|
|
Технологии распределенной обработки DDPВопрос об использовании распределенных систем обработки данных стал актуален с появлением мощных вычислительных систем с распределенными ресурсами в пределах одного компьютера, локальных корпоративных и внешних (региональных и глобальных) сетей, технологий поиска и многомерного анализа данных, развитием Web-технологий. Использование технологий распределенной обработки данных (Distributed Data Processing — DDP) стало особенно актуально для высокотехнологичных географически распределенных компаний, деятельность которых поддерживается и сопровождается современными ИТ и системами. Суть распределенной обработки данных заключается в том, что пользователь получает возможность работать с базами и хранилищами данных, прикладными процессами программами и сервисами, расположенными в нескольких взаимосвязанных оконечных системах. При этом возможны следующие виды работ: - удаленный запрос, например, посылка команды пользователя на выполнение задания, связанного с обработкой данных;
Рис. Пример использования технологий распределенной обработки данных — DDP - удаленное действие (Transaction), осуществляющее направление группы запросов прикладному процессу; это может быть, например, часть вычислительного процесса, использующего удаленную базу данных; - распределенная трансакция, дающая возможность использования нескольких серверов и прикладных процессов, выполняемых в группе оконечных систем; - обработка в системе «клиент-сервер».
Существует несколько технологий распределенной обработки, которые могут использовать как промежуточный слой программного обеспечения, ориентированного на запросы и сообщения, так и распределенную интегрированную среду обработки данных. Первая технология является самой простой, но возможности ее ограничены взаимодействием с одним из выбранных серверов приложений. Технологии второго типа предусматривают совместную работу клиентов с одним или с группой серверов. При этом некоторые серверы могут выступать в роли клиентов для других серверов. Для распределенной обработки осуществляется тематическая сегментация прикладных программ. Для работы в реальном времени используется протокол резервирования ресурсов и предоставляется специализированное инструментальное программное обеспечение распределенной среды обработки данных. Способы конкретной организации процессов обработки и технические решения чрезвычайно разнообразны, однако архитектура таких систем является, как правило, двух- или трехзвенной архитектурой «клиент-сервер» (Client-Server Architecture — CSA).
Системы на основе технологий "Клиент-сервер" исторически выросли из первых централизованных многопользовательских автоматизированных информационных систем, интенсивно развивавшихся в 70-х годах (системы mainframe), и получили, вероятно, наиболее широкое распространение в сфере информационного обеспечения крупных предприятий и корпораций. В технологиях "Клиент-сервер" отступают от одного из главных принципов создания и функционирования распределенных систем - отсутствия центральной установки. Поэтому можно выделить две основные идеи, лежащие в основе клиент-серверных технологий: - общие для всех пользователей данные на одном или нескольких серверах; - много пользователей (клиентов), на различных вычислительных установках, совместно (параллельно и одновременно) обрабатывающих общие данные. Иначе говоря, системы, основанные на технологиях "Клиент-сервер", распределены только в отношении пользователей, поэтому часто их не относят к "настоящим" распределенным системам, а считают отдельным классом многопользовательских систем. Важное значение в технологиях "Клиент-сервер" имеют понятия сервера и клиента. Под сервером в широком смысле понимается любая система, процесс, компьютер, владеющие каким-либо вычислительным ресурсом (памятью, временем, производительностью процессора и т. д.). Клиентом называется также любая система, процесс, компьютер, пользователь, запрашивающие у сервера какой-либо ресурс, пользующиеся каким-либо ресурсом или обслуживаемые сервером иным способом. В своем развитии системы "Клиент-сервер" прошли несколько этапов, в ходе которых сформировались различные модели систем "Клиент-сервер". Их реализация и, следовательно, правильное понимание основаны на разделении структуры СУБД на три компонента: - компонент представления, реализующий функции ввода и отображения данных, называемый иногда еще просто как интерфейс пользователя; - прикладной компонент, включающий набор запросов, событий, правил, процедур и других вычислительных функций, реализующий предназначение автоматизированной информационной системы в конкретной предметной области; - компонент доступа к данным, реализующий функции хранения-извлечения, физического обновления и изменения данных. Исходя из особенностей реализации и распределения в системе этих трех компонентов различают четыре модели технологий "Клиент-сервер": - модель файлового сервера (File Server - FS); - модель удаленного доступа к данным (Remote Data Access - RDA); - модель сервера базы данных (DataBase Server - DBS); - модель сервера приложений (Application Server - AS). Модель файлового сервера
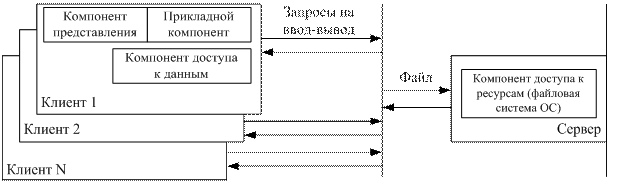
Модель файлового сервера является наиболее простой и характеризует не столько способ образования информационной системы, сколько общий способ взаимодействия компьютеров в локальной сети. Один из компьютеров сети выделяется и определяется файловым сервером, т. е. общим хранилищем любых данных. Суть FS- модели иллюстрируется схемой, приведенной на рис. 5.3.
Рис 5.3 - Модель файлового сервера
В FS-модели все основные компоненты размещаются на клиентской установке. При обращении к данным ядро СУБД, в свою очередь, обращается с запросами на ввод-вывод данных за сервисом к файловой системе. С помощью функций операционной системы в оперативную память клиентской установки полностью или частично на время сеанса работы копируется файл базы данных. Таким образом, сервер в данном случае выполняет чисто пассивную функцию. Достоинством данной модели являются ее простота, отсутствие высоких требований к производительности сервера (главное, требуемый объем дискового пространства). Следует также отметить, что программные компоненты СУБД в данном случае не распределены, т.е. никакая часть СУБД на сервере не инсталлируется и не размещается. Недостатки данной модели - высокий сетевой трафик, достигающий пиковых значений особенно в момент массового вхождения в систему пользователей, например в начале рабочего дня. Однако более существенным недостатком, с точки зрения работы с общей базой данных, является отсутствие специальных механизмов безопасности файла (файлов) базы данных со стороны СУБД. Иначе говоря, разделение данных между пользователями (параллельная работа с одним файлом данных) осуществляется только средствами файловой системы ОС для одновременной работы нескольких прикладных программ с одним файлом. Несмотря на очевидные недостатки, модель файлового сервера является естественным средством расширения возможностей персональных (настольных) СУБД в направлении поддержки многопользовательского режима и, очевидно, в этом плане еще будет сохранять свое значение.

Не нашли, что искали? Воспользуйтесь поиском по сайту: ©2015 - 2026 stydopedia.ru Все материалы защищены законодательством РФ.
|