|
|
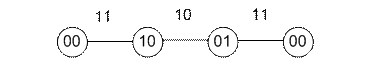
Свободное расстояние сверточного кода.Мерой помехоустойчивости сверточного кода является, как правило, вероятность ошибочного приема либо отдельного символа, либо блока символов в целом. Однако помехоустойчивость декодирования зависит и от дистанционных свойств кодовых последовательностей на выходе кодера. При этом чаще всего расстояние между последовательностями оценивают с помощью метрики Хэмминга. Так, свободное расстояние df (dfree) - это минимальное расстояние между двумя произвольными полубесконечными последовательностями на выходе кодера, отличающимися в первой ветви. Для коротких кодов свободное расстояние легко определить по диаграмме состояний кода. Свободное расстояние кода равно минимальному весу пути по диаграмме из состояния 00 в тоже состояние (исключая петлю у состояния 00). Диаграмма свободного расстояния для рисунка 3.3 изображена на рисунке 3.5 и для него df =5. Для нерекурсивного кодера это вес отклика кодирующего устройства на единичный символ. Свободное расстояние df используется для оценки помехоустойчивости декодирования сверточных кодов. Этот параметр аналогичен минимальному кодовому расстоянию dmin , которое характеризует помехозащитные свойства блоковых кодов. Свободное расстояние показывает, сколько ошибок может произойти в канале связи, чтобы одна кодовая последовательность перешла в другую, и эти ошибки не были бы обнаружены декодером.
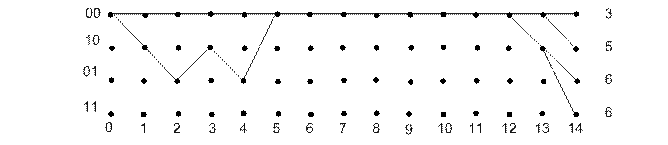
Рисунок 3.5. – Диаграмма состояний сверточного кодера для нахождения свободного расстояния. Декодирование Витерби. Известен ряд алгоритмов декодирования сверточных кодов. В практических системах и, в частности в мобильной связи, как правило, используется алгоритм Витерби, отличающийся простотой реализации при умеренных длинах кодового ограничения. Алгоритм Витерби реализует оптимальное (максимально правдоподобное) декодирование как рекуррентный поиск на кодовой решетке пути, ближайшего к принимаемой последовательности. На каждой итерации алгоритма Витерби сопоставляются два пути, ведущих в данное состояние (узел решетки). Ближайший из них к принятой последовательности сохраняется для дальнейшего анализа как выживший, тогда как другой отбрасывается. Таким образом, если игнорировать случаи, когда оба конкурирующих пути равноудалены от принятой последовательности, число выживших путей, сохраняемых в памяти, равно числу узлов 2т. Пусть передается нулевое кодовое слово, а в канале произошла трехкратная ошибка, так что принятая последовательность имеет вид 10 10 00 00 10 00 ... 00 ... Результаты поиска ближайшего пути после приема 14 элементарных блоков показаны на рис. 3.6. На правой части рисунка видны четыре пути, ведущие в каждый узел решетки. Рядом проставлены метрики (хэмминговы расстояния этих путей от принятой последовательности на отрезке из 14 блоков). Метрика верхнего пути значительно меньше метрик нижних. Поэтому можно предположить, что верхний путь наиболее вероятен. Однако декодер Витерби, не зная следующих фрагментов принимаемой последовательности, вынужден запомнить все четыре пути на время приема L элементарных блоков. Число L называется шириной окна декодирования. Для уменьшения ошибки декодирования величину L следует выбирать достаточно большой, многократно превышающей длину кодового ограничения, что естественно усложняет декодер. В данном случае L = 15. Отметим, что тактика выбора и последующего анализа только одного пути с наименьшим расстоянием составляет сущность более экономного последовательного декодирования.
Рисунок 3.6. – Пример работы алгоритма Витерби.
На средней части рисунке 3.6 видно, что все пути имеют общий отрезок (сливаются от 5-го до 12-го шага) и, следовательно, прием новых блоков не может повлиять на конфигурацию этого участка наиболее правдоподобного пути. Поэтому декодер уже может принимать решение о значении информационных символов, соответствующих этим элементарным блокам. Левая часть рисунка демонстрирует возможную ситуацию неисправляемой ошибки. Существует два пути с одинаковыми метриками. Декодер может разрешить эту неопределенность двумя способами: отметить этот участок как недостоверный или принять одно из двух конкурирующих решений (информационная последовательность равна 00000... или 10100...). Очевидно, что расширение окна декодирования не позволяет исправить такую ошибку. Ее исправление возможно при использовании кода с большей корректирующей способностью. Поступление из канала нового элементарного блока вызывает сдвиг картинки в окне декодирования влево. В результате левое ребро пути исчезает, а справа появляется новый столбец решетки, к узлам которого должны быть продолжены сохраненные пути от узлов предыдущего столбца. Для этого выполняются следующие операции. 1. Для каждого узла нового столбца вычисляются расстояния между принятым блоком и маркировкой ребер, ведущих в данный узел. 2. Полученные метрики ребер суммируются с расстоянием путей, которые они продолжают. 3. Из двух возможных путей оставляется путь с меньшей метрикой, а другой отбрасывается, так как следующие поступающие блоки не могут изменить соотношения расстояний этих путей. В случае равенства расстояний или случайно выбирается один путь, или сохраняются оба. В результате этих операций к каждому узлу нового столбца вновь ведет один путь. Например, пусть новый блок из канала равен 00. Рассмотрим продолжение пути к нижнему узлу решетки, в который можно попасть из состояния кодера 10 по ребру 01 или из состояния 11 по ребру 10 (см. рис. 3.4). В обоих случаях расстояние этих ребер от принятого блока 00 равно 1. Однако суммарное расстояние пути, продолженного из состояния 10, равно 6, а пути из состояния 11 равно 7. Поэтому второй путь будет отброшен вместе с ребром 01, которое входило в нижний узел на предыдущем шаге декодирования (см. рис. 3.6). Оценка информационного символа производится по крайнему левому ребру пути в окне декодирования. Согласно правилу построения кодовой решетки принимается, что информационный символ равен 0, если это ребро верхнее, и 1, если ребро нижнее. Рассмотренный пример поясняет работу декодера в предположении, что выходной сигнал демодулятора квантуется на 2 уровня (так называемое жесткое декодирование). Большее число уровней квантования приводит к мягкому декодированию. Установлено, что 8 уровней квантования гарантируют практически потенциальную достоверность декодирования. 
Не нашли, что искали? Воспользуйтесь поиском по сайту: ©2015 - 2024 stydopedia.ru Все материалы защищены законодательством РФ.
|