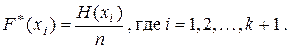|
|
Эмпирическая функция распределения12 МАТЕМАТИЧЕСКАЯ СТАТИСТИКА
Методы сбора, систематизации, обработки и использования эмпирических данных - результатов наблюдений массовых случайных явлений, выявление статистических закономерностей составляют основное содержание математической статистики. В отличие от теории вероятностей, которая позволяет выявить те или иные свойства случайных событий путем абстрактного, логического анализа, не проводя эксперимента, в математической статистике любое исследование связано с эмпирическими данными и идет от практики к гипотезе и ее проверке. Методы математической статистики позволяют решать следующие задачи: - изучение всей совокупности по некоторому числу случайно отобранных объектов или случайно выбранных значений признака (выборочный метод); - нахождение и сравнение приближенных значений числовых характеристик статистических распределений (статистическое оценивание); - построение теоретического распределения значений изучаемого признака по эмпирическим данным и проверка его согласия с эмпирическими данными (критерии согласия); - установление формы и тесноты взаимосвязи между изучаемыми признаками (корреляционный и регрессионный анализ). Методы математической статистики основываются на возможности вероятностной интерпретации изучаемых совокупностей. Теоретической основой математической статистики является теория вероятностей.
ВЫБОРОЧНЫЙ МЕТОД
Понятие о выборочном методе
Исходным материалом любого статистического исследования является статистическая совокупность. Статистической совокупностью называют подлежащее статистическому изучению множество однородных объектов, объединенных с целью изучения некоторого признака, присущего всем объектам совокупности. Отдельные объекты этой совокупности называют элементами, или единицами, совокупности, а их число - объемом совокупности. Например, в качестве статистической совокупности можно назвать совокупность студентов академии, элементами здесь являются студенты, рассматриваемые в отдельности, а объемом совокупности - численность студентов; признаками совокупности могут быть возраст студентов, их рост, успеваемость и т.д. Признаки принято обозначать прописными буквами латинского алфавита Х,У, ..., как и случайные величины. Значения признака при переходе от одного элемента совокупности к другому изменяются, то есть варьируют. Различные значения признака называют вариантами и обозначают соответствующими строчными буквами с индексом. Признаки могут быть количественными или качественными. Например, количественный признак - рост студентов или их возраст, а качественный - успеваемость (успевает, не успевает). Статистическое наблюдение, в результате которого получают значения признака, являющиеся элементами совокупности, может быть сплошным или выборочным. При сплошном наблюдении изучается каждый элемент всей исходной совокупности. Однако сплошное наблюдение может оказаться либо просто невозможно или связано с большими материальными и временными затратами, если объем совокупности велик; либо лишено смысла в том случае, если при наблюдении элементы совокупности уничтожаются (например, исследование прочности материала, продолжительности горения электроламп и т.д.). Поэтому на практике используют выборочное наблюдение. Для этого из исходной совокупности, которую принято называть генеральной, случайным образом выбирается ее часть, называемая выборочной совокупностью, или выборкой, все элементы которой подвергаются сплошному наблюдению. Объем генеральной совокупности обозначают N, а объем выборки - n Чтобы выборка как можно точнее воспроизводила свойства генеральной совокупности, она должна быть репрезентативной (представительной). Из закона больших чисел следует, что выборка будет репрезентативной, если она случайна и все элементы выборки имеют одинаковую вероятность попасть в выборку; имеет достаточно большой объем; однородна по рассеянию значений элементов. По характеру отбора элементов различают выборки повторные и бесповторные. В повторной выборке элементы после изучения (то есть после определения количественных характеристик признака) возвращаются в генеральную совокупность, в бесповторной - не возвращаются. Если выборка по своему объему составляет незначительную часть генеральной совокупности, что чаще всего и бывает на практике, то сколько-нибудь существенного различия между повторной и бесповторной выборками нет.
Вариационный ряд. Статистические распределения. Эмпирическая функция распределения
Полученная в результате статистического наблюдения выборка из n значений (вариант) изучаемого количественного признака X образует вариационный ряд. Ранжированный вариационный ряд получают, расположив варианты xj , где j=1, 2, ... , n, в порядке возрастания (неубывания) значений, то есть Изучаемый признак X может быть дискретным, то есть его значения отличаются на конечную, заранее известную величину (год рождения, тарифный разряд, число людей), или непрерывным, то есть его значения отличаются на сколь угодно малую величину (время, вес, объем, стоимость). Частотой mi в случае дискретного признака X называют число одинаковых вариант xi, содержащихся в выборке. В ранжированном вариационном ряду одинаковые варианты очевидно расположены подряд:
Вариационный ряд для дискретного признака X принято наглядно и компактно представлять в виде таблицы, в первой строке которой указаны k различных значений xi изучаемого признака, а во второй строке - соответствующие этим значениям частоты mi , где i =1, 2, ... , k. Такую таблицу называют статистическим (выборочным) распределением. Переход от исходного вариационного ряда дискретного признака X к соответствующему статистическому распределению поясним на простом примере. Вариационный ряд, полученный в результате статистического наблюдения (единицы измерения опускаем), - 7, 17, 14, 17, 10, 7, 7, 14, 7, 14. Ранжированный вариационный ряд - Тогда соответствующее статистическое распределение (i = 1, 2, ..., k, k=4) примет вид
Статистическое распределение для непрерывного признака X принято представлять интервальным рядом - таблицей, в первой строке которой указаны k интервалов значений изучаемого признака X вида(xi-1 - xi ), а во второй строке - соответствующие этим интервалам частоты mi , где i=1, 2, ..., k. Обозначение (xi-1 - xi ) указывает не разности, а все значения признака X от xi-1 до xi , кроме правой границы интервала xi . Для непрерывного признака X частота mi - число различных xj , попавших в соответствующий интервал (xi-1 - xi ). Переход от исходного вариационного ряда непрерывного признака X к соответствующему статистическому распределению поясним на простом примере. Вариационный ряд, полученный в результате статистического наблюдения (единицы измерения опускаем), - 3,14; 1,41; 2,87; 3,62; 2,71; 3,95. Ранжированный вариационный ряд - 1,41; 2,71; 2,87; 3,14; 3,62; 3,95. Получим соответствующее статистическое распределение (i=1, 2, …, k, k = 3)
Если число различных значений дискретного признака очень велико, то для удобства дальнейших вычислений и наглядности статистическое распределение такого дискретного признака также может быть представлено в виде интервального ряда. Вместо частот mi во второй строке могут быть указаны относительные частоты
Далее показаны четыре возможные формы представления статистических распределений с соответствующими краткими названиями.
Если в статистическом распределении вместо частот (относительных частот) указать накопленные частоты (относительные накопленные частоты), то такой ряд распределения называют кумулятивным. Накопленной частотой называется число значений признака Х, меньших заданного значения x: H(x) = m(Х< x), то есть число вариант xj в выборке, отвечающих условию xj < x. Переход от дискретного ряда частот к кумулятивному ряду (дискретному ряду накопленных частот) задается соотношениями
или в табличной форме:
Переход от интервального ряда частот к кумулятивному ряду (интервальному ряду накопленных частот) задается соотношениями
или в табличной форме:
Накопленной относительной частотой (накопленной частостью) называется отношение числа значений признака Х, меньших заданного значения x, к объему выборки n: По аналогии с теоретической функцией распределения генеральной совокупности Из теоремы Бернулли следует, что
поэтому эмпирическую функцию распределения можно использовать для оценки теоретической функции распределения генеральной совокупности. Дискретный ряд накопленных относительных частот может быть получен двумя равноправными способами: 1) переход от дискретного ряда частостей к кумулятивному ряду (дискретному ряду накопленных частостей) описывается соотношениями
или в табличной форме:
2) переход от дискретного ряда накопленных частот к дискретному ряду накопленных частостей задается соотношением
Интервальный ряд накопленных относительных частот может быть получен двумя равноправными способами: 1) переход от интервального ряда частостей к кумулятивному ряду (интервальному ряду накопленных частостей) задается соотношениями
или в табличной форме:
2) переход от интервального ряда накопленных частот к интервальному ряду накопленных частостей задается соотношением

12 Не нашли, что искали? Воспользуйтесь поиском по сайту: ©2015 - 2026 stydopedia.ru Все материалы защищены законодательством РФ.
|
 .
. .
.
 .
. (частости). Очевидно, что сумма частот равна объему выборки (выборочной совокупности) n, а сумма относительных частот (частостей) равна единице:
(частости). Очевидно, что сумма частот равна объему выборки (выборочной совокупности) n, а сумма относительных частот (частостей) равна единице:
 .
.
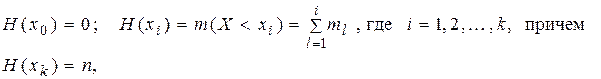
 , то есть доля вариант xj в выборке, отвечающих условию xj < x.
, то есть доля вариант xj в выборке, отвечающих условию xj < x. = P(Х <
= P(Х <  ), которая определяет вероятность события Х <
), которая определяет вероятность события Х <  , вводят понятие эмпирической функции распределения
, вводят понятие эмпирической функции распределения 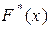 , которая определяет относительную частоту этого же события Х <
, которая определяет относительную частоту этого же события Х <  . Таким образом, эмпирическая функция распределения
. Таким образом, эмпирическая функция распределения 

 (xi)
(xi)