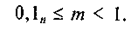|
|
Представление данных в компьютере
Изучаемые вопросы: ª Представление числовой информации. ª Представления символьной информации. ª Представление графической информации. ª Представление звука. По своему назначению компьютер — универсальное, программно-управляемое автоматическое устройство для работы с информацией. Из свойства универсальности следует то, что компьютер осуществляет все три основных типа информационных процессов: хранение, передачу и обработку информации. Современные компьютеры работают со всеми видами информации: числовой, символьной, графической, звуковой. Информация, хранимая в памяти компьютера и предназначенная для обработки, называется данными. Как уже говорилось в предыдущем разделе, для представления всех видов данных в памяти компьютера используется двоичный алфавит. Однако интерпретация последовательностей двоичных цифр для каждого вида данных своя. Еще раз подчеркнем, что речь идет о внутреннем представлении данных, в то время как внешнее представление на устройствах ввода-вывода имеет привычную для человека форму. Представление числовой информации.Исторически первым видом данных, с которым стали работать компьютеры, были числа. Первые ЭВМ использовались исключительно для математических расчетов. В соответствии с принципами Джона фон Неймана, ЭВМ выполняет расчеты в двоичной системе счисления. Вопрос о внутреннем (машинном) представлении чисел рассмотрим несколько подробнее, чем это делается в учебниках. Структурные единицы памяти компьютера — бит, байт и машинное слово. Причем понятия бита и байта универсальны и не зависят от модели компьютера, а размер машинного слова зависит от типа процессора ЭВМ. Если машинное слово для данного компьютера равно одному байту, то такую машину называют 8-разрядной (8 бит); если машинное слово состоит из 2 байтов, то это 16-разрядный компьютер; 4-байтовое слово у 32-разрядных ЭВМ. Обсуждение вопроса о том, как представляются числа в памяти ЭВМ, будем вести на примере 16-разрядной машины. Числа в памяти ЭВМ хранятся в двух форматах: в формате с фиксированной точкой и в формате с плавающей точкой. Под точкой здесь и в дальнейшем подразумевается знак разделения целой и дробной части числа. Формат с фиксированной точкой используется для хранения в памяти целых чисел. В этом случае число занимает одно машинное слово памяти (16 бит). Чтобы получить внутреннее представление целого положительного числа Л^в форме с фиксированной точкой нужно: 1) перевести число N в двоичную систему счисления; 2) полученный результат дополнить слева незначащими нулями до 16 разрядов. Например, N = 160710 = 110010001112. Внутреннее представление этого числа в машинном слове будет следующим:
В сжатой шестнадцатеричной форме этот код запишется так: 0647. Двоичные разряды в машинном слове нумеруются от 0 до 15 справа налево. Старший 15-й разряд в машинном представлении любого положительного числа равен нулю. Поэтому максимальное целое число в такой форме равно: 0111 1111 1111 11112 = 7FFF16 = (215- 1) = 3276710. Для записи внутреннего представления целого отрицательного числа (-N) нужно: 1) получить внутреннее представление положительного числа N; 2) получить обратный код этого числа заменой 0 на 1 и 1 на 0; 3) к полученному числу прибавить 1. Определим по этим правилам внутреннее представление числа 160710. 1) 0000 0110 0100 0111 2) 1111 1001 1011 1000 3)_______________ +1 1111 1001 1011 1001 - результат Шестнадцатеричная форма результата: F9B9. Описанный способ представления целого отрицательного числа называют дополнительным кодом. Старший разряд в представлении любого отрицательного числа равен 1. Следовательно, он указывает на знак числа и поэтому называется знаковым разрядом. Применение дополнительного кода для внутреннего представления отрицательных чисел дает возможность заменить операцию вычитания операцией сложения с отрицательным числом: N – M = N + (-М). Очевидно, должно выполняться следующее равенство: N + (-N) = 0. Выполним такое сложение для полученных выше чисел 1607 и —1607: 0000 0110 0100 0111 1607 1111 1001 1011 1001 -1607 1 0000 0000 0000 0000 0 Таким образом, единица в старшем разряде, получаемая при сложении, выходит за границу разрядной сетки машинного слова и исчезает, а в памяти остается ноль. Выход двоичных знаков за границу ячейки памяти, отведенной под число, называется переполнением. Для вещественных чисел такая ситуация является аварийной. Процессор ее обнаруживает и прекращает работу (прерывание по переполнению). Однако при вычислениях с целыми числами переполнение не фиксируется как аварийная ситуации и прерывания не происходит. Двоичное 16-разрядное число 1000 0000 0000 0000 = 215 является «отрицательным самому себе»: 1000 0000 0000 0000 215 0111 1111 1111 1111 _________________+1 1000 0000 0000 0000 -215 Этот код используется для представления значения —215 = —32768. Следовательно, диапазон представления целых чисел в 16-разрядном машинном слове:
В общем случае для k-разрядного машинного слова этот диапазон следующий:
В разных типах ЭВМ используются разные варианты организации формата с плавающей точкой. Вот пример одного из вариантов представления вещественного числа в 4-байтовой ячейке памяти: Формат с плавающей точкой используется как для представления целочисленных значений, так и значений с дробной частью. В математике такие числа называют действительными, в программировании — вещественными. Формат с плавающей точкой предполагает представление вещественного числа R в форме произведения мантиссы (т) на основание системы счисления (л) в некоторой целой степени, которую называют порядком (р):
Порядок указывает, на какое количество позиций и в каком направлении должна сместиться («переплыть») точка в мантиссе. Например, 25,32410 = 0,25324´102. Однако справедливы и следующие равенства:
Следовательно, представление числа в форме с плавающей точкой неоднозначно. Чтобы не было неоднозначности, в ЭВМ используют нормализованную форму с плавающей точкой. Мантисса в нормализованной форме должна удовлетворять условию:
Для рассмотренного числа нормализованной формой будет: 0,25324 хЮ2. В памяти ЭВМ мантисса представляется как целое число, содержащее только ее значащие цифры (нуль целых и запятая не хранятся). Следовательно, задача внутреннего представления вещественного числа сводится к представлению пары целых чисел: мантиссы (т) и порядка (р). В рассмотренном нами примере т = 25324, р = 2. В разных типах ЭВМ используются разные варианты организации формата с плавающей точкой. Вот пример одного из вариантов представления вещественного числа в 4-байтовой яч6ейке памяти:
1-й байт 2-й байт 3-й байт 4-й байт
В старшем бите 1-го байта хранится знак числа: 0 — плюс, 1 — минус; 7 оставшихся битов 1-го байта содержат машинный порядок; в следующих 3-х байтах хранятся значащие цифры мантиссы. В рамках базового курса информатики вопрос о представлении вещественных чисел может рассматриваться лишь на углубленном уровне. Теоретический материал и практические задания на эту тему имеются в пособии [6]. Представление символьной информации.В настоящее время одним из самых массовых приложений ЭВМ является работа с текстами. Термины «текстовая информация» и «символьная информация» используются как синонимы. В информатике под текстом понимается любая последовательность символов из определенного алфавита. Совсем не обязательно, чтобы это был текст на одном из естественных языков (русском, английском и др.). Это могут быть математические или химические формулы, номера телефонов, числовые таблицы и пр. Будем называть символьным алфавитом компьютера множество символов, используемых на ЭВМ для внешнего представления текстов. Первая задача — познакомить учеников с символьным алфавитом компьютера. Они должны знать, что — алфавит компьютера включает в себя 256 символов; — каждый символ занимает 1 байт памяти. Эти свойства символьного алфавита компьютера, в принципе, уже знакомы ученикам. Изучая алфавитный подход к измерению информации, они узнали, что один символ из алфавита мощностью 256 несет 8 бит, или 1 байт, информации, потому что 256 = 28. Но поскольку всякая информация представляется в памяти ЭВМ в двоичном виде, следовательно, каждый символ представляется 8-разрядным двоичным кодом. Существует 256 всевозможных 8-разрядных комбинаций, составленных из двух цифр «0» и «1» (в комбинаторике это называется числом размещений из 2 по 8 и равно 28): от 00000000 до 11111111. Удобство побайтового кодирования символов очевидно, поскольку байт — наименьшая адресуемая часть памяти и, следовательно, процессор может обратиться к каждому символу отдельно, выполняя обработку текста. С другой стороны, 256 символов — это вполне достаточное количество для представления самой разнообразной символьной информации. Далее следует ввести понятие о таблице кодировки. Таблица кодировки — это стандарт, ставящий в соответствие каждому символу алфавита свой порядковый номер. Наименьший номер — 0, наибольший — 255. Двоичный код символа — это его порядковый номер в двоичной системе счисления. Таким образом, таблица кодировки устанавливает связь между внешним символьным алфавитом компьютера и внутренним двоичным представлением. Международным стандартом для персональных компьютеров стала таблица ASCII. На практике можно встретиться и с другой таблицей — КОИ-8 (Код Обмена Информацией), которая используется в глобальных компьютерных сетях, на ЭВМ, работающих под управлением операционной системы Unix, а также на компьютерах типа PDP. К ним, в частности, относится отечественный школьный компьютер Электроника-УКНЦ. От учеников не нужно требовать запоминания кодов символов. Однако некоторые принципы организации кодовых таблиц они должны знать. Следует рассмотреть вместе с учениками таблицу кода ASCII, приведенную в ряде учебников и в справочниках. Она делится на две части. Международным стандартом является лишь первая половина таблицы, т.е. символы с номерами от 0 до 127. Сюда входят строчные и прописные буквы латинского алфавита, десятичные цифры, знаки препинания, всевозможные скобки, коммерческие и другие символы. Символы с номерами от 0 до 31 принято называть управляющими. Их функция — управление процессом вывода текста на экран или печать, подача звукового сигнала, разметка текста и т.п. Символ номер 32 — пробел, т.е. пустая позиция в тексте. Все остальные отражаются определенными знаками. Важно обратить внимание учеников на соблюдение лексикографического порядка в расположении букв латинского алфавита, а также цифр. На этом принципе основана возможность сортировки символьной информации, с которой ученики впервые встретятся, работая с базами данных. Вторая половина кодовой таблицы может иметь различные варианты. В первую очередь, она используется для размещения национальных алфавитов, отличных от латинского. Поскольку для кодировки русского алфавита — кириллицы, применяются разные варианты таблиц, то часто возникают проблемы с переносом русского текста с одного компьютера на другой, из одной программной системы в другую. Можно сообщить ученикам, что таблица кодировки символов 128 — 255 называется кодовой страницей и каждый ее вариант имеет свой номер. Так, например, в MS-DOS используется кодовая страница номер 866, а в Windows — номер 1251. В качестве дополнительной информации можно рассказать о том, что проблема стандартизации символьного кодирования решается введением нового международного стандарта, который называется Unicode. Это 16-разрядная кодировка, т.е. в ней на каждый символ отводится 2 байта памяти. Конечно, при этом объем занимаемой памяти увеличивается в два раза. Но зато такая кодовая таблица допускает включение до 65 536 символов. Ясно, что в нее можно внести всевозможные национальные алфавиты. Представление графической информации.Существуют два подхода к решению проблемы представления изображения на компьютере: растровый и векторный. Суть обоих подходов в декомпозиции, т.е. разбиении изображения на части, которые легко описать. Растровый подход предполагает разбиение изображения на маленькие одноцветные элементы — видеопиксели, которые, сливаясь, дают общую картину. В таком случае видеоинформация представляет собой перечисление в определенном порядке цветов этих элементов. Векторный подход разбивает всякое изображение на геометрические элементы: отрезки прямой, эллиптические дуги, фрагменты прямоугольников, окружностей, области однородной закраски и пр. При таком подходе видеоинформация — это математическое описание перечисленных элементов в системе координат, связанной с экраном дисплея. Векторное представление более всего подходит для чертежей, схем, штриховых рисунков. Нетрудно понять, что растровый подход универсальный, т.е. он применим всегда, независимо от характера изображения. В силу дискретной (пиксельной) структуры экрана монитора, в видеопамяти любое изображение представляется в растровом виде. На современных ПК используются только растровые дисплеи, работающие по принципу построчной развертки изображения. Информация в видеопамяти (видеоинформация) представляет собой совокупность кодов цвета каждого пикселя экрана. Отсюда следует, что вопрос о представлении изображения связан со способами кодирования цветов. Физический принцип получения разнообразных цветов на экране дисплея заключается в смешивании трех основных цветов: красного, зеленого и синего. Значит информация, заключенная в коде пикселя должна содержать сведения о том, какую интенсивность (яркость) имеет каждая составляющая в его цвете. Достаточно подробно этот вопрос раскрыт в учебнике [6]. Необходимо раскрыть перед учениками связь между кодом цвета и составом смеси базовых цветов. Следует начать с рассмотрения варианта восьмицветной палитры. В этом случае используется трехбитовый код и каждый бит такого кода обозначает наличие (1) или отсутствие (0) соответствующего базового цвета. В следующей таблице приведены коды восьмицветной палитры (табл. 9.1). Таблица 9.1 
Не нашли, что искали? Воспользуйтесь поиском по сайту: ©2015 - 2026 stydopedia.ru Все материалы защищены законодательством РФ.
|