
|
|
Социальная деятельность и социальные показатели 8 глава
Если подсчитать Значимость коэффициента корреляции Спирмена для l£100 можно определить по табл. Г приложения, где приведены критические величины Если l>100, то критические значения находятся по табл. А приложения. Наблюдаемые значения критерия вычисляются по формуле
Например, возвращаясь к данным табл. 10, где l<100, по табл. Г приложения найдем, что для того, чтобы Коэффициент ранговой корреляции Для расчета
Как вычисляется S, поясним на примере данных табл. 10. Таблица упорядочена так, что в графе «Ранг I» ранги расположились в порядке возрастания их значений. Берем значение ранга, стоящего в графе Ранг II на первом месте, 3,5; из расположенных ниже данного ранга семи других четыре значения его превышают, а два — меньше его. Число 4 записывается в графу
Тогда, подставив соответствующие значения в формулу (36), получим
Таким образом, При расчете
где Значимость коэффициента корреляции Кендалла
Гипотеза о том, что Для вышеприведенного примера
По табл. А приложения для a = 0,05 находим Коэффициенты корреляции Спирмена и Кендалла используются как меры взаимозависимости между рядами рангов, а не как меры связи между самими переменными. Так, в табл. 10 ранги отражают иерархию жизненных планов, но совершенно не говорят о том, что дети рабочих почти в равной мере хотят получить как высшее образование, так и интересную работу (разница 0,2%), а дети крестьян в большей степени стремятся к высшему образованию (разница 8%). Кроме того, какая-нибудь из групп респондентов может считать, что выделенные категории вообще не отражают их жизненных планов, но проранжировали предложенные варианты. Если для целей исследования можно предположить эти моменты несущественными, то оправданно применение ранговой корреляции. Коэффициенты Спирмена и Кендалла обладают примерно одинаковыми свойствами, но т в случае многих рангов, а также при введении дополнительных объектов в ходе исследования имеет определенные вычислительные преимущества[97]. Другая мера связи между двумя упорядоченными переменными — у. Она, так же как и предыдущие коэффициенты, изменяется от +1 до —1 и может быть подсчитана при любом числе связанных рангов. Формула для вычисления записывается в виде
Для иллюстрации правил вычисления Таблица 11. Распределение ответивших на вопрос: «Устраивает ли Вас Ваша настоящая работа» — в зависимости от стажа работы в бригаде
Процесс вычисления
СХЕМА 2. Схема вычисления
Так:
Подставляя эти величины в формулу для
Проверку статистической значимости проводят по формуле
Гипотеза H0 о равенстве нулю коэффициента отвергается, если
Для a = 0,05 по табл. А приложения Множественный коэффициент корреляции W. Этот коэффициент, иногда называемый коэффициентом конкордации, используется для измерения степени согласованности двух или нескольких рядов проранжированных значений переменных. Коэффициент W вычисляется по формуле
где k — число переменных; п — число индивидов или категорий, которые ранжируются; Таблица 12. Вычисление множественного коэффициента ранговой корреляции
Для данных табл. 12 а = 45/5 = 9;
Значимость полученной величины W для п>7 проверяется по критерию
со степенью свободы n—1. Для примера Коэффициенты взаимозависимости для номинального уровня измерения. Связь в табл. 2×2. Простейшая задача о взаимозависимости возникает тогда, когда имеются два признака, каждый из которых принимает два значения (табл. 13). Таблица 13. Распределение отношения к правилам уличного движения в зависимости от пола
Представим данные о группировке по этим двум признакам так:
Для характеристики степени связи двух признаков применяется коэффициент Ф, определяемый формулой
Коэффициент Ф равен 0, если нет соответствия между двумя дихотомическими переменными, и равен 1 или —1, когда имеется полное соответствие между ними. В силу трудностей с интерпретацией знака коэффициента для категоризованных (номинальных) переменных часто используют в анализе лишь абсолютную величину — Как уже отмечалось, Ф вычисляется для категоризованных данных, представляющих естественные дихотомии: пол, раса, и т. п. Приведение количественных переменных к дихотомическому виду связано с выбором граничной точки разделения (например, мужчины до 30 лет и мужчины старше 30 лет). Искусственная дихотомизация, столь часто необходимая в конкретном исследовании при изучении взаимосвязи признаков, может привести к тому, что одна часть дихотомической переменной по своему воздействию будет более значима для одной связи, другая— для другой, а это даст ошибочный результат. Измерение связи в табл., с×k. Рассмотрим теперь более общую ситуацию, когда две переменные классифицированы на две или более категории. Запишем это таким образом:
где Нормированным коэффициентом корреляции для таблицы с×k является коэффициент сопряженности Пирсона (Р):
Коэффициент Р = 0 при полной независимости признаков. Недостатком его является зависимость максимальной величины Р от размера таблицы (максимум Р достигается при, с = k, но сама граница изменяется с изменением числа категорий). В связи с этим возникают трудности сравнения таблиц разного размера. Чтобы исправить указанный недостаток, Чупров ввел другую величину:
При с = k Т достигает +1 в случае полной связи, однако не обладает этим свойством при Коэффициент Крамера (К) может всегда достигать +1 независимо от вида таблицы:
Для квадратной таблицы коэффициенты Крамера и Чупрова совпадают, а в остальных случаях К>Т. Величина
Вычисление коэффициентов Р, Т и К связано с теми же ограничениями на Следующая группа коэффициентов связи для категоризованных данных основана на предположении, что если две переменные связаны, то информация об одной переменной может быть использована для предсказания другой. Так, если предположить, что связь между полом индивида и его отношением к правилам уличного движения абсолютно детерминирована, то согласно табл. 13 либо все мужчины были бы нарушителями, а женщины нет, либо наоборот. Поскольку это но так, то возникает несоответствие, или, как говорят, ошибка предположения абсолютной связи (обозначим величину этой ошибки ОА). С другой стороны, можно предположить, что два признака абсолютно не связаны, и нельзя на основе одной переменной предсказать другую. Поскольку это тоже не так, то возникает ошибка предположения об отсутствии связи (О0). Тогда величина Признак, на основе которого предсказывается другой признак, будем называть независимой переменной, а предсказываемый — зависимой. Тогда для случая, когда зависимая переменная расположена по строкам таблицы (т. е. категории расположены по строкам), вычисляется коэффициент связи
где Пример. Вычислим
Таким образом, использование информации о поле обследованных для предсказания отношения к правилам движения не уменьшает относительной ошибки. Если зависимая переменная — это категории столбцов таблицы, то совершенно аналогично предыдущему вычисляется
где Для нашего примера, когда пол зависимая переменная, Коэффициенты В ряде случаев удобно использовать симметричную
Разнообразие корреляционных коэффициентов продиктовано стремлением отразить реально существующее разнообразие типов связей в природе и обществе. Поэтому данное обстоятельство следует рассматривать скорее как свидетельство достоинств статистического аппарата, заключающихся в гибкости и большой приспособленности его к анализу сложнейших взаимосвязей в социальной области. Каждый корреляционный коэффициент приспособлен для измерения вполне определенного вида связи. Техника расчета и конструкция формулы одного и того же коэффициента могут измениться в зависимости от того, какие (например, сгруппированные или несгруппированные) данные приходится анализировать. Сравните, например, различные варианты формул для парного коэффициента корреляции r. Таким образом, применение того или иного показателя определяется природой данных и формой их представление. Требуемая степень точности также может существенно повлиять па выбор способа расчета связи в каждом конкретном случае. Обычно оценка пригодности той или иной формулы производится с учетом следующих факторов: 1) природы данных (качественные или количественные признаки); 2) формы и типа зависимости (линейная или нелинейная, положительная или отрицательная связь); 3) требуемой точности расчетов (например, коэффициенты корреляции рангов 4) удобства - при вычислении и сравнительной простоты интерпретации; . 5) трудностей технического порядка (имеется ли счетная техника или нужно вести расчеты вручную); 6) распространенности использования того или иного коэффициента корреляции; 7) возможности сравнения различных коэффициентов. Обычно предпочитают использовать наиболее распространенные в практике социологических исследований коэффициенты, так как тем- самым достигается возможность сравнения полученных результатов с материалами других исследований. 7. Новые подходы к анализу данных, измеренных по порядковым и номинальным шкалам В последние годы как у нас в стране, так и за рубежом разработано довольно много математических методов, предназначенных для анализа данных, полученных с помощью измерения по номинальным и порядковым шкалам. Однако многие из них малознакомы широкому кругу социологов. В настоящем параграфе представлен краткий обзор таких методов. К сожалению, в силу сложности и большого объема материала нет возможности подробно изложить суть каждого метода и тем более описать конкретную методику его применения. Поэтому все излагаемое ниже можно рассматривать лишь как некоторое указание на то, к какой литературе необходимо обратиться для решения соответствующей задачи и какого рода вопросы необходимо поставить в этой связи перед математиком. Наиболее распространенными задачами, при решении которых исследователь прибегает к помощи математических методов, являются задачи изучения связей между признаками, нахождения латентных переменных, классификации объектов. Рассмотрим задачу изучения связей между признаками. В предыдущем разделе этой главы уже рассматривались меры связи между номинальными признаками, основанные на анализе таблиц сопряженности. Определенного рода обобщением способов измерения таких связей с помощью критерия В основе традиционных подходов к измерению связей между номинальными признаками лежит представление о последней как об интегральной, т. е. о связи между рассматриваемыми признаками в целом (при расчете меры связи учитываются одновременно все те значения, которые эти признаки могут принимать). Однако такое понимание связи не является единственно возможным. Она может пониматься и как локальная, т. е. как связь между отдельными значениями (одним или несколькими рассматриваемыми признаками). Наличие интегральной связи отнюдь не означает наличия локальной, и наоборот. Так, вывод об отсутствии интегральной связи между полом и курением (например, основанный на малой величине В настоящее время разработан довольно широкий круг методов анализа описанных локальных связей. В литературе они часто называются методами поиска детерминирующих комбинаций значений переменных (или взаимодействий последних)[100]. Прежде чем подробнее пояснить суть задачи и подходы к ее решению, введем некоторые обозначения. Пусть изучается влияние каких-то l признаков (переменных), обозначаемых ниже Исследователь полагает, что рассматриваемые независимые признаки в определенной степени обусловливают тип поведения изучаемых объектов, проявляющийся в том, какие значения для того или иного объекта может принимать зависимая переменная. Другими словами, выдвигается гипотеза о соответствующей детерминации (типа поведения сочетаниями значений не зависимых переменных). Упомянутый тип поведения может пониматься по-разному. Например, его можно определить как указание вероятностей, с которыми объект, обладающий заданным сочетанием значений х, имеет то или иное значение у. В таком случае тип поведения фактически отождествляется с распределением значений зависимого признака для объектов, имеющих рассматриваемый набор значений независимых признаков. Например, если при решении упомянутого .выше вопроса о связи пола-респондента с привычкой к курению придем к выводу, что для мужчин вероятность иметь такую привычку равна 0,8, а не иметь ее — 0,2 и что для женщин аналогичные вероятности равны соответственно 0,3 и 0,7, то будем иметь основания говорить о двух типах поведения респондентов, каждый из которых определяется полом последних. Можно тип поведения отождествить со средним арифметическим множества значений зависимой переменной для рассматриваемой совокупности объектов (в таком случае естественно предполагать, что значения у получены ]по интервальной шкале). Пусть, например, у — это время, затрачиваемое респондентом в течение дня на чтение газет, 
Не нашли, что искали? Воспользуйтесь поиском по сайту: ©2015 - 2026 stydopedia.ru Все материалы защищены законодательством РФ.
|
 для каждой группы отдельно, то в первом случае, очевидно,
для каждой группы отдельно, то в первом случае, очевидно,  . (35)
. (35) Кендалла. Подобно
Кендалла. Подобно  используется формула
используется формула (36)
(36) , а 2 в колонку
, а 2 в колонку  . Аналогичный подсчет делается для второго ранга со значением 1. Число рангов, расположенных ниже данного значения и превышающих его, равно 6, а число рангов, меньших данного,— 0 и т. д. Остальные вычисления ясны из следующей таблицы:
. Аналогичный подсчет делается для второго ранга со значением 1. Число рангов, расположенных ниже данного значения и превышающих его, равно 6, а число рангов, меньших данного,— 0 и т. д. Остальные вычисления ясны из следующей таблицы:


 (37)
(37)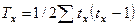 (
(  — число равных рангов по первой переменной);
— число равных рангов по первой переменной);  (
(  — число равных рангов по второй переменной). Для предыдущего примера
— число равных рангов по второй переменной). Для предыдущего примера  = 0,
= 0, 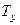 = 1.
= 1. (38)
(38) .
.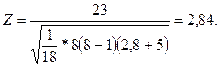
 , равное 1,96. Поскольку расчетное значение Z = 2,84 и, следовательно, больше
, равное 1,96. Поскольку расчетное значение Z = 2,84 и, следовательно, больше 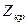 заключаем с вероятностью 95%, что
заключаем с вероятностью 95%, что 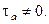
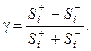
 , по сгруппированным данным обратимся к примеру (табл. 11).
, по сгруппированным данным обратимся к примеру (табл. 11). и
и 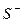 наглядно представлен па схеме (схема 2).
наглядно представлен па схеме (схема 2).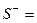
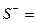
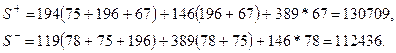
 , находим
, находим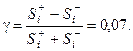
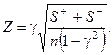
 . Для наших данных
. Для наших данных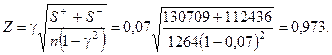
 . Таким образом,
. Таким образом, 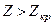 , и, следовательно, у нас нет оснований отвергнуть гипотезу Н0:
, и, следовательно, у нас нет оснований отвергнуть гипотезу Н0: 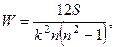
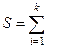 (сумма рангов по строке — а)2; а - среднее из суммы рангов.
(сумма рангов по строке — а)2; а - среднее из суммы рангов.
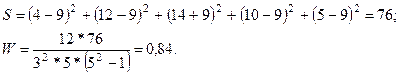
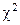 .
. (41)
(41)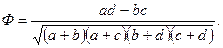 (42)
(42) . Ф легко интерпретируется, поскольку показано, что он представляет собой просто коэффициент корреляции r, если значения каждой дихотомической переменной обозначить 0 и 1.
. Ф легко интерпретируется, поскольку показано, что он представляет собой просто коэффициент корреляции r, если значения каждой дихотомической переменной обозначить 0 и 1.
 ……………
……………
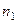
 ….
….


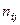 частоты;
частоты; 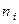 — маргинальные суммы частот по строкам;
— маргинальные суммы частот по строкам;  — маргинальные суммы частот по столбцам. На с. 169 — 172 для выяснения отклонения от независимости распределения значений в подобном случае использовался критерий
— маргинальные суммы частот по столбцам. На с. 169 — 172 для выяснения отклонения от независимости распределения значений в подобном случае использовался критерий 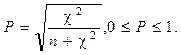 (43)
(43) (44)
(44) .
. (45)
(45)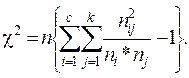
 может служить мерой относительного уменьшения ошибки при использовании информации об одной переменной для предсказания другой.
может служить мерой относительного уменьшения ошибки при использовании информации об одной переменной для предсказания другой. :
: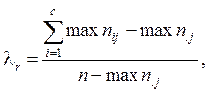 (47)
(47) — наибольшая частота в столбце i;
— наибольшая частота в столбце i;  — наибольшая маргинальная частота для строк j.
— наибольшая маргинальная частота для строк j.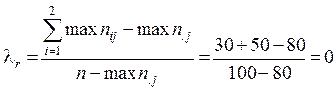
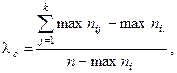 (48)
(48) — наибольшая маргинальная частота для столбцов i.
— наибольшая маргинальная частота для столбцов i. = 0,4, т. е. получаем 40%-ное уменьшение в ошибке, если используем отношение к правилам в качестве предсказывающей пол нарушителя.
= 0,4, т. е. получаем 40%-ное уменьшение в ошибке, если используем отношение к правилам в качестве предсказывающей пол нарушителя. ;
; (49)
(49) );
);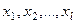 на некоторый интересующий исследователя признак у. Признаки
на некоторый интересующий исследователя признак у. Признаки 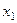 — под респондента,
— под респондента,  — его образование. Если в процессе исследования мы обнаружим, что мужчины с высшим образованием тратят на чтение газет в среднем 1,5 часа в день, а женщины с начальным образованием — 0,01 часа, то можно будет говорить о двух типах поведения респондентов, каждый из которых соответствующим образом связан с рассматриваемыми независимыми признаками.
— его образование. Если в процессе исследования мы обнаружим, что мужчины с высшим образованием тратят на чтение газет в среднем 1,5 часа в день, а женщины с начальным образованием — 0,01 часа, то можно будет говорить о двух типах поведения респондентов, каждый из которых соответствующим образом связан с рассматриваемыми независимыми признаками.