
|
|
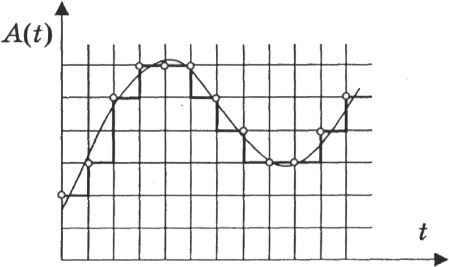
Нетрадиционная ориентацияВременная дискретизация звука Для того чтобы компьютерные системы могли обрабатывать звук, непрерывный звуковой сигнал должен быть преобразован в цифровую, дискретную форму с помощью временной дискретизации. Для этого, непрерывная звуковая волна разбивается на отдельные маленькие временные участки, для каждого такого участка устанавливается определенная величина интенсивности звука. Таким образом, непрерывная зависимость громкости звука от времени A(t) заменяется на дискретную последовательность уровней громкости. На графике это выглядит как замена гладкой кривой на последовательность «ступенек».
Для записи аналогового звука и его преобразования в цифровую форму используется микрофон, подключенный к звуковой плате. Чем гуще на графике будут располагаться дискретные полоски, тем качественнее в итоге получится воссоздать первоначальный звук Качество полученного цифрового звука зависит от количества измерений уровня громкости звука в единицу времени, т. е. частоты дискретизации. Частота дискретизации звука - это количество измерений громкости звука за одну секунду. Чем большее количество измерений производится за одну секунду (чем больше частота дискретизации), тем точнее «лесенка» цифрового звукового сигнала повторяет кривую аналогового сигнала. Каждой «ступеньке» на графике присваивается определенное значение уровня громкости звука. Уровни громкости звука можно рассматривать как набор возможных состояний N(градаций), для кодирования которых необходимо определенное количество информацииI, которое называется глубиной кодирования звука. Глубина кодирования звука — это количество информации, которое необходимо для кодирования дискретных уровней громкости цифрового звука. Если известна глубина кодирования, то количество уровней громкости цифрового звука можно рассчитывать по общей формуле N = 2I. Например, пусть глубина кодирования звука составляет 16 битов, в таком случае количество уровней громкости звука равно: N = 2I = 216 = 65 536. В процессе кодирования каждому уровню громкости звука присваивается свой 16-битовый двоичный код, наименьшему уровню звука будет соответствовать код 0000000000000000, а наибольшему — 1111111111111111. Качество оцифрованного звука Итак, чем больше частота дискретизации и глубина кодирования звука, тем более качественным будет звучание оцифрованного звука и тем лучше можно приблизить оцифрованный звук к оригинальному звучанию.
Самое низкое качество оцифрованного звука, соответствующее качеству телефонной связи, получается при частоте дискретизации 8000 раз в секунду, глубине дискретизации 8 битов и записи одной звуковой дорожки (режим «моно»). Самое высокое качество оцифрованного звука, соответствующее качеству аудио-CD, достигается при частоте дискретизации 48 000 раз в секунду, глубине дискретизации 16 битов и записи двух звуковых дорожек (режим «стерео»). Необходимо помнить, что чем выше качество цифрового звука, тем больше информационный объем звукового файла. Можно легко оценить информационный объем цифрового стереозвукового файла длительностью звучания 1 секунда при среднем качестве звука (16 битов, 24 000 измерений в секунду). Для этого глубину кодирования необходимо умножить на количество измерений в 1 секунду и умножить на 2 канала (стереозвук): 16 бит × 24 000 × 2 = 768 000 бит = 96 000 байт = 93,75 Кбайт. Звуковые редакторы Звуковые редакторы позволяют не только записывать и воспроизводить звук, но и редактировать его. Наиболее видными можно смело назвать, такие как Sony Sound Forge, Adobe Audition, GoldWave и другие.
Оцифрованный звук представляется в звуковых редакторах в наглядной визуальной форме, поэтому операции копирования, перемещения и удаления частей звуковой дорожки можно легко осуществлять с помощью компьютерной мыши. Кроме того, можно накладывать, перехлёстывать звуковые дорожки друг на друга (микшировать звуки) и применять различные акустические эффекты (эхо, воспроизведение в обратном направлении и др.). Звуковые редакторы позволяют изменять качество цифрового звука и объём конечного звукового файла путём изменения частоты дискретизации и глубины кодирования. Оцифрованный звук можно сохранять без сжатия в звуковых файлах в универсальном формате WAV (формат компании Microsoft) или в форматах со сжатием OGG, МР3 (сжатие с потерями). При сохранении звука в форматах со сжатием отбрасываются не слышимые и невоспринимаемые («избыточные») для человеческого восприятия звуковые частоты с малой интенсивностью, совпадающие по времени со звуковыми частотами с большой интенсивностью. Применение такого формата позволяет сжимать звуковые файлы в десятки раз, однако приводит к необратимой потере информации (файлы не могут быть восстановлены в первоначальном, исходном виде). Квантование по уровню Мы узнали, как при помощи дискретизации по времени сохраняется временная информация о звуковом сигнале; давайте теперь рассмотрим другой вопрос: как при помощи квантования по уровню кодируется информация об амплитуде сигнала. При квантовании по уровню вырабатываются двоичные числа, которые представляют значения отсчетов аналогового сигнала. Двоичные числа являются цифровым представлением напряжения аналогового звукового сигнала в моменты дискретизации по времени. Количество битов, используемых для кодирования отсчетов звукового сигнала, называется разрядностью квантования по уровню. Аналогично тому, как частота дискретизации определяет ширину полосы частот цифровой аудиосистемы, разрядность квантования по уровню определяет ее динамический диапазон, разрешающую способность и уровень нелинейных искажений. Большинство цифровых аудиосистем используют сегодня как минимум 16-разрядные слова, при этом разрядность наиболее современных систем доходит до 20. Чем больше длина слова, тем точнее выходной сигнал будет соответствовать исходному. Длина слова при квантовании определяет количество уровней квантования, используемых для кодирования отсчетов звукового сигнала. Оно равно 2х , где х— это разрядность слова. Например, 16-разрядное квантование обеспечивает 216, то есть 65536 уровней квантования отсчетов аналогового сигнала. Система с числом разрядов 18 увеличивает число уровней квантования в четыре раза, до значения 262144, а 20-разрядное квантование обеспечивает 1048576 уровней. Чем больше разрядность слова, тем шире динамический диапазон, меньше нелинейные искажения и шум, выше разрешающая способность по уровню. В отличие от процесса дискретизации по времени, квантование по уровню вносит в кодируемый сигнал погрешности. Преобразование бесконечного множества значений аналоговой величины в конечное количество двоичных чисел по самой своей природе является аппроксимационным процессом. Погрешности появляются потому, что результат квантования фактически никогда не является точным представлением напряжения аналогового сигнала. Разность между фактическим значением аналогового сигнала и представляющим его двоичным числом называется погрешностью квантования по уровню, или шумом квантования.
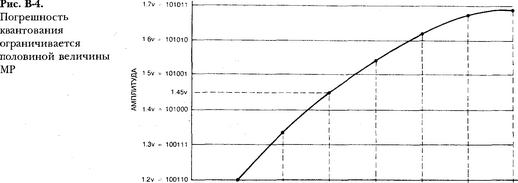
На рис. В-4 показано, как появляются погрешности квантования. Значения аналогового сигнала не совпадают со значениями, представляемыми при помощи двоичных чисел. Например, первая выборка (крайняя левая вертикальная штриховая линия) попадает между уровнями квантования 100111 и 101000. Поскольку не существует значения 100111,25, квантующее устройство просто округляет его до ближайшего дискретного уровня квантования (100111), хотя это число и не является абсолютно точным. Разность между напряжением, представляемым числом 100111 (1,3 В), и фактическим напряжением звукового сигнала (1,325 В) дает погрешность квантования. При восстановлении аудиосигнала по округленному двоичному числу 100111 будет выработан не вполне точный аналоговый сигнал. В результате появится искажение исходной формы звуковой волны. Наихудший случай — это когда аналоговый сигнал имеет значение, попадающее точно между двумя уровнями квантования. Именно такая ситуация имеет место для второго слева отсчета на рис. В-4. Разность между отсчетом аналогового сигнала и уровнем квантования, представляющим этот отсчет, будет наибольшей. Погрешность квантования выражают в процентах от младшего разряда (MP). Для первой слева выборки погрешность квантования составляет одну четверть MP, для второй — половину MP. Обратите внимание, что погрешность квантования никогда не превосходит половины значения MP. Следовательно, чем меньше величина шага квантования по уровню, тем меньше погрешность. Добавление одного разряда удваивает число шагов и вдвое уменьшает погрешность квантования. Поскольку уменьшение вдвое дает разницу в 6 дБ, отношение сигнала к шуму в цифровой системе увеличивается на 6 дБ при добавлении каждого дополнительного разряда в слове квантования. Цифровая система с 18-разрядным квантованием по уровню будет иметь шум на 12 дБ ниже, чем система с 16-разрядным квантованием. Отношение сигнал/шум цифровой системы в децибелах можно приблизительно определить, умножив разрядность слова квантования на 6. В системе с 16-разрядным квантованием обеспечивается отношение сигнал/шум около 96 дБ, а в 20-разрядной цифровой аудиосистеме оно составит примерно 120 дБ, то есть на 24 дБ выше, чем в первом случае. Погрешность квантования воспринимается на слух как грубая зернистость звука низкого уровня, например, реверберационного процесса. Вместо того чтобы слышать постепенное затухание звука до полного его исчезновения, мы замечаем увеличение шероховатости и зернистости по мере затухания сигнала. Это происходит потому, что по мере снижения уровня сигнала погрешность квантования начинает составлять все больший процент от его величины. Увеличение нелинейных искажений по мере снижения уровня сигнала характерно для цифровой аудиотехники; во всех типах аналоговой записи повышенные искажения проявляются при высоком уровне сигнала. Рост искажений при снижении уровня сигнала делает их намного более заметными. Увеличение разрядности слова квантования с 16 до 20 значительно уменьшает остроту этой проблемы. Учтите, что отношение сигнал/шум и значение полного коэффициента нелинейных искажений, указанные в паспорте цифровой аудиосистемы, относятся к сигналу максимального уровня. Большую часть времени уровень музыкального сигнала существенно ниже и таким образом ближе к уровню шума. Искажения определяются не полным количеством разрядов цифровой системы, а числом разрядов, используемых для квантования сигнала в данный момент. Именно вследствие этого искажения и шум в цифровых аудиосистемах обратно пропорциональны амплитуде сигнала, из-за чего возникают сложности с сигналами низкого уровня. Установка уровня записи при использовании цифровых систем принципиально отличается от подобной операции для аналоговых систем. В идеальном случае наивысший пик во всей аудиопрограмме должен в точности соответствовать полному цифровому уровню, т.е. использовать все разряды цифрового кода. Если уровень записи установлен так, что наивысший пик на 6 дБ ниже уровня полной шкалы, то это равнозначно отбрасыванию одного бита из слова квантования и снижению отношения сигнал/шум на 6 дБ. Если амплитуда аналогового сигнала выше, чем напряжение, представляемое наибольшим числом, устройство квантования просто выходит за пределы своих возможностей по числу разрядов и формирует наибольшее доступное значение, ограничивая таким образом музыкальные пики. Возникает искаженная форма сигнала, которая создает на пиках неприятный "скрипучий" звук. Если у вас есть устройство цифровой записи на магнитную ленту в формате DAT, вы можете просмотреть уровень записи на компакт-диске, подключив цифровой выход проигрывателя компакт-дисков к цифровому входу магнитофона. Его индикатор покажет точный уровень записи на компакт-диске. Если наивысший пик никогда не достигает полной шкалы, это значит, что часть разрешающей способности потеряна вследствие неоптимальной записи. Учтите, что уровень звуковой программы с очень широким динамическим диапазоном будет большую часть времени находится близко к уровню шума квантования, в отличие от сигнала с ограниченным динамическим диапазоном. Пики сигнала, имеющего широкий динамический диапазон, будут примерно соответствовать уровню полной шкалы, следовательно, сигнал с существенно меньшим уровнем будет кодироваться меньшим числом разрядов. Эта проблема особенно остра в классической музыке, имеющей очень широкий динамический диапазон. Инженеры звукозаписи вынуждены сжимать динамический диапазон при записи классической музыки. К этой мере прибегают и продюсеры поп-музыки, которые хотят, чтобы их записи звучали по радио громче, чем другие песни. Жесткое ограничение динамического диапазона делает поп-музыку громкой в течение всего времени, но это достигается за счет снижения ее динамичности, естественности и мощности ритма. Товары для здоровья и красоты - ортопедические матрасы. Уровни цифрового сигнала рассчитываются относительно сигнала полной шкалы, соответствующего единичным значениям цифр всех разрядов. При данном количестве разрядов большего числа быть не может. Этот эталонный уровень называется 0дБР8, где обозначение FS (Full Scale) означает "полной шкалы". Например сигнал с уровнем — 20 дБР8 на 20 дБ ниже сигнала полной шкалы. 2 Вибра́то — периодические изменения высоты, громкости или тембра музыкального звука. Амплитудное вибрато (англ. amplitude modulation) — звуковой эффект или соответствующее устройство, реализующее периодическое изменение уровня громкости (амплитуды сигнала). Характеризуется пульсирующим звучанием. Часто́тное вибра́то, бенд, подтяжка (англ. bending — изгиб, искривление) — приём игры на некоторых музыкальных инструментах, позволяющий извлечь «искусственные» ноты, не предусмотренные в строе инструмента. Эффект тембрового вибрато также предназначен для изменения спектра звуковых колебаний. Физическая сущность этого эффекта состоит в том, что исходное колебание с богатым тембром пропускается через полосовой частотный фильтр, у которого периодически изменяется либо частота настройки, либо полоса пропускания, либо по различным законам изменяются оба параметра. При этом фильтр выделяет из всего спектра исходного колебания те частотные составляющие, которые попадают в “мгновенную” полосу его пропускания. Так как полоса пропускания изменяется по ширине и перемещается по частоте, то тембр сигала периодически изменяется. 2 2 Дилэй (англ. Delay - задержка) — эффект задержки звука, задержка происходит с помощью записи входного сигнала с последующим проигрыванием его через определённый период времени. Задержанный сигнал может воспроизводится либо один раз, либо несколько раз для создания повторяющегося звука похожего на распадающейся эхо. Флэнжер (англ. flanger - фланец) - это звуковой эффект, который происходит когда два идентичные сигнала смешиваются вместе, один из сигналов задержан на небольшое время, время задержки постоянно изменяется, как правило задержка меньше 20 миллисекунд. Это приводит к эффекту движущегося гребенчатого фильтра: пики и провалы суммируются в результирующий частотный спектр, где они связанны друг с другом в линейный гармонический ряд. Изменение времени задержки служит причиной движения вверх и вниз по частотному спектру. Часть выходного сигнала, как правило, подается обратно на вход (обратная связь), ("рециркулирующие задержки"), это производит эффект резонанса, что еще больше усиливает интенсивность пиков и провалов в спектре. Фаза подаваемого обратно сигнала иногда перевернута, это порождает еще одну вариацию фленжер эффекта. Флэнжер создает в спектре звука "расческу" - последовательность максимумов и минимумов, схожую с дифракционной/интерференционной картинами. Благодаря встроенному LFO, эта картина движется вверх-вниз, максимумы воспринимаются как обертона, в результате чего кажется, что звук тоже становится то выше, то ниже, хотя в то же время слушатель слышит все те же ноты без изменений. Фэйзер (англ. phaser), также часто называемый фазовым вибрато — звуковой эффект, который достигается фильтрацией звукового сигнала с созданием серии максимумов и минимумов в его спектре. Положение этих максимумов и минимумов варьируется протяжении звучания, что создает специфический круговой (англ. sweeping) эффект. Также фэйзером называют соответствующее устройство. По принципу работы схож с хорусом и отличается от него временем задержки (1-5 мс). Помимо этого задержка сигнала у фэйзера на разных частотах неодинакова и меняется по определённому закону. Хорус (англ. chorus - хор) - модуляционный эффект, созданный для имитации многоголосного (хорового) звучания. Эффект хора возникает, когда отдельные звуки с примерно одинаковым тембром и почти (с небольшим отличием) одинаковой высотой тона (питч), смешиваются и воспринимаются как единое целое. Похожие звуки, исходящие из различных источников могут происходить естественным путём (как в случае хора или струнного оркестра), он этот эффект также может моделировать с помощью электронных блок эффектов или другими устройствами обработки.
3 2 Плаги́н (от англ. plug-in) — независимо компилируемый программный модуль, динамически подключаемый к основной программе, предназначенный для расширения и/или использования её возможностей. Также может переводиться как «модуль». Плагины обычно выполняются в виде разделяемых библиотек. Плагин - это маленькая программка, которая встраивается в основную (большую) программу и расширяет её возможности. 4 2 Панорамирование Функция Pan/Expand позволяет определить, как будет слышен звук в звуковом поле между двумя динамиками. Можно сделать так, что звук будет восприниматься исходящим из левой или правой колонки, а также из звукового поля между ними. Этот эффект называется панорамированием. Функция Pan/Expand обладает и некоторыми другими возможностями, о которых мы также коротко расскажем.
При работе со стереофоническим файлом можно включить отображение диаграммы сигналов в качестве фона графика, установив флажок Show wave. Вы также можете указать программе, отображать ли содержимое обоих каналов или только одного из них, выбрав соответствующий пункт из расположенного рядом списка. Это никак не повлияет на сам процесс панорамирования.
7. Отрегулируйте ползунок параметра Output gain (-60 to 20 dB), чтобы определить громкость файла после обработки. Изменение длительности Изменением длительности фрагмента или целого файла занимается команда Time Stretch (растяжение времени) в меню Process1. На рисунке 3.35 показано ее диалоговое окно.
5 Не, ну чё? Эффекты и все дела – заебись, чё! 6 1Сигналограмма, носитель информации в виде ленты, диска, листа и т. д. с произведённой на нём записью сигналов. На С. имеется дорожка записи — след, оставляемый записывающим устройством на движущемся носителе в процессе записи. Дорожка может представлять собой канавку в носителе, след краски на его поверхности, намагниченную или электризованную область носителя и т. д. Формы дорожек разнообразны — прямолинейная, спиральная или состоящая из ряда отрезков (при построчной записи). С., на которой выполнены одновременно или последовательно несколько дорожек, называется многодорожечной. Частные случаи С. — фонограмма (при записи звука), видеограмма (при записи изображений), видеофонограмма (при записи и звука, и изображений). Часто в название С. включают также и название системы записи, например грампластинку называют механической фонограммой, магнитную ленту с записью звуковых сигналов — магнитной фонограммой, киноплёнку с записью звуковых сигналов — фотографической фонограммой. Иногда название С. содержит указание на назначение или особенности записанной информации (например, телеметрическая С., стереофоническая фонограмма). В процессе воспроизведения записанной информации дорожка записи движущейся С. взаимодействует с соответствующим элементом воспроизводящего устройства. 2Если в фонограмме есть продолжительные паузы, то в них становятся более заметными шумы, записанные вместе с полезным сигналом. В Adobe Audition есть несколько способов борьбы с шумами в паузах. Один из них — замена звука, имеющегося в паузах, на абсолютную тишину. На практике это означает, что значения всех звуковых отсчетов в заданном фрагменте приравниваются к нулю. Абсолютная тишина на выделенном участке волновой формы создается после применения команды Effects > Silence. Чтобы уяснить сущность этой функции, сравните рис. 5.10 (исходный сигнал) и рис. 5.11 (тот же сигнал после обработки командой Effects > Silence).
Рис. 5.10. Пример исходного сигнала Команда Silence может пригодиться в том случае, когда части полезного сигнала (слова, фразы) отделены друг от друга протяженными паузами, в которых ничего нет кроме шума (см. рис. 5.10). Она незаменима, если все фрагменты полезного звукового сигнала должны оставаться на своих местах, а удаление пауз недопустимо. Если допускается смещение фрагментов полезного сигнала во времени, то можно просто вырезать паузы из фонограммы или применить средство автоматизации этого процесса, имеющееся в Adobe Audition (команда Edit > Delete Silence [10, разд. 4.8]). В ряде ситуаций, наоборот, нужно "раздвинуть" отдельные фрагменты на определенный интервал, добавив между ними паузы заданной длительности.
Рис. 5.11. Сигнал после обработки командой Silence Конечно, есть смысл сделать так, чтобы вновь введенные паузы не содержали шумов. В таких случаях целесообразно воспользоваться командой Generate > Silence, открывающей окно Generate Silence, в котором есть поле для ввода длительности паузы. После нажатия кнопки ОК волновая форма будет разделена в точке расположения маркера, а справа от нее появится участок заданной длительности, содержащий абсолютную тишину. Левая часть исходной волновой формы останется на месте, а начало ее правой части переместится в конец сформированной паузы. Если паузы коротки и их много, то становится хлопотно выделять вручную каждую из них с целью последующей замены шума абсолютной тишиной. Разумнее применить шумоподавление. Нужно, однако, понимать, что путем применения алгоритмов шумоподавления нельзя достичь абсолютной тишины, а можно только более или менее эффективно снизить уровень шума. Вместе с тем, некоторые специалисты считают, что шум в паузах хотя и должен быть ослаблен, но полностью удалять его (например, заменяя абсолютной тишиной) не следует. Скачки от идеально тихих фрагментов к фрагментам, где наряду с речью либо музыкой содержится шум, иногда бывают заметными и раздражают слушателя. Не станем сейчас заменять абсолютной тишиной паузу между дублями в файле EX05_02.WAV. Дело в том, что мы планируем применить к файлу одно из средств шумоподавления, имеющихся в Adobe Audition. Оно основано на том, что программа вычисляет значения спектральных составляющих предъявленного ей шума и затем вычитает их из соответствующих спектральных составляющих смеси "сигнал + шум". Если в волновой форме имеется участок абсолютной тишины, то после шумоподавления он будет заменен инвертированным шумом. Из сказанного следует, что если вы решите вставить в волновую форму фрагменты абсолютной тишины, то делать это целесообразно после шумоподавления, а не до него. 7 1Маркеры – это, по своей сути – как своеобразная «книга записи» для звукового файла. Правой клавишей мыши по кнопочке маркера мы можем переименовать его на, к примеру, «отрезок для эквалайзера» и маркер всегда укажет – где необходимо применить эту функцию. Запомните: маркеры не влияют на проигрывание файла, они лишь незаменимые метки при работе с аудиофайлом. Ну, уж если вы обработали файл, а маркер вам просто «режет глаз» – удалите его при помощи той же правой клавиши мыши. В следующий раз я расскажу вам о том, как за три минуты «обрезать» ненужный вам бит и превратить 6 минутную песню в 3-4 минутную радио версию. А так же о полезных свойствах команды CTRL+K 8 1
2Так выпьем же за то, чтобы наши желания всегда совпадали с нашими возможностями! Этот ставший классическим тост из незабываемой кинокомедии очень точно выражает одну из наиболее трудноразрешимых проблем обработки аудиосигналов. Очень хочется, чтобы динамический диапазон канала записи/передачи соответствовал динамическому диапазону звука, создаваемого реальными источниками. Чтобы и самые тихие звуки достигали ушей слушателя, и самые громкие не вызывали перегрузку аппаратуры. Увы, как правило, динамический диапазон источников звука шире динамического диапазона радиоприемника, усилителя, магнитофона, акустической системы. Для урегулирования этого противоречия и решения множества сопутствующих задач служат приборы динамической обработки: лимитеры, компрессоры, деэсеры, экспандеры, гейты. Разъяснение их сущности вы найдете в книге "Музыкальный компьютер. Секреты мастерства". Программистская мысль не стоит на месте. Появляются новинки, обладающие поистине магическими возможностями. О плагинах динамической обработки, входящих в пакет Waves Platinum Native Bundle 4, наш сегодняшний рассказ. Их очень много. Придется ограничиться только "самыми-самыми". Привычное управление RComp - компрессор/экспандер, в котором имитируется устройство с традиционным составом элементов управления. Внутренняя обработка звуковых данных в плагине производится с 56-битным разрешением, с которым программы-хосты работать пока не способны. Поэтому на выходе плагина производится понижение разрядности до 24 бит и дитеринг (подмешивание слабого "цифрового" шума, позволяющее и после снижения разрядности сохранить у слушателя ощущение большой ширины динамического диапазона).
В левой части окна располагается измеритель уровня входного стереосигнала. Ориентируясь по его показаниям, вы должны выбрать подходяще значение порога срабатывания прибора. Для этих целей имеется движковый регулятор Thresh. В поле, совмещенном с регулятором, в децибелах отображается численное значение порога. Такое соседство очень удобно. Не нужно гадать, какой порог следует выставить. Смотрите на светящиеся столбики индикаторов и перемещайте регулятор на такую высоту, чтобы он находился в районе той отметки, до которой столбики опускаются в моменты достижения сигналом минимального уровня (исключая паузы). Это и будет отправной точкой в настройке компрессора. 
Не нашли, что искали? Воспользуйтесь поиском по сайту: ©2015 - 2026 stydopedia.ru Все материалы защищены законодательством РФ.
|


 В окне свойств элемента (рис. 8) можно задать его имя, тип, позицию в файле, для региона - продолжительность.
В окне свойств элемента (рис. 8) можно задать его имя, тип, позицию в файле, для региона - продолжительность.
 Очень полезная возможность - запускать воспроизведение региона от MIDI события, иными словами, задавать триггер (см. далее).
Регионы могут создаваться автоматически на основе звуковых данных или по сетке временного деления. Используется команда Auto Region из меню Tools (рис. 9). В диалоге есть несколько пресетов для разного звукового материала, но настройка алгоритма также ничего сложного не представляет. Чем большее значение имеет параметр Attack Sensitivity, тем больше регионов будет создано, новые регионы будут создаваться даже при небольшом увеличении уровня. Все то же с точностью до наоборот относится к параметру Release Sensitivity. Параметр Minimum Level запрещает создание региона до тех пор, пока уровень не достигнет заданного. Высокие значения Minimum Level полезны, когда нужно построить регионы по границам такта, если начало четко отмечается бас-барабаном, а сам микс насыщен другими инструментами. Эту же задачу можно решить другим способом - сначала задать текущий темп в диалоге Edit tempo (меню Special), а затем включить опцию Build
Очень полезная возможность - запускать воспроизведение региона от MIDI события, иными словами, задавать триггер (см. далее).
Регионы могут создаваться автоматически на основе звуковых данных или по сетке временного деления. Используется команда Auto Region из меню Tools (рис. 9). В диалоге есть несколько пресетов для разного звукового материала, но настройка алгоритма также ничего сложного не представляет. Чем большее значение имеет параметр Attack Sensitivity, тем больше регионов будет создано, новые регионы будут создаваться даже при небольшом увеличении уровня. Все то же с точностью до наоборот относится к параметру Release Sensitivity. Параметр Minimum Level запрещает создание региона до тех пор, пока уровень не достигнет заданного. Высокие значения Minimum Level полезны, когда нужно построить регионы по границам такта, если начало четко отмечается бас-барабаном, а сам микс насыщен другими инструментами. Эту же задачу можно решить другим способом - сначала задать текущий темп в диалоге Edit tempo (меню Special), а затем включить опцию Build  regions using the current tempo.
Все регионы, созданные в файле, содержатся в списке регионов (Regions List, рис. 10) - это плавающее окно, которое может быть прицеплено к любому краю главного окна.
regions using the current tempo.
Все регионы, созданные в файле, содержатся в списке регионов (Regions List, рис. 10) - это плавающее окно, которое может быть прицеплено к любому краю главного окна.

