|
|
Проектирование программ по структурам данных
Проектирование программ по структурам данных можно считать одним из самых зрелых и продвинутых направлений в индустриальном отношении. Использование диаграмм Варнье, Джексона и МЭСИД для проектирования программ уже упоминалось ранее, а здесь остановимся несколько подробнее на использовании подхода МЭСИД для задач, относимых обычно к классу экономических. Все эти подходы основываются на создании диаграмм структур выходных и входных данных, определении несоответствий в них и путей устранения этих несоответствий через диаграмму структуры программы, составление списков операций и написание псевдокода (текста) программы. Одним из принципов в этих методологиях является упреждающее чтение записей. В языках программирования, в которых при N записях в последовательном файле об окончании записей становится известно при N + 1 чтении, такое программирование является более удобным. В этом случае чтение первой записи выполняется по началу программы, а остальные чтения осуществляются в блоках, где производится их обработка. Для языков, в которых признак окончания файла устанавливается для последней прочитанной записи, то есть требуется N чтений при N записях упомянутое неудобство устраняется чтением первой записи по началу программы и использованием дополнительно условного оператора для установки флага завершения файла в блоках, где производится их обработка. Другим способом является написание специальной подпрограммы, к которой производится N+1 обращение с получением флага завершенности файла и записи в целом или только необходимых полей. При использовании ряда языков четвертого поколения (4 GL) эта проблема решается автоматически. Одним из вариантов в подходе МЭСИД является следующая последовательность шагов с преобладающим направлением от выхода к входу и от физического к логическому: 1. Составление диаграммы структуры выходных данных. 2. Составление диаграммы структуры входных данных. 3. Составление диаграммы структуры программы с матрицей операций. 4. Заполнение матрицы операций. 5. Составление текста программы на языке программирования
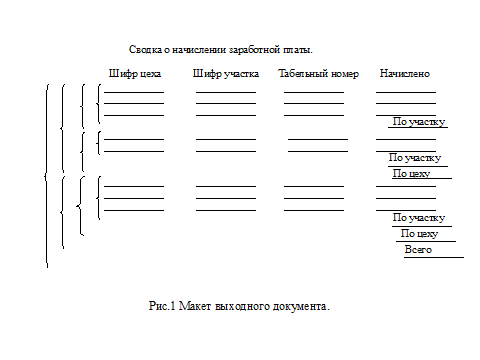
В основе составления спецификации помимо графических средств лежит активный контроль речевой деятельности, направленный на выделение сходных подмножеств и их синхронизацию и/или отношений 1:1, 1:M, M:N. Пусть имеется условный макет отчета (сводки) о начислении заработной платы рабочим-сдельщикам (рис. 1), в котором для каждого табельного номера (рабочего, исполнителя) выводится одна строка. Кроме итогов по табельным номерам выводятся итоги для участков, цехов и общий итог. Заголовок и «шапка» выводятся один раз в начале отчета. Обрабатываются все записи входного набора данных с последовательной организацией, упорядоченного по шифру цеха, шифру участка и табельному номеру. Кроме упомянутых элементов каждая запись включает шифр детали, номер операции, единицу измерения, нормированное время на единицу, расценку и количество.
Сначала произведем описание структуры выходных данных. Глядя на макет отчета, можно видеть, что самая частая строка отчета относится к табельному номеру (рабочему, исполнителю). Полями (элементами) всех этих строк являются шифр цеха, шифр участка, табельный номер и начислено. Низшим уровнем в иерархии является рабочий, а шифр цеха и шифр участка повторяются для разных рабочих в пределах участков и цехов. Таким образом, можно выделить (рис.2а) конструкцию повторения «табельный номер», в тело которой входят элементы шифр цеха, шифр участка, табельный номер и начислено. Зададим вопросы: «Что предшествует этой конструкции, что следует за ней, во что она входит?». Отвечая на эти вопросы, можно получить диаграмму (рис. 2б), затем диаграмму (рис.2в) и, наконец, диаграмму (рис.2г) которую можно прочитать примерно следующим образом: 1. Печать отчета начинается с вывода заголовка и шапки. 2. Производится вывод информации по цехам, по участкам, по табельным номерам. 3. При завершении участка выводится итог по участку. 4. При завершении цеха выводится итог по цеху. 5. При завершении файла (всей информации) выводится общий итог.
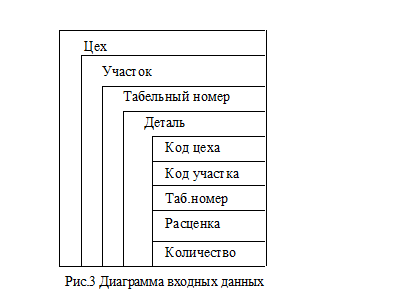
Построение диаграммы выходных данных настраивает на более внимательный анализ структуры входных данных. Возвращаясь к описанию входных данных, можно отметить, что упорядоченность последовательного файла по шифру цеха, шифру участка и табельному номеру соответствует порядку выделения подмножеств выходных данных. Отметим, однако, что упорядоченность по табельному номеру служит не только, и не столько, удобству чтения информации отчета, а формированию итоговой строки отчета для табельного номера, то есть одному полю «начислено» может соответствовать несколько записей входного файла об операциях, выполненных над определенными деталями. Кроме того, запись входного файла может содержать разнообразные поля, которые могут не иметь непосредственного отношения к формируемому отчету. В рассматриваемой задаче можно предположить, что для вычисления «начислено» будут значения расценки и количества (в случае неуверенности необходимо согласовать с постановщиком задачи). Таким образом, диаграмму входных данных (рис. 3) можно прочитать следующим образом: 1. Файл состоит из подмножеств записей, соответствующих цехам. 2. Эти подмножества состоят из подмножеств записей, соответствующих участкам. 3. Эти подмножества состоят из подмножеств записей, соответствующих табельным номерам. 4. Эти подмножества состоят из подмножеств записей, соответствующих обработанным деталям. 5. Каждая такая запись содержит информацию об обработанной детали, включая данные, необходимые для вычислений и идентификации подмножеств.
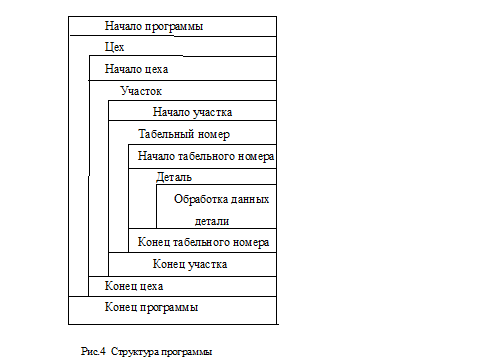
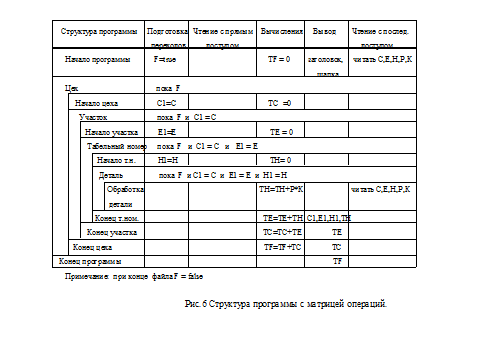
Сравнив иерархии в диаграммах выходных и входных данных, мы не видим существенных противоречий (например, различий в упорядоченности), что позволяет перейти к составлению диаграммы структуры программы. За основу этой структуры берется структура входных данных, каждое повторение и развилка которой наращиваются соответствующими началами и окончаниями (рис. 4). Диаграмма структуры программы является достаточно компактной, и ее можно дополнить матрицей операций, определяющей порядок действий программы на уровне псевдокода. Столбцы матрицы соответствуют категориям операций: 1. Чтение с прямым доступом. 2. Подготовка переходов. 3. Подготовка вычислений и вычисления. 4. Подготовка вывода, вывод и очистка. 5. Чтение с последовательным доступом. 6. Переходы. Категория «Чтение с прямым доступом» предназначена главным образом для извлечения данных из файлов прямого доступа для расширения состава полей записей последовательного файла. В нашем примере при необходимости работы с наименованиями цеха и участка после последовательного чтения основного файла мы могли бы задать чтение соответствующих справочников по началу цеха и по началу участка.
Категория «Подготовка переходов» связана в значительной степени с определением однородных в определенном смысле подмножеств записей входного файла. Так, например, печать итога по участку должна производиться, когда начинается другой участок или когда заканчивается файл. С этой целью определяется значение флажка окончания файла и фиксируется код участка. Категория «Подготовка вычислений и вычисления» связана главным образом с обнулением счетчиков и их наращиваем. Категория «Подготовка вывода, вывод и очистка» связана главным образом с выводом значений идентификации подмножества по его началу или/и окончанию. Так, при детальной печати распечатывается каждая запись входного файла, а при итоговой печати выводятся итоги для подмножеств и идентификаторы. В нашем примере на нижнем уровне выводится строка для табельного номера, когда это подмножество завершено и уже известны идентификаторы для следующего подмножества. По это причине необходимо запоминать эти идентификаторы на соответствующем уровне для последующего вывода. Этот процесс похож на подготовку переходов, и в ряде случаев поля подготовки переходов можно использовать и для вывода. Существует еще вид отчетов с индикацией группы, когда идентификаторы подмножеств и сопутствующие элементы выводятся в более детальной строке только при смене подмножества, а после этого в детальной строке остаются пробелы. В этом случае в поле(я) вывода по началу подмножества помещаются его идентификаторы, а после первого же вывода поля вывода заполняются пробелами.
Категория «Чтение с последовательным доступом» обычно связана с основным файлом, исчерпание которого приводит к завершению программы.
Категория «Переходы» в явном виде, в отличие от метода Варнье, может не использоваться, поскольку в диаграмме структуры программы имеются строки для соответствующих операторов управления.
Возникает, однако, вопрос, как связать эти диаграммы структур данных и программы на уровне полей. Допишем с этой целью на диаграммах достаточно короткие наименования полей записей и дополнительных переменных (рис.5).
Запись операций в матрице (рис.6) должна производиться с учетом различия частот выполнения блоков программы. Так, задавая вопросы, как часто и когда должно выполняться то или иное действие, можно определить его место в матрице. Например, операция ввода должна выполняться для каждой детали и еще один раз по началу программы, операция вывода заголовка и шапки должна выполняться один раз по началу программы и т.д.

Не нашли, что искали? Воспользуйтесь поиском по сайту: ©2015 - 2026 stydopedia.ru Все материалы защищены законодательством РФ.
|