = 9.29 г, S = 0.897 г. Для второго интервала имеет: t = |8.05–9.27|/0.897 = 1.38. Далее определяем теоретические частости нормального распределения, или ординаты нормальной кривой (табл. 4П), соответствующие вычисленным нормированным отклонениям. Для t = 1.38 находим p = 0.1539 ≈ 0.15 (табл. 6.6, графа 5). (Следует отметить, что модуль в формуле нормированных отклонений берется потому, что в таблице 6П приведены частости p только для положительных значений t.) Следующая операция, вычисление теоретических частот распределения, ведется по формуле:
вычисляются нормированные отклонения середины каждого классового интервала (xj) от общей средней M (S – стандартное отклонение). В нашем случае M = 9.29 г, S = 0.897 г. Для второго интервала имеет: t = |8.05–9.27|/0.897 = 1.38. Далее определяем теоретические частости нормального распределения, или ординаты нормальной кривой (табл. 4П), соответствующие вычисленным нормированным отклонениям. Для t = 1.38 находим p = 0.1539 ≈ 0.15 (табл. 6.6, графа 5). (Следует отметить, что модуль в формуле нормированных отклонений берется потому, что в таблице 6П приведены частости p только для положительных значений t.) Следующая операция, вычисление теоретических частот распределения, ведется по формуле: ,
, = 49.16.
= 49.16.
 2
2

 1
1


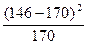 = 3.39.
= 3.39.