|
|
Стандартные процедуры размещения и освобождения динамической памяти.
При выполнении программы наступает момент, когда необходимо использовать динамическую память, т.е. выделить её в нужных видах, разместить там какие-то данные, поработать с ними, а после того, как в данных отпадет необходимость - освободить выделенную память. Динамическая память может быть выделена двумя способами: 1. С помощью стандартной процедуры New: New (P); где р - переменная типа «типизированный указатель». Эта процедура создает новую динамическую переменную (выделяет под нее участок памяти) и устанавливает на нее указатель P (в P записывается адрес выделенного участка памяти). Размер и структура выделяемого участка памяти задается размером памяти для того типа данных, с которым связан указатель P. Доступ к значению созданной переменной можно получить с помощью P^.
2. С помощью стандартной процедуры GetMem. GetMem (P,size); где P - переменная типа «указатель» требуемого типа. size - целочисленное выражение размера запрашиваемой памяти в байтах.
Эта процедура создает новую динамическую переменную требуемого размера и свойства, а также помещает адрес этой созданной переменной в переменную Ртипа «указатель». Доступ к значению созданной переменной можно получить с помощью P^. Например: Type Rec =record Field1:string[30]; Field2:integer; end; ptr_rec = ^ rec; Var p : ptr_rec; Begin GetMem(Р, SizeOf (Rec)); { Выделение памяти, адрес выделенного участка фиксируется в Р; размер этой памяти в байтах определяет и возвращает стандартная функция SizeOf, примененная к описанному типу данных; однако, зная размеры внутреннего представления используемых полей, можно было бы подсчитать размер памяти «вручную» и записать в виде константы вместо SizeOf (Rec) } ... {использование памяти} ... FreeMem(p, SizeOf(Rec)); {освобождение уже ненужной памяти} ... Динамическая память может быть освобождена четырьмя способами. 1. Автоматически по завершении всей программы. 2. С помощью стандартной процедуры Dispose. Dispose (P); где P - переменная типа «указатель» (типизированный). В результате работы процедуры Dispose(P) участок памяти, связанный с указателем P, помечается как свободный для возможных дальнейших размещений. При этом физической чистки указателя P и связанной с ними памяти нe происходит, поэтому, даже удалив этот экземпляр записи, можно все же получить значения ее полей, однако использовать это обстоятельство не рекомендуется.
Ввиду различия в способах реализации процедуру Dispose не следует использовать совместно с процедурами Markи Release. 3. С помощью стандартной процедуры FRееМеm. FreeMem (P, size); где P - переменная типа «указатель», size - целочисленное выражение размера памяти в байтах для освобождения. Эта процедура помечает память размером, равным значению выражения size, связанную с указателем P, как свободную (см. пример для GetMem). 4. С помощью стандартных процедур Маrk и Release. Mark (P); Release (P); где P - переменная типа «указатель»; Mark - запоминает состояние динамической области в переменной-указателе р; Release - освобождает всю динамическую память, которая выделена процедурами New или GetMem после запоминания текущего значения указателя р процедурой Mark. Обращения к Markи Release нельзя чередовать с обращениями к Dispose и FRееМеm ввиду различий в их реализации.
Например: Var p:pointer; p1, p2, p3:^integer; Begin New(p1); p1^ := 10; Mark(p); {пометка динамической области} New(p2); p2^ := 25; New(p3); p3^ := p2^ + p1^; Writeln ( p3^); Release(p); {память, связанная с p2^ и p3^, освобождена, а p1^ может использоваться} End. Стандартные функции обработки динамической памяти.
В процессе выполнения программы может возникнуть необходимость наблюдения за состоянием динамической области. Цель такого наблюдения - оценка возможности очередного выделения динамической области требуемого размера. Для этих целей Турбо Паскаль предоставляет две функции (без параметров).
MaxAvail; Эта функция возвращает размер в байтах наибольшего свободного в данный момент участка в динамической области. По этому размеру можно судить о том, какую наибольшую динамическую память можно выделить. Тип возвращаемого значения - longint. type zap=record field1: string [20]; field2: real; end; var p: pointer; Begin ... if MaxAvail <SizeOf(zap) Then Writeln ('He хватает памяти!') Else GetMem(р, SizeOf(zap)); ... Вторая функция: MemAvail; Эта функция возвращает общее число свободных байтов динамической памяти, то есть суммируются размеры всех свободных участков и объем свободной динамической области. Тип возвращаемого значения - longint. ... Writeln( 'Доступно', MemAvail, 'байтов' ); Writeln('Наибольший свободный участок=', MaxAvail, 'байтов' ); ... Это решение основано на следующем обстоятельстве. Динамическая область размещается в специально выделяемой области, которая носит название «куча» (heap). Куча занимает всю или часть свободной памяти, оставшейся после загрузки программы. Размер кучи можно установить с помощью директивы компилятора М: {$М<стек>, <минимум кучи>, <максимум кучи>}
где <стек>- специфицирует размер сегмента стека в байтах. По умолчанию размер стека 16 384 байт, а максимальный размер стека 65 538 байт; <минимум кучи> - специфицирует минимально требуемый размер кучи в байтах; по умолчанию минимальный размер 0 байт; <максимум кучи> - специфицирует максимальное значение памяти в байтах для размещения кучи; по умолчанию оно равно 655 360 байт, что в большинстве случаев выделяет в куче всю доступную память; это значение должно быть не меньше наименьшего размера кучи.
Все значения задаются в десятичной или шестнадцатеричной формах. Например, следующие две директивы эквивалентны: {$М 16384,0,655360} {$M $4000, $0, $A000} Если указанный минимальный объем памяти недоступен, то программа выполняться не будет. Управление размещением в динамической памяти осуществляет администратор кучи, являющийся одной из управляющих программ модуля System.
Примеры и задачи.
Рассмотрим пример размещения и освобождения разнотипных динамических переменных в куче. Type st1=string[7]; st2=string[3]; var i,i1,i2,i3,i4:^integer; r^:real; s1:^st1; s2:^st2; Begin New(i); i1^:=1; New(i2); i2^:=2; New(i3); i3^=3; New(i4); i4^:=4; (*1*) Disроsе (i2);{освобождается второе размещение} New (i); {память нужного размера (в данном случае два байта) выделяется на первом свободном месте от начала кучи, достаточном для размещения данной переменной; в этом примере - это участок, который занимала переменная i2^, ее адрес остался в указателе i2 } i^:=5; (*2*) Dispose(i3); {освобождается третье размещение} New(r); {память под переменную типа real выделяется в вершине кучи, так как размер дырки с адресом i3 (2 байта) мал для размещения переменной типа real, для которой необходимо 6 байт } r^:=6; (*3*) writeln (r^); { ВЫВОД: 6.0000000000E+00} END. В следующем примере используется массив указателей. uses Crt; Var r: array [1..10] of ^real; i:1..10; Begin Randomize; {инициализация генератора случайных чисел} for i:=1 to 10 do Begin New(r[i]); r[i]^:=Random; {генерация случайных вещественных чисел в диапазоне 0 <= r[i]^ < 1} writeln(r[i]^);{Вывод случайных чисел в экспоненциальной форме} end; End. Работа с динамическими массивами.
При работе с массивами практически всегда возникает задача настройки программы на фактическое количество элементов массива. В зависимости от применяемых средств решение этой задачи бывает различным. Первый вариант -использование констант для задания размерностимассива.
Program First; Const N : integer = 10; { либо N = 10; } Var A : array [ 1..N ] of real; I : integer; Begin For i := 1 to N do Begin Writeln ('Введите', i , '-ый элемент массива'); Readln ( A [ i ] ) End; { И далее все циклы работы с массивом используют N} Такой способ требует перекомпиляции программы при каждом изменении числа обрабатываемых элементов. Второй вариант - программист планирует некоторое условно максимальное (теоретическое) количество элементов, которое и используется при объявлении массива. При выполнении программа запрашивает у пользователя фактическое количество элементов массива, которое должно быть не более теоретического. На это значение и настраиваются все циклы работы с массивом. Program Second; Var A : array [ 1..25 ] of real; I, NF : integer; Begin Writeln ('Введите фактическое число элементов’, ‘ массива <= 25'); Readln ( NF ); For i := 1 to NF do Begin Writeln ('Введите ',i, ' -ый элемент массива'); Readln ( A [ i ] ) End; { И далее все циклы работы с массивом используют NF} Этот вариант более гибок и технологичен по сравнению с предыдущим, так как не требуется постоянная перекомпиляция программы, но очень нерационально расходуется память, ведь ее объем для массива всегда выделяется по указанному максимуму. Используется же только часть ее Вариант третий - в нужный момент времени надо выделить динамическую память в требуемом объеме, а после того, как она станет не нужна, освободить ее. Program Dynam_Memory; Type Mas = array [ 1..2 ] of <требуемый_тип_элемента>; Ms = ^ mas; Var A : Ms; I, NF : integer; Begin Writeln ('Введите фактическое число элементов массива'); Readln ( NF ); GetMem ( A, SizeOf ( <требуемый_тип_элемента>)*NF); For i := 1 to NF do Begin Writeln ('Введите ', i , ' -ый элемент массива '); Readln ( A^ [ i ] ) End; { И далее все циклы работы с массивом используют NF} . . . . . FreeMem (a, nf*SizeOf (<требуемый_тип_элемента>)); End. Рассмотрим пример использования динамического одномерного массива, который используется как двумерный массив. После ввода реальной размерности массива и выделения памяти для обращения к элементу двумерного массива адрес его рассчитывается, исходя из фактической длины строки и положения элемента в строке (при заполнении матрицы по строкам). Требуется найти максимальный элемент в матрице и его координаты.
uses crt; type t1=array[1..1] of integer; Var a:^t1; n,m,i,j,k,p:integer; max:integer; Begin clrscr; write('n='); readln (n); write('m='); readln (m); getmem (a,sizeof(integer)*n*m); for i:=1 to n*m do read(a^[ i ]); max:=a^[1]; k:=1; p:=1; for i:=1 to n do for j:=1 to m do if a^[(i-1)*m+j] > max then Begin max:=a^[(i-1)*m+j]; k:=i; p:=j end; write('строка=',k:2,' столбец=',p:2); freemem(a,2*n*m); readkey; End.
В следующем примере для хранения двумерного массива используется одномерный массив указателей на столбцы. В задаче требуется найти столбцы матрицы, в которых находятся минимальный и максимальный элементы матрицы и если это разные столбцы, то поменять их местами.
uses crt; Type vk=^t1; t1=array[1..1] of integer; mt=^t2; t2=array[1..1] of vk; Var a:mt; m,n,i,j,k,l:integer; max,min:integer; r:pointer; Begin clrscr; readln (n,m); {выделение памяти под указатели столбцов матрицы} getmem(a,sizeof (pointer)*m); {выделение памяти под элементы столбцов} for j:=1 to m do getmem (a^[j],sizeof(integer)*n); for i:=1 to n do for j:=1 to m do read(a^[ j ]^[ i ]); for i:=1 to n do Begin for j:=1 to m do write (a^[ j ]^[ i ]:4); Writeln end; max:=a^[1]^[1]; k:=1; min:=max; l:=1; for j:=1 to m do for i:=1 to n do if a^[ j ]^[ i ]<min then Begin min:=a^[j]^[i]; l:=j; End Else if a^[ j ]^[ i ]>max then Begin max:=a^[j]^[i]; k:=j; end; {для обмена столбцов достаточно поменять указатели на столбцы} if k<>l then Begin r:=a^[k]; a^[k]:=a^[l]; a^[l]:=r end; for i:=1 to n do Begin for j:=1 to m do write(a^[j]^[i]:3,' '); Writeln end; for i:=1 to m do freemem (a^[ i ],n*sizeof(integer)); freemem (a,m*sizeof(pointer)) End. Организация списков.
Преимущества динамической памяти становятся особенно очевидными при организации динамических структур, элементы которых связаны через адреса (стеки, очереди, деревья, сети и т.д.). Основой моделирования таких структур являются списки.
Список - это конечное множество динамических элементов, размещающихся в разных областях памяти и объединенных в логически упорядоченную последовательность с помощью специальных указателей (адресов связи).
Список - структура данных, в которой каждый элемент имеет информационное поле (поля) и ссылку (ссылки), то есть адрес (адреса), на другой элемент (элементы) списка. Список - это так называемая линейная структура данных, с помощью которой задаются одномерные отношения.
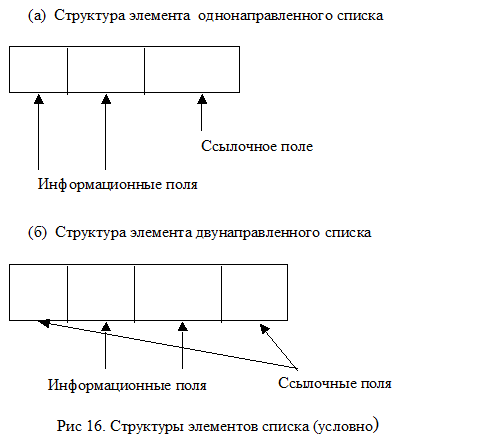
Каждый элемент списка содержит информационную и ссылочную части. Порядок расположения информационных и ссылочных полей в элементе при его описании - по выбору программиста, то есть фактически произволен. Информационная часть в общем случае может быть неоднородной, то есть содержать поля с информацией различных типов. Ссылки однотипны, но число их может быть различным в зависимости от типа списка. В связи с этим для описания элемента списка подходит только тип «запись», так как только этот тип данных может иметь разнотипные поля. Например, для однонаправленного списка элемент должен содержать как минимум два поля: одно поле типа «указатель», другое - для хранения данных пользователя. Для двунаправленного - три поля, два из которых должны быть типа «указатель».
Структура элемента линейного однонаправленного списка представлена на рисунке 16.
Следует рассмотреть разницу в порядке обработки элементов массива и списка.
Элементы массива располагаются в памяти в определенном постоянном порядке - подряд, друг за другом, что закрепляется их номерами. Каждый элемент массива имеет свое место, которое не может быть изменено, хотя значение элемента может изменяться. Порядок обработки элементов определяется использованием их номеров, индексов.
В отличие от элементов массива элементы списка могут располагаться в памяти в свободном порядке, не подряд. Порядок их обработки определяется ссылками, то есть в общем случае очередной элемент своей ссылкой указывает на тот элемент, который должен быть обработан следующим. Последний по порядку элемент содержит в ссылочной части признак, свидетельствующий о необходимости прекращения обработки элементов списка, указывающий как бы конец списка.
В зависимости от числа ссылок список называется одно-, двунаправленным и т.д.
В однонаправленном списке каждый элемент содержит ссылку на последующий элемент. Если последний элемент списка содержит «нулевую» ссылку, то есть содержит значение предопределенной константы nil и, следовательно, не ссылается ни на какой другой элемент, такой список называется линейным.
Для доступа к первому элементу списка, а за ним - и к последующим элементам необходимо иметь адрес первого элемента списка. Этот адрес обычно записывается в специальное поле - указатель на первый элемент, дадим ему специальное, «говорящее» имя - first. Если значение first равно nil, это значит, что список пуст, он не содержит ни одного элемента. Оператор first := nil; должен быть первым оператором в программе работы со списками. Он выполняет инициализацию указателя первого элемента списка, иначе говоря, показывает, что список пуст. Всякое другое значение будет означать адрес первого элемента списка (не путать с неинициализированным состоянием указателя).
Структура линейного однонаправленного списка показана на рисунке 17.
Если последний элемент содержит ссылку на первый элемент списка, то такой список называется кольцевым, циклическим. Изменения в списке при этом минимальны - добавляется ссылка с последнего на первый элемент списка: в адресной части последнего элемента значение Nilзаменяется на адрес первого элемента списка (см. рис. 18).
При обработке однонаправленного списка могут возникать трудности, связанные с тем, что по списку с такой организацией можно двигаться только в одном направлении, как правило, начиная с первого элемента. Обработка списка в обратном направлении сильно затруднена. Для устранения этого недостатка служит двунаправленный список, каждый элемент которого содержит ссылки на последующий и предыдущий элементы (для линейных списков - кроме первого и последнего элементов). Структура элемента представлена на рис. 1б.
Такая организация списка позволяет от каждого элемента двигаться по списку как в прямом, так и в обратном направлениях. Наиболее удобной при этом является та организация ссылок, при которой движение, перебор элементов в обратном направлении является строго противоположным перебору элементов в прямом направлении. В этом случае список называется симметричным. Например, в прямом направлении элементы линейного списка пронумерованы и выбираются так: 1, 2, 3, 4, 5. Строго говоря, перебирать элементы в обратном направлении можно по-разному, соответствующим способом организуя ссылки, например: 4, 1, 5, 3, 2. Симметричным же будет называться список, реализующий перебор элементов в таком порядке: 5, 4, 3, 2, 1.
Следует заметить, что «обратный» список, так же, как и прямой, является просто линейным однонаправленным списком, который заканчивается элементом со ссылкой, имеющей значение nil. Для удобства работы со списком в обратном направлении и в соответствии с идеологией однонаправленного списка нужен доступ к первому в обратном направлении элементу. Такой доступ осуществляется с помощью указателя LAST на этот первый в обратном направлении элемент. Структура линейного двунаправленного симметричного списка дана на рис. 19 .
Как указывалось ранее, замкнутый, циклический, кольцевой список организован таким образом, что в адресную часть конечного элемента вместо константы nil помещается адрес начального элемента (список замыкается на себя). В симметричном кольцевом списке такое положение характерно для обоих - прямого и обратного - списков, следовательно, можно построить циклический двунаправленный список (см. рис. 20 ) .
Описать элемент однонаправленного списка (см. рис 1) можно следующим образом: Type point=^zap; zap=record inf1 : integer; { первое информационное поле } inf2 : string; { второе информационное поле } next : point; {ссылочное поле } end;
Из этого описания видно, что имеет место рекурсивная ссылка: для описания типа point используется тип zap, а при описании типа zapиспользуется тип point. По соглашениям Паскаля в этом случае сначала описывается тип «указатель», а затем уже тип связанной с ним переменной. Правила Паскаля только при описании ссылок допускают использование идентификатора (zap) до его описания. Во всех остальных случаях, прежде чем упомянуть идентификатор, необходимо его определить.
Type point=^zap; zap=record inf1 : integer; { первое информационное поле } inf2 : string; { второе информационное поле } next:point; {ссылочное поле на следующий элемент} prev:point; {ссылочное поле на предыдущий элемент} end;
Как уже отмечалось, последовательность обработки элементов списка задается системой ссылок. Отсюда следует важный факт: все действия над элементами списка, приводящие к изменению порядка обработки элементов списка - вставка, удаление, перестановка - сводятся к действиям со ссылками. Сами же элементы не меняют своего физического положения в памяти.
При работе со списками любых видов нельзя обойтись без указателя на первый элемент. Не менее полезными, хотя и не всегда обязательными, могут стать адрес последнего элемента списка и количество элементов. Эти данные могут существовать по отдельности, однако их можно объединить в единую структуру типа «запись» (из-за разнотипности полей: два поля указателей на элементы и числовое поле для количества элементов). Эта структура и будет представлять так называемый головной элемент списка. Следуя идеологии динамических структур данных, головной элемент списка также необходимо сделать динамическим, выделяя под него память при создании списка и освобождая после окончания работы. Использование данных головного элемента делает работу со списком более удобной, но требует определенных действий по его обслуживанию.
Рассмотрим основные процедуры работы с линейным однонаправленным списком без головного элемента. Действия оформлены в виде процедур или функций в соответствии с основными требованиями модульного программирования (см. соответствующий раздел пособия).
Приведем фрагменты разделов Type и Var, необходимые для дальнейшей работы с линейным однонаправленным списком без головного элемента.
Type el = ^zap; zap=record inf1 : integer;{ первое информационное поле } inf2 : string; { второе информационное поле } next : el; {ссылочное поле } end; Var first, { указатель на первый элемент списка } p, q , t : el; { рабочие указатели, с помощью которых будет выполняться работа с элементами списка }

Не нашли, что искали? Воспользуйтесь поиском по сайту: ©2015 - 2026 stydopedia.ru Все материалы защищены законодательством РФ.
|