
|
|
Модель выхода – обработка реализации случайных величин
При обработке выходной информации стохастических имитационных моделей чаще всего решают следующие задачи: · определение основных параметров полученной случайной выборки выходных данных (т.е. средних, дисперсии и т.д.); · определение формы и параметров закона распределения выходных характеристик; · определение статистической зависимости между входами и выходами модели и проверка существенности полученной связи. Для решения этих задач привлекается один из основных разделов математической статистики – теория испытания статистических гипотез. Смысл проверки статистических гипотез состоит в том, чтобы по имеющимся данным (случайной выборке) принять наиболее обоснованное решение о виде или параметрах генеральной совокупности. Статистические критерии – показатели, вычисляемые на основе фактических наблюдений и дающие основание для суждения и приемлемости некоторой гипотезы. При суждении о параметрах генеральной совокупности по определенному статистическому критерию принимают заранее некоторую наибольшую вероятность ошибки исследователя β. В соответствии с уровнем значимости β устанавливаются доверительные границы, в которых, судя по имеющимся статистическим данным, должен лежать искомый параметр генеральной совокупности. Эти границы (доверительные интервалы) будут тем уже, чем больше значений в имеющейся выборке и чем меньше доверительная вероятность. При этом считается, что все рассматриваемые данные имеют одинаковую точность измерений. Определение выборочного среднего и выборочной дисперсии случайной выборки статистических данных проводится в следующем порядке: · выборочное среднее · выборочная дисперсия; · для заданной доверительной вероятности αпо таблицам математической статистики определяется значение критерия Стьюдента t(α,f), зависящее от доверительной вероятности αи объема имеющихся статистических данных (f = N - 1); · определяются симметричные доверительные оценки выборочной средней. Критерий Стьюдента используется для определения доверительных интервалов в случае небольшого количества статистических данных N = 5…20. При N > 20 для определения доверительного интервала используется правило трех сигм:
Доверительную оценку средней квадратической ошибки σзаписывают в виде оценки относительного отклонения оцениваемого значения σот эмпирического стандарта S:
где значение доверительного коэффициента q (α, f)находится в зависимости от доверительной вероятности αи числа имеющихся статистических данных (f = N - 1) по соответствующим таблицам. Из всех критериев согласия наиболее часто применяется критерий χ2 (критерий Пирсона). По соответствующим математико-статистическим таблицам находят при данном числе степеней свободы f и доверительной вероятности αкритическое значение критерия χ2кр.Гипотеза о соответствии экспериментального закона распределения теоретическому считается непротиворечивой опыту при условии При использовании критерия χ2 необходимо, чтобы объем экспериментальных данных был больше 50, а количество их в каждом интервале – более 5. Для определения статистической зависимости между исследуемыми величинами и проверки полученной связи используют аппарат однофакторного и многофакторного регрессионного анализа. Эта задача эквивалентна решению задачи идентификации, где в качестве объекта рассматривается сама имитационная модель. В связи с тем, что при проведении экспериментов на ЭВМ неясно, какая из функций наилучшим образом описывает получающиеся данные, выбирают несколько таких функций, исходя из предположений о картине протекания исследуемого процесса:
где w – некоторая выходная характеристика модели; x– вектор входных параметров модели; 
Не нашли, что искали? Воспользуйтесь поиском по сайту: ©2015 - 2026 stydopedia.ru Все материалы защищены законодательством РФ.
|
 значенийслучайных величин x1, x2,…, xn;
значенийслучайных величин x1, x2,…, xn;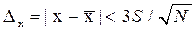 .
.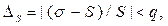
 .
.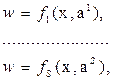
 – различные математические функции, описывающие взаимосвязь выхода w со входами x;
– различные математические функции, описывающие взаимосвязь выхода w со входами x;  – векторы параметров для соответствующих функций.
– векторы параметров для соответствующих функций.