
|
|
Градиентные алгоритмы обученияАлгоритм GD Алгоритм GD, или алгоритм градиентного спуска, используется для такой корректировки весов и смещений, чтобы минимизировать функционал ошибки, т. е. обеспечить движение по поверхности функционала в направлении, противоположном градиенту функционала по настраиваемым параметрам. Рассмотрим двухслойную нейронную сеть прямой передачи сигнала с сигмоидальным и линейным слоями для обучения ее на основе метода обратного распространения ошибки (рис. 3.7): net = newff([–1 2; 0 5],[3,1],{'tansig','purelin'},'traingd');
Рис. 3.7 Последовательная адаптация.Чтобы подготовить модель сети к процедуре последовательной адаптации на основе алгоритма GD, необходимо указать ряд параметров. В первую очередь это имя функции настройки learnFcn, соответствующее алгоритму градиентного спуска, в данном случае это М-функция learngd: net.biases{1,1}.learnFcn = 'learngd'; net.biases{2,1}.learnFcn = 'learngd'; net.layerWeights{2,1}.learnFcn = 'learngd'; net.inputWeights{1,1}.learnFcn = 'learngd'; С функцией learngd связан лишь один параметр скорости настройки lr. Текущие приращения весов и смещений сети определяются умножением этого параметра на вектор градиента. Чем больше значение параметра, тем больше приращение на текущей итерации. Если параметр скорости настройки выбран слишком большим, алгоритм может стать неустойчивым; если параметр слишком мал, то алгоритм может потребовать длительного счета. При выборе функции learngd по умолчанию устанавливается следующее значение net.layerWeights{2,1}.learnParam ans = lr: 0.01 Увеличим значение этого параметра до 0.2: net.layerWeights{2,1}.learnParam.lr = 0.2; Мы теперь почти готовы к обучению сети. Осталось задать обучающее множество. Это простое множество входов и целей определим следующим образом: p = [–1 –1 2 2;0 5 0 5]; t = [–1 –1 1 1]; Поскольку используется последовательный способ обучения, необходимо преобразовать массивы входов и целей в массивы ячеек: p = num2cell(p,1); t = num2cell(t,1); Последний параметр, который требуется установить при последовательном обучении, – это число проходов net.adaptParam.passes: net.adaptParam.passes = 50; Теперь можно выполнить настройку параметров, используя процедуру адаптации: [net,a,e] = adapt(net,p,t); Чтобы проверить качество обучения, после окончания обучения смоделируем сеть: a = sim(net,p) a = [–1.02] [–0.99624] [1.0279] [1.0021] mse(e) ans = 5.5909e–004 Групповое обучение.Для обучения сети на основе алгоритма GD необходимо использовать М-функцию traingd взамен функции настройки learngd. В этом случае нет необходимости задавать индивидуальные функции обучения для весов и смещений, а достаточно указать одну обучающую функцию для всей сети. Вновь создадим ту же двухслойную нейронную сеть прямой передачи сигнала с сигмоидальным и линейным слоями для обучения по методу обратного распространения ошибки: net = newff([–1 2; 0 5],[3,1],{'tansig','purelin'},'traingd'); Функция traingd характеризуется следующими параметрами, заданными по умолчанию: net.trainParam ans = epochs: 100 goal: 0 lr: 1.0000e–002 max_fail: 5 min_grad: 1.0000e–010 show: 25 time: Inf Здесь epochs – максимальное количество циклов (эпох) обучения; goal – предельное Установим новые значения параметров обучения, зададим обучающую последовательность в виде массива double и выполним процедуру обучения: net.trainParam.show = 50; net.trainParam.lr = 0.05; net.trainParam.epochs = 300; net.trainParam.goal = 1e–5; p = [–1 –1 2 2;0 5 0 5]; t = [–1 –1 1 1]; net = train(net,p,t); % Рис.3.8 На рис. 3.8 приведен график изменения ошибки в зависимости от числа выполненных циклов обучения. Этот график строится автоматически при исполнении функции train.
Для проверки качества обучения промоделируем спроектированную сеть: a = sim(net,p) a = –1.0042 –0.9958 0.9987 0.9984 Более тщательно ознакомиться с методом градиентного спуска можно с помощью Алгоритм GDM Алгоритм GDM, или алгоритм градиентного спуска с возмущением [18], предназначен для настройки и обучения сетей прямой передачи. Этот алгоритм позволяет преодолевать локальные неровности поверхности ошибки и не останавливаться в локальных минимумах. С учетом возмущения метод обратного распространения ошибки реализует следующее соотношение для приращения вектора настраиваемых параметров:
где Если параметр возмущения равен 0, то изменение вектора настраиваемых параметров определяется только градиентом, если параметр равен 1, то текущее приращение равно предшествующему как по величине, так и по направлению. Вновь рассмотрим двухслойную нейронную сеть прямой передачи сигнала с сигмоидальным и линейным слоями (см. рис. 2.6) net = newff([–1 2; 0 5],[3,1],{'tansig','purelin'},'traingdm'); Последовательная адаптация. Чтобы подготовить модель сети к процедуре последовательной адаптации на основе алгоритма GDM, необходимо указать ряд параметров. net.biases{1,1}.learnFcn = 'learngdm'; net.biases{2,1}.learnFcn = 'learngdm'; net.layerWeights{2,1}.learnFcn = 'learngdm'; net.inputWeights{1,1}.learnFcn = 'learngdm'; С этой функцией связано 2 параметра – параметр скорости настройки lr и параметр возмущения mc. При выборе функции learngdm по умолчанию устанавливаются следующие значения этих параметров: net.layerWeights{2,1}.learnParam ans = lr: 0.01 mc: 0.9 Увеличим значение параметра скорости обучения до 0.2: net.layerWeights{2,1}.learnParam.lr = 0.2; Мы теперь почти готовы к обучению сети. Осталось задать обучающее множество p = [–1 –1 2 2;0 5 0 5]; t = [–1 –1 1 1]; p = num2cell(p,1); t = num2cell(t,1); net.adaptParam.passes = 50; tic, [net,a,e] = adapt(net,p,t); toc elapsed_time = 4.78 a, mse(e) ans = [–1.0124] [–0.98648] [1.0127] [0.9911] ans = 1.4410e–004 Эти результаты сравнимы с результатами работы алгоритма GD, рассмотренного ранее. Групповое обучение. Альтернативой последовательной адаптации является групповое обучение, которое основано на применении функции train. В этом режиме параметры сети модифицируются только после того, как реализовано все обучающее множество, и градиенты, рассчитанные для каждого элемента множества, суммируются, чтобы определить приращения настраиваемых параметров. Для обучения сети на основе алгоритма GDM необходимо использовать М-функцию traingdm взамен функции настройки learngdm. Различие этих двух функций состоит Вновь обратимся к той же сети net = newff([–1 2; 0 5],[3,1],{'tansig','purelin'},'traingdm'); Функция traingdm характеризуется следующими параметрами, заданными по умолчанию: net.trainParam ans = epochs: 100 goal: 0 lr: 0.0100 max_fail: 5 mc: 0.9000 min_grad: 1.0000e–010 show: 25 time: Inf По сравнению с функцией traingd здесь добавляется только 1 параметр возмущения mc. Установим следующие значения параметров обучения: net.trainParam.epochs = 300; net.trainParam.goal = 1e–5; net.trainParam.lr = 0.05; net.trainParam.mc = 0.9; net.trainParam.show = 50; p = [–1 –1 2 2;0 5 0 5]; t = [–1 –1 1 1]; net = train(net,p,t); % Рис. 3.9 На рис. 3.9 приведен график изменения ошибки обучения в зависимости от числа
a = sim(net,p) a = –0.9956 –0.9998 0.9969 1.0009 Поскольку начальные веса и смещения инициализируются случайным образом, графики ошибок на рис. 3.8 и 3.9 будут отличаться от одной реализации к другой. Более тщательно ознакомиться с методом градиентного спуска с возмущением можно с помощью демонстрационной программы nnd12mo, которая иллюстрирует работу алгоритма GDM. Практика применения описанных выше алгоритмов градиентного спуска показывает, что эти алгоритмы слишком медленны для решения реальных задач. Ниже обсуждаются алгоритмы группового обучения, которые сходятся в десятки и сотни раз быстрее. Ниже представлены 2 разновидности таких алгоритмов: один основан на стратегии выбора параметра скорости настройки и реализован в виде алгоритма GDA, другой – на стратегии выбора шага с помощью порогового алгоритма обратного распространения ошибки и реализован в виде алгоритма Rprop. Алгоритм GDA Алгоритм GDA, или алгоритм градиентного спуска с выбором параметра скорости настройки, использует эвристическую стратегию изменения этого параметра в процессе обучения. Эта стратегия заключается в следующем. Вычисляются выход и погрешность инициализированной нейронной сети. Затем на каждом цикле обучения вычисляются новые Эта стратегия способствует увеличению скорости и сокращению длительности обучения. Алгоритм GDA в сочетании с алгоритмом GD определяет функцию обучения traingda, а в сочетании с алгоритмом GDM – функцию обучения traingdx. Вновь обратимся к той же нейронной сети (см. рис. 3.8), но будем использовать функцию обучения traingda: net = newff([–1 2; 0 5],[3,1],{'tansig','purelin'},'traingda'); Функция traingda характеризуется следующими параметрами, заданными по умолчанию: net.trainParam ans = epochs: 100 goal: 0 lr: 0.0100 lr_inc: 1.0500 lr_dec: 0.7000 max_fail: 5 max_perf_inc: 1.0400 min_grad: 1.0000e–006 show: 25 Здесь epochs – максимальное количество циклов обучения; goal – предельное значение критерия обучения; lr – параметр скорости настройки; lr_inc – коэффициент увеличения скорости настройки; lr_dec – коэффициент уменьшения скорости настройки; max_fail – максимально допустимый уровень превышения ошибки контрольного подмножества по сравнению с обучающим; max_perf_inc – пороговый коэффициент отношения погрешностей; min_grad – минимальное значение градиента; show – интервал вывода информации, измеренный в циклах; time – предельное время обучения. Установим следующие значения этих параметров: net.trainParam.epochs = 300; net.trainParam.goal = 1e–5; net.trainParam.lr = 0.05; net.trainParam.mc = 0.9; net.trainParam.show = 50; p = [–1 –1 2 2;0 5 0 5]; t = [–1 –1 1 1]; net = train(net,p,t); % Рис. 3.10 На рис. 3.10 приведен график изменения ошибки обучения в зависимости от числа
a = sim(net,p) a = –0.9959 –1.0012 0.9963 0.9978 Нетрудно заметить, что количество циклов обучения по сравнению с предыдущим примером сократилось практически в 3 раза при сохранении той же погрешности обучения. Демонстрационная программа nnd12vl иллюстрирует производительность алгоритма Алгоритм Rprop Алгоритм Rprop, или пороговый алгоритм обратного распространения ошибки, Многослойные сети обычно используют сигмоидальные функции активации в скрытых слоях. Эти функции относятся к классу функций со сжимающим отображением, поскольку они отображают бесконечный диапазон значений аргумента в конечный диапазон значений функции. Сигмоидальные функции характеризуются тем, что их наклон приближается к нулю, когда значения входа нейрона существенно возрастают. Следствием этого является то, что при использовании метода наискорейшего спуска величина градиента становится малой и приводит к малым изменениям настраиваемых параметров, даже если они далеки от оптимальных значений. Цель порогового алгоритма обратного распространения ошибки Rprop (Resilient propagation) [36] состоит в том, чтобы повысить чувствительность метода при больших значениях входа функции активации. В этом случае вместо значений самих производных используется только их знак. Значение приращения для каждого настраиваемого параметра увеличивается с коэффициентом delt_inc (по умолчанию 1.2) всякий раз, когда производная функционала ошибки по данному параметру сохраняет знак для двух последовательных итераций. Алгоритм Rprop определяет функцию обучения trainrp. Вновь обратимся к сети, показанной на рис. 3.8, но будем использовать функцию net = newff([–1 2; 0 5],[3,1],{'tansig','purelin'},trainrp'); Функция trainrp характеризуется следующими параметрами, заданными по умолчанию: net.trainParam ans = epochs: 100 show: 25 goal: 0 time: Inf min_grad: 1.0000e–006 max_fail: 5 delt_inc: 1.2000 delt_dec: 0.5000 delta0: 0.0700 deltamax: 50 Здесь epochs – максимальное количество циклов обучения; show – интервал вывода информации, измеренный в циклах; goal – предельное значение критерия обучения; time – предельное время обучения; min_grad – минимальное значение градиента; max_fail – максимально допустимый уровень превышения ошибки контрольного подмножества по сравнению с обучающим; delt_inc – коэффициент увеличения шага настройки; delt_dec – коэффициент уменьшения шага настройки; delta0 – начальное значение шага настройки; deltamax – максимальное значение шага настройки. Установим следующие значения этих параметров: net.trainParam.show = 10; net.trainParam.epochs = 300; net.trainParam.goal = 1e–5; p = [–1 –1 2 2;0 5 0 5]; t = [–1 –1 1 1]; net = train(net,p,t); % Рис.3.11 На рис. 3.11 приведен график изменения ошибки обучения в зависимости от числа выполненных циклов обучения.
a = sim(net,p) a = –0.9974 –1.0010 0.9995 0.9984 Нетрудно заметить, что количество циклов обучения по сравнению с алгоритмом GDA сократилось практически еще в 3 раза и составило по отношению к алгоритму GD значение, близкое к 8.5. 
Не нашли, что искали? Воспользуйтесь поиском по сайту: ©2015 - 2026 stydopedia.ru Все материалы защищены законодательством РФ.
|
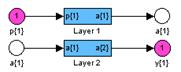
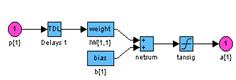
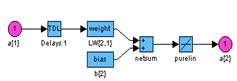
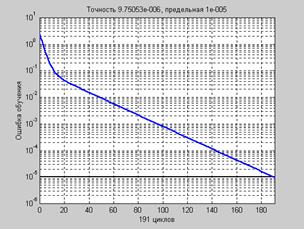 Рис. 3.8
Рис. 3.8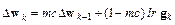 , (3.21)
, (3.21) – приращение вектора весов; mc – параметр возмущения; lr – параметр скорости обучения;
– приращение вектора весов; mc – параметр возмущения; lr – параметр скорости обучения;  – вектор градиента функционала ошибки на k-й итерации.
– вектор градиента функционала ошибки на k-й итерации.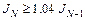 , то параметр возмущения mc следует установить в 0.
, то параметр возмущения mc следует установить в 0.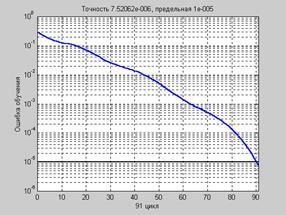 Рис. 3.9
Рис. 3.9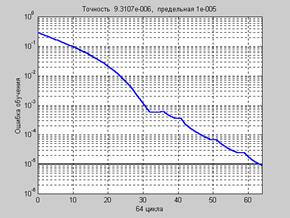 Рис. 3.10
Рис. 3.10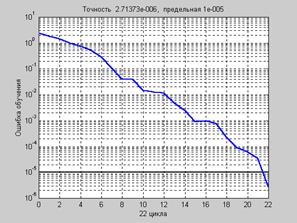 Рис. 3.11
Рис. 3.11