
|
|
Логико-теоретические основы
Модель двухфакторного дисперсионного анализа становится сложнее и выражает отклонение варианты (xi) от общей средней (M) за счет действия двух контролируемых факторов порознь (xфактA., xфактB.) и совместно (xсочетAB.), а также за счет действия случайных причин (xслуч.): xi = M ± xфактA. ± xфактB. ± xсочетAB. ± xслуч.. Правило разложения вариаций предстает как: Собщ. = СA + СB + СAB + Сслуч. , Сфакт. = Собщ. – Сслуч. = СA + СB + СAB, где Собщ. = Σ(xi – M)², СA. = Σ(MAj – M)², j – число градаций фактора А, СB = Σ(MBk – M)², k – число градаций фактора В, Сслуч. = Σ(xi – Mxi)², СAB = Собщ. – (СA + СB + Сслуч.).
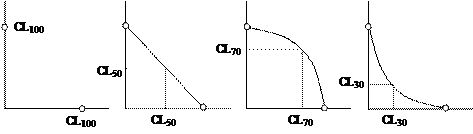
Сочетанное действие (взаимодействие) факторов означает, что каждый из них помимо прямого воздействия на объект исследования сказывается и на характере влияния на объект и другого фактора, усиливает или ослабляет его. К примеру, неурожай кормов усугубляет негативное действие зимнего холода на численность популяций мелких млекопитающих. Выделяют три основных вида взаимодействия факторов: – аддитивное, когда взаимодействия факторов нет, их эффекты просто складываются, – антагонизм, когда один фактор ослабляет действие другого, и наоборот, – синергизм, когда наблюдается усиление действия обоих факторов. Эти эффекты часто встречаются в практике токсикологических исследований. Рассмотрим гипотетические примеры действия на подопытных животных двух веществ, взятых в разных концентрациях. По осям OX и OY диаграммы отложены концентрации этих веществ в диапазоне от 0 до CL50, которые за время опыта вызывают гибель 50% особей (рис. 7.2). Первая иллюстрация показывает точки на осях, в которых концентрации вещества [A] = 0 и [B] = CL50 = ВCL50, а наблюдаемая гибель составляет 50% особей, то же наблюдается для вещества [A] = CL50 = ACL50 и [B] = 0. Аддитивное действие – простое сложение влияний. Прямая, соединяющая точки [A] = CL50 = ACL50, [B] = CL50 = ВCL50, есть множество опытов, в которых токсиканты ведут себя по отношению друг к другу как одно и то же вещество, поскольку эффекты от их доз просто суммируются. Так, половинные по эффекту дозы ACL50/2 и BCL50/2 в сумме дают одну "полноценную" совместную CL50. Однако важно отметить, что пропорциональность эффектов разных веществ вовсе не означает пропорциональности их концентраций. А основа аддитивизм антагонизм синергизм
В
Рис. 7.2. Виды взаимодействия веществ Антагонизм – подавление вредного действия одного вещества другим. Любая точка на выгнутой кривой свидетельствует о том, что для достижения эффекта CL50 требуется взять дозы, которые в сумме должны бы превышать эффект CL50. Например, эффект CL50 в точке 1 достигается суммой 0.7∙ACL50 + 0.7∙BCL50. Чисто арифметически (аддитивно) эффект должен был составить 1.4∙CL50, т. е. 70% гибели тест-объектов. Синергизм – усиление действия. Точки на вогнутой кривой соответствуют ситуации, когда для достижения эффекта CL50 можно взять дозы, суммы которых аддитивно меньше CL50. Так, эффект CL50 обнаруживается в точке для суммы 0.4∙ACL50 + 0.4∙BCL50. Аддитивный эффект должен был составить 0.8∙CL50, т. е. 40% гибели организмов, но синергизм обеспечивает гибель 50% особей. Сочетанное действие факторов нельзя смешивать с корреляцией факторов. Взаимодействие осуществляется "внутри" объекта исследования и связано со спецификой реакции биосистемы, а корреляция реализуется "снаружи" и связана как с природой фактора, так и со способом организации наблюдений. Чтобы выявить эффект именно взаимодействия, изучаемые факторы должны быть, по возможности, независимы друг от друга. Кроме этого, имеется ряд условий правильного применения данного метода. Так, дисперсионному комплексу необходима полнота, т. е. второй фактор (В) должен быть представлен в каждой градации первого фактора (А) одинаковым числом градаций. Ниже рассмотрены алгоритмы, относящиеся лишь к равномерным комплексам, характеризующимся равной численностью групп (в градациях содержатся одинаковое число вариант). Что же касается неравномерных многофакторных комплексов, то их анализ принципиально возможен, но имеет свои особенности, существенно усложняющие технику вычислений. Если исходные данные представлены по градациям неравномерно, вполне допустимо искусственное превращение их в равномерные комплексы. Для этого нужно составить выборки одинаковой величины, используя часть имеющихся данных. Следует помнить, что такой отбор должен быть не субъективным, но случайным. При организации случайного отбора вариант лучше всего прибегнуть к жеребьевке. Например, убирать из выборки те варианты, номера которых совпадают со значениями случайных чисел (табл. 3П). Отбросив часть вариант, мы лишаемся и части информации о варьировании признаков; избежать неправильных выводов, вызванных методикой формирования выборок, помогает многократный пересчет по схеме дисперсионного анализа с использованием результатов нескольких жеребьевок. Ограниченные рамки настоящего краткого руководства не позволяют остановиться на этом вопросе более подробно, поэтому мы отсылаем заинтересованного читателя к специальным пособиям, где техника дисперсионного анализа неравномерных многофакторных комплексов изложена с исчерпывающей полнотой. Условием эффективности многофакторного анализа является также выбор схемы организации факторов в градации. Выше был рассмотрен дисперсионный анализ массива данных с повторностями в каждой градации, для которого разложение суммы квадратов соответствует выражению Собщ. = СA + СB + СAB + Сслуч. (табл. 7.6).
Таблица 7.6 Двухфакторный дисперсионный комплекс:c градаций фактора А (столбцы) и r градаций фактора В (ряды) с n повторениями в каждой градации (l = 1, 2,…, r; j = 1, 2,…, c; i = 1, 2,…, n)
Однако простейшей структурой дисперсионного анализа служит таблица, поля и графы которой характеризуют градации действия двух факторов, а в каждой ячейке содержится лишь одно значение результативного признака (табл. 7.7).
Таблица 7.7 Дисперсионный комплекс для трех градаций без повторений
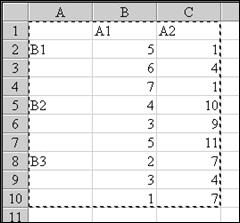
Комплексы без повторений в градациях упрощают не только алгоритм обработки, но, к сожалению, и результаты. Сумма квадратов разлагается только на следующие компоненты: Собщ. = СA + СB + Состат., эффект сочетанного действия становится неотличим от случайного варьирования (Состат. = СAB + Сслуч.). Техника расчетов Рассмотрим конкретный пример – испытания стимулятора многоплодия при разной полноценности рационов. Полноценность рациона (первый фактор) представлена двумя градациями: A1– рацион с недостатком минеральных веществ, А2 – рацион, полностью сбалансированный по всем питательным веществам, включая и минеральные. Стимулятор (второй фактор) был испытан в трех дозах: В1 – одинарная, В2 – двойная, В3 – тройная. Результативный признак – плодовитость самок, измерявшаяся числом детенышей в помете. Для каждого сочетания градаций рациона и стимулятора были подобраны три одновозрастные самки. Комбинативная таблица двухфакторного равномерного дисперсионного комплекса с трехкратной повторностью (ni = 3) включает две градации по фактору А и три градации по фактору В (табл. 7.8). Варианты размещаются по градациям, определяется объем градации, вычисляются суммы вариант, частные средние, затем вспомогательные величины (Н1, Н2, Н3, НА, НВ) и суммы квадратов отклонений (дисперсий) по рабочим формулам. В завершение всего заполняют таблицу дисперсионного анализа (табл. 7.9), находят показатель достоверности влияния Фишера и, сопоставляя его с табличным для соответствующих степеней свободы и принятого уровня значимости, делают статистический вывод. Таблица 7.8
В нашем примере все факториальные влияния оказались достоверными с доверительной вероятностью Р>0.95. Это позволяет сделать определенные выводы относительно действия стимулятора на плодовитость самок. Влияние каждого фактора в отдельности (качества рациона и дозы стимулятора) и их суммарного эффекта достаточно существенно, но особенно результативно действие стимулятора в сочетании с полноценным рационом (величина η²АВ выше, чем η²А и η²В). Более того, при недостатке в корме минеральных веществ двукратные и трехкратные дозы стимулятора могут даже снизить плодовитость животных. Таблица 7.9
Таблица двухфакторного дисперсионного анализа имеет ту же структуру, что и таблица для однофакторного анализа, только факториальная дисперсия разложена на три компоненты (для факторов А, В и их взаимодействия). Для каждой из них требуется вычислить число степеней свободы с учетом числа градаций фактора А (c, количество столбцов) и числа градаций фактора В (r, количество рядов), значения дисперсий, а также критерий Фишера. Поскольку каждому из расчетных значений критерия соответствует свое число степеней свободы, табличные значения окажутся разными.
Дисперсионный анализ в среде Excel
Алгоритм двухфакторного дисперсионного анализа, естественно, требует более сложных вычислительных операций, чем однофакторный, но все они заложены в программе Excel "Двухфакторный дисперсионный анализ с повторениями" (только для равномерных комплексов!), который вызывается командой меню Сервис/ Анализ данных …. Исходные данные следует расположить на листе Excel по схеме 1 (табл. 7.6).
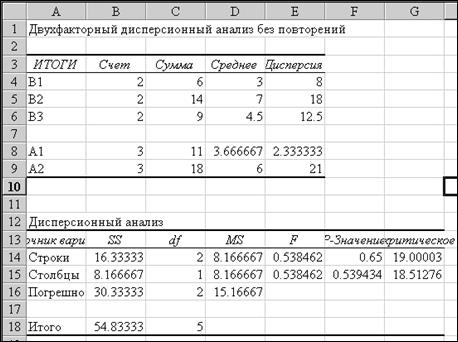
В пункте макроса "Число строк для выборки" следует поставить объем выборки в одной градации, n; для нашего примера n = 3. Результаты расчетов (рис. 7.3) помимо общей статистической обработки для каждой градации содержат дисперсионную таблицу, почти идентичную приведенной выше (табл. 7.9). Отличие касается отсутствия строки для учета общей факториальной суммы квадратов (Cфакт.) и дисперсии (S²факт.), а также добавления новых столбцов – табличного значения уровня значимости для рассчитанного критерия F Фишера; табличное значение критерия также приведено для уровня значимости α = 0.05. В среде пакета Excel есть возможность провести и "Двухфакторный дисперсионный анализ без повторений", который вызывается командой меню Сервис/ Анализ данных …. Как отмечалось выше, эта схема организации данных не позволяет разделить случайное варьирование и взаимодействие факторов. Например, если в качестве исходных данных взять только первые значения из предыдущего набора (табл. 7.8), дисперсионный анализ без повторений даст следующие результаты (рис. 7.4).
Рис. 7.3. Двухфакторный дисперсионный анализ на листе Excel
Как видно из таблицы анализа, изменчивость, обусловленная взаимодействием факторов, объединена со случайной в строке "Погрешность". Рассмотренные схемы дисперсионного анализа принципиально соответствуют и более сложным задачам, в частности, многофакторному дисперсионному анализу. Поскольку статистическая обработка многофакторных (особенно неравномерных) комплексов требует значительного увеличения расчетных работ, для таких задач мы рекомендуем использовать не возможности Excel, но специализированные пакеты программ ЭВМ, например, StatGraphics.
Рис. 7.4. Двухфакторный дисперсионный анализ данных без повторений на листе Excel
Дисперсионный анализ в среде StatGraphics
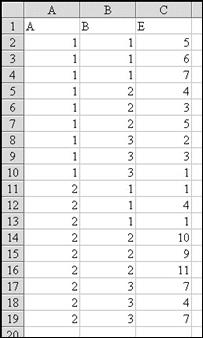
Рассмотрим использование пакета StatGraphics для проведения двухфакторного дисперсионного анализа по тем же данным. Исходные данные для обработки с помощью пакета StatGraphics лучше всего подготавливать на листе Excel, а затем импортировать в StatGraphics. Среда Excel более "дружелюбна" и "гибка", допускает операции автозаполнения и к тому же при импорте названия переменных назначаются автоматически (см. ниже). Пакет StatGraphics (версия 2.1) разработан для ранних версий Windows, поэтому импорт данных возможен только в старых форматах файлов типа *.dbf (для dBase II, III) или *.xls. (для MS Excel 4.0). Общий порядок операций по обработке данных таков: – подготовка данных в среде Excel, – экспорт данных в файле типа *.xls. для MS Excel 4.0, – импорт данных в среду StatGraphics, – проведение расчетов. Подготовим данные из табл. 7.8 для двухфакторного дисперсионного анализа в среде Excel.
Так, значение Е = 11 (ячейка C7) получено при дозах А = 1, В = 2. Если проводится изучение действия более чем двух факторов, на листе организуются все новые и новые столбцы с кодами градаций факторов. При этом важно следить, чтобы были представлены все сочетания градаций. В нашем случае, например, и градация А1, и градация А2 должны содержать по три градации второго фактора: В1, В2, В3. При этом StatGraphics не требует равного объема выборок для всех градаций. Экспорт подготовленных данных из среды Excel осуществляется командой меню Файл\ Сохранить как …. В окне Тип файла: следует выбрать Файл Microsoft Excel 4.0. В окне Имя файла: задать новое имя, чтобы не утратить информацию, содержащуюся на других листах текущей книги, ОК. Далее, на запрос о сохранении только текущего листа ответить ОК.
Импорт данных в среду StatGraphics осуществляется третьей слева кнопкой панели Toolbar или командой меню File\ Open Data File... . В окне Тип файлов (Files type:) появившегося фрейма выделить Excel Files (*.xls), затем следует указать директорию, содержащую искомый файл, щелкнуть на его имя и Открыть.
В появившемся окошке Read Excel File указать, что имена переменных Variable Names нужно брать из первого ряда (from first row), ОК.
Информация из файла попадет в блок данных, чья свернутая панель расположена слева внизу. Развернуть окно данных можно двойным кликом на "шапке".
Расчеты по схеме двухфакторного дисперсионного анализа запускаем командой меню Compare\ Analysis of Variance\ Multifactor ANOVA.
В появившемся окне Multifactor ANOVA результативный признак Е заносим в графу "зависимая переменная" (Dependent Variable:), т. е. выделяем имя мышкой и нажимаем на кнопку стандартного отклонения стрелкой. Оба фактора заносим в графу Factors:, ОК. Сразу же все расчеты будут выполнены, но отобразится только одна панель с общим описанием переменной и факторов. Для отображения главных результатов, в первую очередь таблицы дисперсионного анализа, нужно нажать на вторую слева желтую кнопку (Tabular options), в новом окне отметить галочкой ANOVA Table или нажать кнопку All, ОК.
Чтобы раскрыть новое окно Analysis of variance for E, следует на нем дважды кликнуть. Раскроется таблица дисперсионного анализа, рассчитанная по схеме "без повторений" и не содержащая оценку взаимодействия факторов. Рассчитать этот эффект можно, изменив установки анализа. Правой кнопкой мыши нужно щелкнуть на поле дисперсионной таблицы и выбрать из контекстного меню пункт Analysis options, после чего в окошке Multifactor ANOVA options указать, что число взаимодействующих факторов равно 2, ОК.
Дисперсионная таблица сразу приобретет строку учета взаимодействия (interactions AB). С помощью этой опции можно эффективно регулировать "глубину" учета взаимодействий, когда исследуется несколько факторов.
Результаты дисперсионного анализа полностью идентичны табл. 7.8 и табл. 7.9. Важно отметить, что итог всех вычислений в среде StatGraphics сопровождаются комментариями о методах расчета, а также статистическими выводами. Текст комментариев можно скопировать в буфер обмена из окна StatAdvisor.
8 Задача "найти зависимость между двумя признаками"
Изложенные выше методы статистического анализа дают возможность изучать изменчивость биологических объектов по отдельным признакам – весу, размерам, плодовитости, физиологическим показателям и др. Однако в ряде случаев важно знать, какова зависимость между вариацией двух или нескольких признаков, изменяются ли две переменные самостоятельно, независимо друг от друга, или изменчивость одного признака в какой-то степени связана с изменчивостью другого. В качестве второй переменной часто выступает какой-либо фактор среды. Эту задачу можно рассматривать как развитие метода дисперсионного анализ, решающего задачу сравнения нескольких выборок (изучения влияния фактора на признак). Техника дисперсионного анализа имеет две особенности. Во-первых, фактор (факториальный признак) задан дискретно, в виде градаций, или "доз". Когда исследуется фактор, заданный качественно, то градации оказываются очень эффективным способом его превращения в подобие количественно заданного фактора. Вместе с тем фактор, выраженный количественной величиной, имеет большее число значений, чем число градаций. Тогда в грубой градуальной схеме дисперсионного анализа утрачивается часть информации, имеющейся в исходных выборках. Кроме этого, дисперсионный анализ явным образом не учитывает тенденции изменения среднего уровня признака при изменении уровня фактора, не содержит показателя динамики зависимости признака от фактора. Сделать необходимые дополнения позволяет исследование сопряженной (взаимозависимой) изменчивости признаков в рамках регрессионного и корреляционного анализов. Способ представления отдельных наблюдений здесь меняется: каждая варианта рассматривается как носитель двух численных характеристик объекта измерения, двух зависимых значений случайной величины. Если выше мы отождествляли отдельное значение с отдельной вариантой, то теперь мы рассматриваем варианту как некоторое тело, обладающее минимум двумя зарегистрированными качествами, различными у разных вариант:
Вся выборка предстанет в виде множества точек на плоскости (двумерное рассеяние). Как видно на диаграмме, "облако" вариант вытянуто в направлении диагонали облака точек. Справа вверху находятся варианты с высокими значениями и размеров и массы тела, в левом нижнем углу – с наименьшими значениями. В центре находятся варианты с промежуточными, средними значениями. В первом приближении двумерное распределение – это простая ординация вариант на плоскости осей двух признаков. Помимо рассеяния на плоскости, в определение двумерного распределения входит и частота встречаемости отдельных вариант. В соответствии с идеологией регрессионного анализа признаки x и y должны подчиняться нормальному закону. Значит, для каждого значения x признак y дает множество нормально распределенных значений; то же и для каждого значения признака y (для случая математической совокупности бесконечного объема) (рис. 8.1). Скопление вариант в трех осях (оси признаков x, y и частоты а) образует весьма странный "бугор", растянутое в пространстве трехмерное нормальное распределение. Однако в реальности такой идеальной картины получить никогда не удается, приходится ориентироваться только на плоскую фигуру рассеяния немногочисленных вариант. Если область, занятую вариантами, очертить по периферии плавной линией, мы получим вытянутую фигуру, эллипс, ограничивающий область рассеяния вариант, эллипс рассеяния. Эллипс рассеяния – это область распространения вариант одной совокупности.
Рис. 8.1. Двумерное распределение Таблица 8.1
Итак, в двумерном распределении проявляются два эффекта: синхронное изменение двух признаков и размывание этой синхронности, т. е. действие факторов доминирующих и случайных: доминирующий фактор (фактор сопряжения признаков) действует вдоль оси эллипса, случайные факторы – поперек оси, размывая взаимозависимость y и x. Проблема изучения зависимости распадается на ряд частных задач (табл. 8.1).

Не нашли, что искали? Воспользуйтесь поиском по сайту: ©2015 - 2026 stydopedia.ru Все материалы защищены законодательством РФ.
|










 Например, для любого животного можно определить массу (M) и длину (L) тела; отдельная варианта будет нести два значения (L, M). При этом множество вариант выборки можно отобразить графически как точки на плоскости осей двух признаков M и L.
Например, для любого животного можно определить массу (M) и длину (L) тела; отдельная варианта будет нести два значения (L, M). При этом множество вариант выборки можно отобразить графически как точки на плоскости осей двух признаков M и L. Можно видеть, что в нашем случае признаки связаны друг с другом – есть общая тенденция: чем больше длина тела, тем больше вес, хотя эта зависимость и не очень жесткая, но размыта индивидуальными особенностями.
Можно видеть, что в нашем случае признаки связаны друг с другом – есть общая тенденция: чем больше длина тела, тем больше вес, хотя эта зависимость и не очень жесткая, но размыта индивидуальными особенностями.