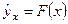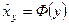|
|
Социальная деятельность и социальные показатели 6 главаПоказатели колеблемости (вариации) значений признаков. Для характеристики рядов распределения оказывается недостаточным указание только средней величины данного признака, поскольку два ряда могут иметь, к примеру, одинаковые средние арифметические, но степень концентрации (или, наоборот, разброса) значений признаков вокруг средней будет совершенно различной. Характеристикой такого разброса служат показатели колеблемости — разность между- максимальным и минимальным значениями признака в некоторой совокупности (вариационный размах), а также другие показатели: среднее абсолютное (линейное) отклонение, среднее квадратическое отклонение и т. п. Дисперсия. Дисперсией называется величина, равная среднему значению квадрата отклонений отдельных значений признаков от средней арифметической. Обозначается дисперсия s2 и вычисляется по формуле
Корень квадратный из дисперсии называется средним квадратическим отклонением и обозначается. Геометрически среднее квадратическое отклонение является показателем того, несколько в среднем кривая распределения размыта относительно ее среднего арифметического. Измеряется в тех же единицах, что и изучаемый признак. При ручном счете для упрощения вычислений дисперсию (s) рассчитывают по формуле методом отсчета от условного нуля. Для интервального ряда с равными интервалами процедура следующая. Сначала вычисляются центры интервалов. Относительно какого-либо отобранного серединного интервала ряда, например А, вверх и вниз выписывается натуральный ряд чисел (аi) соответственно со знаком «плюс» и «минус»: 0, +1, +2 и т. д.; -1, -2 и т. д. (табл. 4). Далее вычисляются величины Среднее арифметическое находится по формуле[87]
Тогда дисперсия равна
Приведенные вычисления показывают, что при среднем возрасте 40 лет все остальные члены совокупности имеют возраст, который в среднем отклоняется от 40 лет на 7,8 лет, т. е. примерно на 20%. Таблица 4 . Пример вычисления дисперсии*
* Численные данные о распределении кандидатов наук по возрастным группам в отделении экономики, истории, философии и права АН УССР (Организация науки/ Под ред. Г. М. Доброва, М., 1970, с. 148—149).
Среднее абсолютное отклонение. Эта мера вариации представляет собой среднее арифметическое из абсолютных величин отклонений отдельных значений признака от их среднего арифметического
где .Вместо среднего арифметического в формуле 9 часто берут моду или медиану. Для симметричных распределений мода, медиана и среднее арифметическое совпадают и выбор средней не представляет труда. Для асимметричного распределения иногда отдают предпочтение медиане. Величина среднего квадратического отклонения всегда больше d и для достаточно большой выборочной совокупности с распределением признака, близкого к нормальному, связана с
Например, для данных табл. 4 вреднее линейное отклонение, подсчитанное по формуле 9, равно d = 6,3 года. Тогда s = 1,25*6,3 = 7,87 что с учетом погрешности вычислений совпадаете найденным ранее средним квадратическим отклонением. Таким образом, для предварительного анализа можно заменить вычисление менее трудоемким вычислением. Коэффициент вариации. Среднее линейное и среднее квадратическое отклонение являются мерой абсолютной колеблемости признака и всегда выражаются в тех же единицах измерения, в которых выражен изучаемый признак. Это не позволяет сопоставлять между собой средние отклонения различных признаков (в случае разных единиц измерения) в одной и той же совокупности, а также одного и того же признака в разных совокупностях с различными средними. Чтобы иметь такую возможность, средние отклонения часто выражаются через соотнесение в процентах к среднему арифметическому, т.е. в виде относительных величий. Отношение среднего линейного или среднего квадратического отклонения к среднему арифметическому называется коэффициентом вариации (V):
Очевидно, что тот из рядов имеет большее рассеяние, у которого коэффициент вариации больше. Рассмотренные выше показатели вариации применимы лишь к количественным признакам, а точнее к признакам, измеренным не ниже чем по интервальной шкале. Применение этих мер для низших уровней, строго говоря, некорректно и требует тщательной интерпретации полученных результатов. Вариации качественных признаков. Если признак имеет k взаимоисключающих градаций, то для вычисления индекса качественной вариации применяется - процедура, поясняемая .следующим примером. Пусть получено следующее распределение ответов (взаимоисключающих) на вопросы А, В и С (колонка 1):
Во вторую колонку запишем такие частоты, которые получились бы при равномерном заполнении всех трех вопросов, т. е. 120/3 = 40. Теперь вычислим величину
Этот показатель называется индексом качественной вариации и указывает на степень неоднородности полученных ответов. Если бы все ответы попали лишь в одну градацию, то J=0, что означало бы полное единство в ответах, хотя, конечно, индекс совершенно не учитывает того, в какую именно градацию попали все эти ответы. Совершенно аналогично индекс вычисляется при любом числе градаций. Но для альтернативных признаков вариация обычно подсчитывается по формуле (14). Она отличается от J на константу, называется дисперсией, выражается в абсолютных числах и обозначается s2:
Другой мерой вариации признака (независимо от уровня измерения) может служить так называемая энтропия — мера неопределенности, вычисляемая по формуле
Логарифм в этой формуле может быть взят по любому основанию. Энтропия обладает следующими свойствами: а) энтропия равна нулю лишь в том случае, если вероятность получения одного из значения xi, признака x равна единице (вероятность остальных значений при этом равна нулю). Такой признак не обладает неопределенностью, так как достоверно известно одно единственно возможное его значение. Во всех остальных случаях, когда имеется та или иная неопределенность в значениях xi, энтропия является положительной величиной; б) наибольшей энтропией обладает признак, когда все, значения xi равновероятны. Для признака с k градациями
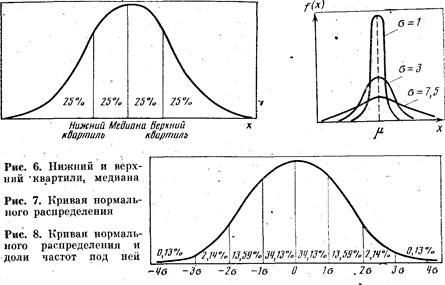
Отсюда видно, что максимальная энтропия увеличивается с ростом числа градаций в признаке, 5. Нормальное распределение. Статистические гипотезы Адекватное применение количественных методов, вошедших в практику социологических исследований, в той или иной степени опирается на предположение, что изучаемый признак (или совокупность признаков) подчиняется определенному статистическому закону распределения. Таким наиболее часто встречающимся распределением является нормальный закон, представление о котором дано здесь в очень кратной форме. Вторая группа вопросов, рассмотренных в этом разделе, связана с проверкой гипотез. Можно выделить две функции статистических процедур: во-первых, это описание элементов совокупности, во-вторых, помощь исследователю в принятии некоторых решений о них. В предыдущих разделах этой главы их рассмотрение было связано с дескриптивной функцией статистики. Здесь же кратко описаны основные понятия и принципы статистического вывода. Нормальное распределение. Наиболее широко известным теоретическим распределением является нормальное, или гауссовское, распределение. Нормальное распределение признака наблюдается в тех случаях, когда на величину его значений действует множество случайных независимых или слабозависимых факторов, каждый из которых играет в общей сумме примерно одинаковую и малую роль (т. е. отсутствуют доминирующие факторы), Функция плотности гауссовского распределения имеет вид
где 2 — дисперсия случайной величины (2 — это теоретическая дисперсия, отличающаяся от s2, вычисляемой по выборочным данным); m — среднее значение (математическое ожидание) (рис. 7). В практических расчетах часто используется так называемое правило трех сигм, которое заключается том, что лишь 0,26% всех значений нормально распределенного признака лежат вне интервала m±3, т. е. почти все значения признака укладываются в интервалеиз шести сигм (рис. 8). Статистические гипотезы. Статистической называют гипотезу о виде неизвестного распределения либо о параметрах известных распределений[88]. Так, статистической будет гипотеза о том, что переменная в генеральной совокупности распределена по нормальному закону. Проверяемую гипотезу называют нулевой (основной) гипотезой и обозначают Но. Наряду с нулевой рассматривается конкурирующая гипотеза /Л (альтернативная), которая ей противоречит. Статистический критерий и проверка гипотез. Для проверки нулевой гипотезы используется специально подобранная случайная величина, точное, либо приближенное распределение которой известно и обычно сведено в таблицы. Эта величина называется статистическим критерием. Обозначим его пока К. Для критерия К фиксируется так называемая критическая область, т. е. совокупность значений критерия, при которых нулевую гипотезу отвергают. Точка Kкр называется критической, если она отделяет критическую область от области принятия гипотезы. Различают правостороннюю, левостороннюю и двустороннюю критические области. Принятие или отверженце гипотезы производится на основе соответствующего статистического- критерия с определенной вероятностью. Считают, что пулевая гипотеза справедлива, если вероятность того, что критерий К примет значение, большее Kкр, т. е. попадет в критическую область, равна выбранному значению вероятности a, т. е.
Принятая вероятность a называется уровнем значимости. Практически принятие или отвержение нулевой гипотезы проводится следующим образом: выбирается соответствующий критерий (этот вопрос будет обсуждаться далее); вычисляется наблюдаемое значение критерия KH, исходя из эмпирического распределения; выбирается уровень статистической значимости (обычно 0,05 или 0,01). По таблице распределения критерия К для данного уровня значимости находят критическую точку Kкр. Если KH>Kкр, нулевую гипотезу отвергают, если же KH<Kкр, то ее отвергать нет основания. Делая такие выводы (т. е. принимая или отвергая гипотезу), можно совершить ошибки двух типов: отвергнуть гипотезу, когда она верна; принять ее, когда она неверна. Поэтому при принятии гипотезы было бы неверным считать, что она тем самым полностью доказана. Для большей уверенности необходимо ее проверять другими способами (например, увеличить объем выборки). Отвергают гипотезу более категорично, чем принимают. Примеры статистических гипотез: а) нормальное распределение имеет заданное среднее и дисперсию либо имеет заданное среднее (о дисперсии ничего не говорится); б) распределение нормальное либо два неизвестных распределения одинаковы. В качестве критериев чаще всего используются случайные величины, распределенные нормально (2—критерий), по закону Фишера (F — критерий Фишера), по закону Стьюдента (критерий Стьюдента), по закону хи-квадрат (критерий c2) и т. д. В качестве конкретного примера рассмотрим применение критерия хи-квадрат для проверки гипотезы о виде распределения изучаемого признака. Критерий хи-квадрат. Популярность критерия хи-квадрат обусловлена главным образом тем, что применение его не требует предварительного знания закона распределения изучаемого признака. Кроме того, признак может принимать как непрерывные, так и дискретные значения,, причем измеренные хотя бы на поминальном уровне. Если закон распределения признака неизвестен, по есть основания предположить, что он имеет определенный вид А, то критерий c2 позволяет проверить гипотезу: исследуемая совокупность распределена по закону А. Для проверки такой гипотезы сравниваются эмпирические (наблюдаемые) и теоретические (вычисленные в предположении определенного распределения А) частоты. Выпишем эти частоты:
Как правило, эмпирические и теоретические частоты будут различаться. Возможно, что наблюдаемое различие случайно (статистически незначимо) и объясняется либо малым числом наблюдений, либо способом их группировки, либо иными причинами. Но возможно, что расхождение частот значимо и объясняется тем, что теоретические частоты вычислены исходя из неверной гипотезы о характере распределения значений рассматриваемых признаков, генеральной совокупности. Критерий c2 отвечает на вопрос, случайно или нет такое расхождение частот. Как любой критерий, c2 не доказывает справедливость гипотезы, а лишь с определенной вероятностью а устанавливает ее согласие или несогласие с данными наблюдениями. Критерий c2 имеет вид
Критическая точка распределения c2 находится; (см. табл. Б приложения) по заданному уровню значимости a, и числу степеней свободы df. Число степеней свободы находят по формуле
где k — число интервалов вариационного ряда; r — число параметров предполагаемого распределения, которые оценены по данным выборки (например, для нормального распределения оценивают двапараметра: m и s2). Рассмотрим пример, когда признак оценивался в терминах очень низкий, средний), очень высокий и был получен следующий ряд распределения для этих трех категорий:
Проверим гипотезу о том, что в генеральной совокупности значения этого признака распределены равномерно. Теоретическое распределение для этих групп получим,если предположим, что эти категории независимы, т. е. респондент с одинаковой вероятностью может попасть в любую группу. Очевидно, ожидаемая (теоретическая) частота будет равна 24/3 = 8 человек. Таким образом, имеем следующие эмпирические и теоретические частоты:
Проверяется гипотеза, что число респондентов во всех трех категориях одинаково, т. е. отличие распределения от равномерного статистически незначимо. Вычислим величину
По таблице распределения c2, например, для уровня значимости 0,05 и степени свободы, равном df = 3 – 1 = 2, находим критическую точку Хи-квадрат-критерий применим и для проверки нулевой гипотезы об отсутствии связей между признаками в случае, если эмпирические данные сгруппированы не по одному, как выше, а по нескольким признакам. Например, пусть имеется выборка в 190 человек, чье мнение относительно какого-то определенного вопроса исследовалось (табл. 5). Расчленим эту выборку па три независимых категории по возрасту. Рассмотрим следующие гипотезы: Н0 — не существует различия мнений относительно этого вопроса среди различных возрастных групп; Н1 — существует различие. Проверим гипотезу для уровня значимости a = 0,05. Таблица 5.Пример для вычисления c2
Для нахождения ожидаемой (теоретической) частоты в любой плетке таблицы необходимо просто перемножить соответствующие маргинальные частоты и разделить произведение на итоговую сумму. Например, ожидаемая частота для клетки (а) равна
Процедуру вычисления представим в табл. 6. Число степеней свободы определяется по формуле
где r — число строк, а с — число столбцов в табл. 5. Для нашего примера df = (4—1)(3—1) == 6. По табл. Б приложения находим, что c2 = 16,812. Следовательно, нужно отвергнуть гипотезу о том, что нет различий в мнении среди неодинаковых возрастных групп, т. е. можно предположить, что существует значимая статистическая взаимосвязь между тем, к какой возрастной группе принадлежит респондент, и тем мнением, которое он высказывает. Однако величина c2 не говорит о силе связи между переменными, а лишь указывает на вероятность существования такой связи. Для определения интенсивности связи необходимо использовать соответствующие меры связи. Для корректного применения методов, основанных на c2, исследователь должен обеспечить выполнение следующих условий. Выборку необходимо получить из независимых наблюдений. Данные могут быть измерены на любом уровне, по ни одна из ожидаемых частот не должна быть слишком мала (минимум 5). Если же частоты оказываются менее 5, то необходимо либо уменьшить степень дробности группировки признаков, объединив соседние категории, либо обратиться к другому критерию[89]. Таблица 6.Схема вычисления c2
6. Статистические взаимосвязи и их анализ Понятие о статистической зависимости. Исходя из известного положения исторического материализма о всеобщей взаимозависимости и взаимообусловленности явлений общественной жизни, социолог-марксист не может ограничиться изучением отдельно взятого явления изолированно от других процессов и событий, а должен стремиться по возможности охватить весь комплекс явлений, относящихся к тому или иному социальному процессу и изучить существующие между ними зависимости. Различают два вида зависимостей: функциональные (примером которых могут служить законы Ньютона в классической физике) и статистические. Закономерности массовых общественных явлений складываются под влиянием множества причин, которые действуют одновременно и взаимосвязанно. Изучение такого рода закономерностей в статистике и называется задачей о статистической зависимости. В этой задаче полезно различать два аспекта: изучение взаимозависимости между несколькими величинами и изучение зависимости одной или большего числа величин от остальных. В основном первый -аспект связан с теорией корреляций (корреляционный анализ), второй — с теорией регрессии (регрессионный анализ). Основное внимание в этом параграфе уделено изучению взаимозависимостей нескольких признаков, а основные принципы регрессионного анализа рассмотрены очень кратко. В основе регрессионного анализа статистической зависимости ряда признаков лежит представление о форме, направлении и тесноте (плотности) взаимосвязи. В табл. 7 приведено эмпирическое распределение заработной платы рабочих в зависимости от общего стажа работы (условные данные) для выборки в 25 человек, Таблица 7. Распределение заработной платы и общего стажа работы
а на рис. 9 эти численные данные представлены в виде так называемой диаграммы рассеяния, или разброса. Вообще говоря, визуально не всегда можно определить, существует или нет значимая взаимосвязь между рассматриваемыми признаками и насколько она значима, хотя очень часто уже на диаграмме просматривается общая тенденция в, изменении значений признаков и направление связи между изучаемыми признаками. Уравнение регрессии. Статистическая зависимость одного или большего числа признаков от остальных выражается о помощью уравнений регрессии. Рассмотрим две величины х и y, такие, например, как на рис. 9. Зафиксируем какое-либо значение переменной х, тогда у принимает целый ряд значений. Обозначим
Аналогичным образом можно дать геометрическую интерпретацию регрессионному уравнению[90]
Уравнение регрессии описывает числовое соотношение между величинами, выраженное в виде тенденции к возрастанию (или убыванию) одной переменной величины при возрастании (убывании) другой. Эта тенденция проявляется на основе некоторого числа наблюдений, когда из общей массы выделяются, контролируются, измеряются главные, решающие факторы. Характер связи взаимодействующих признаков отражается в ее форме. В этом отношении полезно различать линейную и нелинейную, регрессии. На рис. 10, 11 приведены графики линейной и криволинейной форм линий регрессии и их диаграммы разброса для случая двух переменных величии. Направление и плотность (теснота),линейной связи между двумя переменными измеряются с помощью коэффициента корреляции. 
Не нашли, что искали? Воспользуйтесь поиском по сайту: ©2015 - 2026 stydopedia.ru Все материалы защищены законодательством РФ.
|
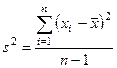 (6)
(6) . В качестве промежуточного результата по формуле (7) получаем среднее арифметическое. Величина дисперсии получается подстановкой промежуточных величин из табл. 4 в формулу (8).
. В качестве промежуточного результата по формуле (7) получаем среднее арифметическое. Величина дисперсии получается подстановкой промежуточных величин из табл. 4 в формулу (8). (лет) (7)
(лет) (7)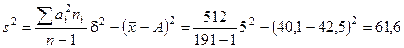 (8)
(8)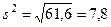 (лет)
(лет)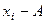







 (9)
(9)
 означает, что суммируются значения отклонений без учета знака этих отклонений;
означает, что суммируются значения отклонений без учета знака этих отклонений;  — объем совокупности.
— объем совокупности. соотношением
соотношением
 (11)
(11) (12)
(12)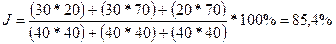 (13)
(13) (14)
(14) . (15)
. (15)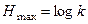
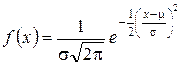
 (для правосторонней области);
(для правосторонней области); (для левосторонней области);
(для левосторонней области);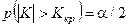 (для двусторонней области).
(для двусторонней области).


 (17)
(17) ,
,

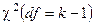 по формуле (17):
по формуле (17):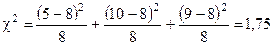
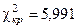 . Таким образом, наблюдаемое значение c2 меньше
. Таким образом, наблюдаемое значение c2 меньше  , следовательно, данные наблюдений согласуются с нулевой гипотезой и не дают оснований ее отвергнуть.
, следовательно, данные наблюдений согласуются с нулевой гипотезой и не дают оснований ее отвергнуть.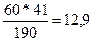
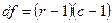



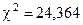
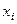 ), лет
), лет
 , руб.
, руб.
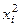








 среднюю величину этих значений у при данном фиксированном х. Уравнение, описывающее зависимость средней величины
среднюю величину этих значений у при данном фиксированном х. Уравнение, описывающее зависимость средней величины  от х, называется уравнением регрессии у по х:
от х, называется уравнением регрессии у по х: