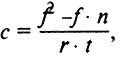|
|
Контент-анализ — описание методаКонтент-анализ (от англ. contens содержание) — метод качественно-количественного анализа содержания документов с целью выявления или измерения различных фактов и тенденций, отраженных в этих документах. Особенность контент-анализа состоит в том, что он изучает документы в их социальном контексте. Может использоваться как основной метод исследования (например, контент-анализ текста при исследовании политической направленности газеты), параллельный, т.е. в сочетании с другими методами (напр., в исследовании эффективности функционирования средств массовой информации), вспомогательный или контрольный (напр., при классификации ответов на открытые вопросы анкет). Не все документы могут стать объектом контент-анализа. Необходимо, чтобы исследуемое содержание позволило задать однозначное правило для надежного фиксирования нужных характеристик (принцип формализации), а также, чтобы интересующие исследователя элементы содержания встречались с достаточной частотой (принцип статистической значимости). Чаще всего в качестве объектов исследования контент-анализа выступают сообщения печати, радио, телевидения, протоколы собраний, письма, приказы, распоряжения и т.д., а также данные свободных интервью и открытые вопросы анкет. Основные направления применения контент-анализа: выявление того, что существовало до текста и что тем или иным образом получило в нем отражение (текст как индикатор определенных сторон изучаемого объекта — окружающей действительности, автора или адресата); определение того, что существует только в тексте как таковом (различные характеристики формы — язык, структура, жанр сообщения, ритм и тон речи); выявление того, что будет существовать после текста, т.е. после его восприятия адресатом (оценка различных эффектов воздействия). В разработке и практическом применении контент-анализа выделяют несколько стадий. После того, как сформулированы тема, задачи и гипотезы исследования, определяются категории анализа — наиболее общие, ключевые понятия, соответствующие исследовательским задачам. Система категорий играет роль вопросов в анкете и указывает, какие ответы должны быть найдены в тексте. В практике отечественного контент-анализа сложилась довольно устойчивая система категорий — знак, цели, ценности, тема, герой, автор, жанр и др. Все более широко распространяется контент-анализ сообщений средств массовой информации, основанный на парадигматическом подходе, в соответствии с которым изучаемые признаки текстов (содержание проблемы, причины ее возникновения, проблемообразующий субъект, степень напряженности проблемы, пути ее решения и др.) рассматриваются как определенным образом организованная структура. Категории контент-анализа должны быть исчерпывающими (охватывать все части содержания, определяемые задачами данного исследования), взаимоисключающими (одни и те же части не должны принадлежать различным категориям), надежными (междукодировщиками не должно быть разногласий по поводу того, какие части содержания следует относить к той или иной категории) и уместными (соответствовать поставленной задаче и исследуемому содержанию). При выборе категорий для контент-анализа следует избегать крайностей: выбора слишком многочисленных и дробных категорий, почти повторяющих текст, и выбора слишком крупных категорий, т.к. это может привести к упрощенному, поверхностному анализу. Иногда необходимо принимать во внимание и отсутствующие элементы текста, которые могут быть значимыми для контент-анализа. После того, как категории сформулированы, необходимо выбрать соответствующую единицу анализа — лингвистическую единицу речи или элемент содержания, служащие в тексте индикатором интересующих исследователя явления. В практике отечественных контент-аналитических исследований наиболее, употребительными единицами анализа являются слово, простое предложение, суждение, тема, автор, герой, социальная ситуация, сообщение в целом и др. Сложные виды контент-анализа обычно оперируют не одной, а несколькими единицами анализа. Единицы анализа, взятые изолировано, могут быть не всегда правильно истолкованы, поэтому они рассматриваются на фоне более широких лингвистических или содержательных структур, указывающих на характер членения текста, в пределах которого идентифицируется присутствие или отсутствие единиц анализа — контекстуальных единиц. Например, для единицы анализа «слово» контекстуальная единица — «предложение». Наконец, необходимо установить единицу счета — количественную меру взаимосвязи текстовых и внетекстовых явлений. Наиболее употребительны такие единицы счета, как время-пространство (число строк, площадь в квадратных сантиметрах, минуты, время вещания и т.п.), появление признаков в тексте, частота их появления (интенсивность). Важен выбор необходимых источников, подвергаемых контент-анализу. Проблема выборки содержит в себе выбор источника, количества сообщений, даты сообщения и исследуемого содержания. Все эти параметры выборки определяются задачами и масштабами исследования. Чаше всего контент-анализ проводится на годичной выборке: если это изучение протоколов собраний, то достаточно 12 протоколов (по числу месяцев), если изучение сообщений средств массовой информации — 12—16 номеров газеты или теле-, радиодней. Обычно выборка сообщений средств массовой информации составляет 200—600 текстов. Необходимым условием является разработка таблицы контент-анализа — основного рабочего документа, с помощью которого проводится исследование. Тип таблицы определяется этапом исследования. Например разрабатывая категориальный аппарат, аналитик составляет таблицу, представляющую собой систему скоординированных и субординированных категорий анализа. Такая таблица внешне напоминает анкету: каждая категория (вопрос) предполагает ряд признаков (ответов), по которым квантифицируется содержание текста. Для регистрации единиц анализа составляется другая таблица — кодировальная матрица. Если объем выборки достаточно велик (свыше 100 единиц), то кодировщик, как правило, работает с тетрадью таких матричных листов. Если выборка невелика (до 100 единиц), то можно проводить двумерный или многомерный анализ. В этом случае для каждого текста должна быть своя кодировальная матрица. Эта работа трудоемка и кропотлива, поэтому при больших объемах выборки сопоставление интересующих исследователя признаков осуществляется на компьютере. Важным условием контент-анализа является разработка инструкции кодировщику — системы правил и пояснений для того, кто будет собирать эмпирическую информацию, кодируя (регистрируя) заданные единицы анализа. В инструкции точно и однозначно излагается алгоритм действий кодировщика, дается операциональное определение категорий и единиц анализа, правила их кодирования, приводятся конкретные примеры из текстов, являющихся объектом исследования, оговаривается, как следует поступать в спорных случаях, и т.д. Процедура подсчета при количественном контент-анализе в общем виде аналогична стандартным приемам классификации по выделенным группировкам ранжирования и измерения ассоциации. Существуют также специальные процедуры подсчета применительно к контент-анализу, напр., формула коэффициента Яниса, предназначенного для вычисления соотношения положительных и отрицательных (относительно избранной позиции) оценок, суждений, аргументов. В случае, когда число положительных оценок превышает число отрицательных, где f — число положительных оценок; n — число отрицательных оценок; r — объем содержания текста, имеющего прямое отношение к изучаемой проблеме; t — общий объем анализируемого текста. В случае, когда число положительных оценок меньше, чем отрицательных,
Есть и более простые способы измерения. Удельный вес той или иной категории можно вычислить с помощью формулы К = число единиц анализа, фиксирующих данную категорию/общее число единиц анализа.

Не нашли, что искали? Воспользуйтесь поиском по сайту: ©2015 - 2026 stydopedia.ru Все материалы защищены законодательством РФ.
|