
|
|
Синтаксические диаграммы и функции распознавания цепочек для нетерминальных символовПриведенные выше регулярные выражения, как уже говорилось, описывают полный синтаксис языка SPL. Теперь необходимо написать такую программу на языке Си, которая читала бы символ за символом слева направо программы на языке SPL и осуществляла синтаксический анализ текста программы. Рассматривая весь текст программы на SPL как одну цепочку символов, программа синтаксического анализа должна решить, принадлежит ли эта цепочка (программа на SPL) языку, описываемому грамматикой, представленной тринадцатью регулярными выражениями. В случае наличия синтаксической ошибки программа должна выдать сообщение о том, в какой строке программ на SPL имеется ошибка, какая лексема и с какой не совпадает. После этого анализ прекращается. В случае отсутствия ошибок, должно появиться сообщение, что ошибок нет. Перед тем как изучить последующий материал, следует повторить материал по синтаксическим диаграммам: что это такое и зачем, как обозначаются дуги и правила прохождения дуг, помеченных терминальными и нетерминальными символами. Суть в том, что по каждому регулярному выражению изображается соответствующая синтаксическая диаграмма, а по ней пишется текст функции на Си для распознавания цепочек, выводимых для рассматриваемого нетерминального символа. В этих функциях часто вызывается функция get ( ), которая возвращает лексему lex. Кроме того, при прохождении дуг, помеченных терминальными символами, необходимо сравнивать имеющуюся в данный момент лексему lex с ожидаемой лексемой lx. Для этого служит функция exam ( ). В случае совпадения lex и lx считывается новая лексема (вызывается get ( )). При несовпадении выдается сообщение об этом и прекращается работа программы. Текст функции exam ( ) приводится ниже. void exam (int lx) { if (lex!=lx) { printf (“Не совпадают лексемы lex=%i и lx=%i в строке nst=%i \n”, lex, lx, nst ); exit (1); } get ( ); return; } Текст программы part2.c на Си, которая осуществляет лексический и синтаксический анализ, приведен на рис. В эту программу полностью входит рассмотренная ранее программа лексического анализа part1.c. Однако в ней имеются одно дополнение и одно изменение. В функции main( ) после вызова get( ); следует также вызвать функцию вывода для главного нетерминального символа prog( ); Изменение внесено в самом начале функции get( ). Вместо while (nch!=EOF) { … … } следует if (nch = = EOF) { lex = EOF; return; } ……… Таким образом, функцией get( ) при каждом обращении к ней выдается только одна – очередная лексема. Кроме того, part2. cотличается от part1.c наличием функций, соответствующих каждому нетерминальному символу. Как уже сказано выше, для их написания используются синтаксические диаграммы, полученные в строгом соответствии с регулярными выражениями. Ниже рассмотрим, как это делается конкретно. Первым должен рассматриваться главный нетерминальный символ PROG. 1) PROG → (DCONST |DVARB |DFUNK) * eof
void prog( ) { while (lex!=EOF) { switch (lex) { case IDEN: dfunc( ); break; case INTL: dvarb( ); break; case CONSTL: dconst( ); break; default: printf(“Ошибка синтаксиса в строке nst=%i. Лексема lex=%i \n”, nst, lex); } }
return; } По диаграмме видно, что если lex!=EOF, то реализуется разветвление по нескольким ветвям в зависимости от lex. Лексема lex может быть IDEN, если описывается функция, INTL при описании переменных и CONSTL – констант. Естественно, производится вызов одной из функций: dfunc( ), dvarb( ), dconst( ).
2) DCONST → constl CONS (‘,’ CONS)* ‘;’
void dconst( ) { // Нет неиспользованной “свежей” лексемы // Ее нужно получить, вызвав get( ); do { get( ); cons( ); } while (lex = = ‘,’); exam (‘;’); return; } Вначале происходит проход дуги, помеченной терминальным символом constl. Проверка того, что лексема lex была равна constl, осуществляется в функции prog( ). Именно там по switch (lex) в случае case CONSL была вызвана функция dconst( ). Перед прохождением следующей дуги, обозначенной нетерминальным символом CONS, согласно правилу прохождения дуг синтаксической диаграммы должен быть прочитан очередной терминальный символ (лексема). Напомним, что лексема constl уже использована. “Свежей” лексемы нет. Поэтому в функции dconstl перво-наперво считывается новая лексема ( вызов get( )), а затем уже вызывается функция cons( ), соответствующая нетерминальному символу CONS. Цикл осуществляется пока lex = =’,’. В случае выхода из цикла проверяется условие, что lex==’;’. Для этого вызывается exam (‘;’). Если это условие выполняется, то функция exam( ) в конце вызывает get( ) и, таким образом, поставляет “свежую” лексему, необходимую для дальнейшего синтаксического анализа.
3) CONS → iden ’=’ [ ‘+ ’| ’-’ ] numb
//“Свежая” лексема есть void cons( ) { exam (IDEN); exam (‘=’); if (lex = = ‘+’ || lex = = ‘-‘) get( ); exam (NUMB); return; } При прохождении дуги, помеченной терминальным символом, проверяется совпадение имеющейся лексемы lex с той, которая должна быть. Это делает функция exam( ). При совпадении происходит чтение следующей лексемы и т.д. Здесь проверяется, чтобы была лексема IDEN, затем ‘=’. Далее необязательный знак ‘+’ или ‘-‘ и в конце – NUNB.
4) DVARB → intl iden (‘,’ iden ) * ‘;’
// “Свежей” лексемы нет. Лексема INTL была использована в функции prog( ) в // switch (lex). По ней была вызвана функция dvarb( ). void dvarb( ) { do { get( ); exam(IDEN); } while(lex = = ‘,’); exam(‘;’); return; } В связи с отсутствием “свежей” лексемы необходимо вызвать get( ). Затем проверяется условие, является ли полученная лексема IDEN. В случае совпадения в конце функции exam( ) следует вызов get( ). Если будет прочитана лексема ”запятая”, то вновь в цикле do while повторяются get( ) и exam(IDEN). После того, как очередная лексема не будет равной ‘,’ , происходит выход из цикла и проверяется наличие ‘;’.
5) DFUNC → iden PARAM BODY
// Лексема IDEN была использована в функции prog( ) в switch(lex). Нужно //вызвать get( ) для получения новой лексемы. void dfunc( ) { get( ); // получение новой лексемы param( ); body( ); return; }
6) PARAM → ‘(’ [ iden ( ‘,’ iden) *] ‘ )’
Перед вызовом функции param( ) из dfunc( ) был вызов get( ). Следовательно, “свежая” лексема имеется. void param( ) { exam (‘(‘); if (lex!=’)’ ) { exan (IDEN); while (lex = =’,’) { get( ); exam (IDEN); } } exam (‘)’); return; } В соответствии с синтаксической диаграммой вначале проверяется условие, является ли прочитанная лексема левой скобкой ‘(‘. Это делает exam(‘(’). При совпадении в функции (‘)’). В случае совпадения функция exam( ) вызывает get( ) и поставляет новую лексему. Если это не ’)’, то должна быть IDEN. И вновь-таки, если после проверки лексемы IDEN была прочитана лексема ‘,’, то в цикле выполняется exam (IDEN). После выхода из цикла лексема должна быть ‘)’ и никакая другая.
7) BODY → beginl (DCONST |DVARB) * STML endl
Функция bоdy( ) вызывается из dfunc( ) после param( ). Функция param( ) заканчивается вызовом exam(‘)’). Следовательно, в случае успешной проверки будет вызвана get( ), и появится новая лексема. Она должна быть BEGINL. void body( ) { exam (BEGINL); while(lex = = INTL || lex = = CONSTL) if (lex = = INTL) dvarb( ); else dconst( ); stml( ); exam(ENDL); return; } Лекция 8
8) STML → STAT (‘;’ STAT)*
Перед вызовом stml( ) выполнялось dconst( ). В начале этой функции есть exam(‘;’). При успешной проверке вызывается get( ) , и она возвращает новую лексему.
void stml( ) { stat( ); while (lex = = ‘;’) { get( ); stat( ); } return; }
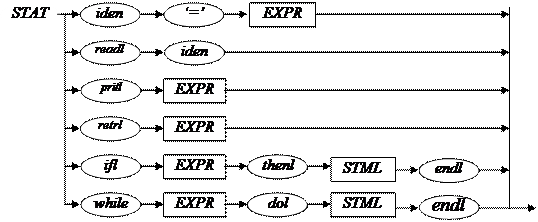
9) STAT → iden ‘=’ EXPR | readl iden | pritl EXPR | retrl EXPR | ifl EXPR thenl STML endl | whilel EXPR dol STML endl
Перед вызовом stat( ) “свежая” лексема есть. В зависимости от ее значения идет разветвление по switch (lex). void stat( ) { switch (lex) { case IDEN: get( ); exam (‘=’); expr( ); break; case READL: get( ); exam (IDEN); break; case PRITL: get( ); expr( ); break; case RETRL: get( ); expr( ); break; case IFL: get( ); expr( ); exam(THENL); stml( ); exam(ENDL); break; case WHILEL: get( ); expr( ); exam(DOL); stml( ); exam(ENDL); break; default: printf(“Синтакс. ошибка в stat в строке nst=%i \n”, nst); } return; }
10) EXPR → [‘+’|’-’] TERM ((‘+’|’-’)TERM)*
//“Свежая” лексема есть void expr( ) { if (lex = = ‘+’ || lex = = ‘-‘) get( ); term( ); while (lex = = ‘+’ || lex = = ‘-‘) { get( ); term( ); } return; }
11)TERM→FACT ((’*’|’/’| ‘%’)FACT)*
//Есть «свежая» лексема void term(); { fact(); while(lex = =’*’||lex = =’/’||lex = = ‘%’) { get(); fact(); } return; }
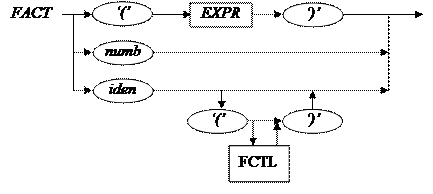
12) FACT →‘(’EXPR’)’|numb| iden [‘(‘[FCTL]’)’]
void fact() { switch(lex) { case ‘(’: get(); expr() ;exam(‘)’); break; case NUMB: get(); break; case IDEN: get(); if(lex = =’(‘) { get(); if(lex !=’)’) fctl (); exam(‘)’); } break; default : printf (“ Ошибка синтаксиса в fact. lex =%d номер строки nst=%d \n”,lex, nst); } return; }
Функция fact() всегда вызывается после get(). Следовательно, есть новая лексема. В зависимости от ее значения происходит переход на одну из трех ветвей. В любой из них вначале вызывается get(), чтобы получить следующую лексему. Затем происходит анализ в соответствии с регулярными выражениями и синтаксической диаграммой.
13)FTCL →EXPR(‘,’EXPR)*
//Есть новая лексема void fctl() { expr(); while(lex = = ‘,’) { get(); expr(); } return; }
Лекция 9 Интерпретация Программа, написанная на SPL в процессе работы программы - интерпретатора на Си преобразуется в последовательность неких промежуточных команд, список которых будет приведен ниже. Эти команды описаны в виде структуры.
typedef struct { int cod; int opd; } cmd; Структура команды содержит поле кода (int cod) и поле операнда (int opd). Код сообщает о том, что нужно делать, а операнд – над чем производится действие. Команды заносятся в таблицу команд, представляющую собой массив cmd TCD[300]; Кроме команд, имеется память для данных, которая моделируется стеком int st[500]. В самом начале стека в st[0], st[1], st[2] и т. д. размещаются глобальные переменные. Их количество определяется значением глобальной переменной int cgv = 0; Её значение инициализируется нулем и затем изменяется в процессе синтаксического анализа. После глобальных размещаются фактические переменные функции main(). За ними- количество фактических переменных. Затем следуют два адреса: адрес возврата (АВОЗ) и адрес активации (ААК). Для функции main() - это соответственно -2 и -1.После этого заносятся локальные переменные для функции main() . При вызове функцией main() другой функции в стеке, как и для main(), выделяется запись активации этого вызова. Теперь уже для вызываемой функции сначала заносятся фактические параметры р1 , р2 , … рn , их количество- n, адрес возврата АВОЗ в таблице команд, адрес предыдущей записи активации в стеке (откуда состоялся вызов функции) ААК, локальные переменные для вызываемой функции. Количество вызовов из одной функции других функций ограничено величиной стека. В принципе оно не лимитируется. При описании структуры стека в компьютерной программе используются указатели: t- вершина стека (top); sp- начало области локальных переменных функции (запись активации). Фактические параметры вызываемой функции размещаются ниже sp. Конкретное местонахождение каждого из них определяется как st[sp+k], где k- смещение(относительно sp). Для фактических параметров k<0 и оно определяется по формуле - (n+2), …, -4,-3. Здесь n – количество фактических параметров. В st[sp-2]- количество фактических параметров. В st[sp-1]- адрес возврата, а в st[sp] – ААК. Для локальных переменных смещение k>0.
Пример. Пусть вызывается функция a(x,y,z) begin int v,w end Смещение: для x- - (3+2)=-5 для y- =-4 для z- =-3 для v- =1 для w- =2
Таким образом, переменные x,y,z,v,w соответственно находятся в st[sp-5], st[sp-4], st[sp-3], st[sp+1], st[sp+2].
Таблицы интерпретатора
Ранее уже говорилось о таблице идентификаторов char TNM [400] и таблице команд cmd TCD [300]. При заполнении таблицы команд используется счетчик, представленный глобальной переменной int tc=0; Вначале tc=0. Затем его значение увеличивается при занесении очередной команды в таблицу команд TCD. Кроме упомянутых, имеются также таблица объектов и таблица функций. В таблице объектов находится информация об объектах - константах, глобальных и локальных переменных.
Объект представлен структурой. typedef struct { char * name; int what; int val; } odc; Первое поле содержит идентификатор объекта, под которым он записан в таблице идентификаторов TNM. int what может принимать значения: 1- объект является константой; 2- объект – глобальная переменная; 3- объект- локальная переменная; int val – это числовое значение для константы или же смещение k в стеке для переменных. Таблица объектов представлена глобальным массивом odc TOB [100]. Используется также глобальный указатель pto на первый свободный элемент в таблице объектов. При описании в него заносится адрес нулевого элемента таблицы TOB. odc *pto = TOB; Используется также указатель odc *ptol- начала описания локальных данных. В него при описании также заносится начальный адрес таблицы TOB. odc *ptol = TOB; Еще при заполнении TOB используется глобальная переменная int out=1. Она используется в качестве признака для обрабатываемой переменной. Если out=1, то переменная глобальная, а если out=0, то локальная.
Таблица функций
Содержит сведения о функциях. Функция представлена структурой typedef struct { char*name int isd; int cpt; int start; } fnd;
Таблица функций представлена глобальным массивом fnd TFN[30]. Используется также глобальный указатель ptf на первый свободный элемент в этой таблице. При описании в него заносится адрес первого элемента. fnd *ptf=TFN. Первое поле- имя функции, под которым она описана в таблице идентификаторов TNM. Компонент TFN[i].isd указывает, описана функция или нет. Если описана, то TFN[i].isd=1 , иначе - равна нулю. Компонент TFN[i].start содержит адрес точки входа в таблице команд для описанной функции или указатель цепочки вызовов для обратного заполнения- для описанной. TFN[i].cpt указывает количество параметров функции.
Лекция 10 Работа с таблицами
Для заполнения таблицы объектов, функций, команд и работы с ними используются специальные функции. Эти функции вызываются т.н. расширенными функциями, которые используются при синтаксическом анализе. Ранее уже говорилось о том, что для каждого нетерминального символа имеется функция для анализа выводимых из него цепочек. Результатом такого анализа является обнаружение синтаксических ошибок. Расширенные функции помимо указанного выше анализа еще дополнительно заполняют таблицы TOB, TFN и TCD, вызывая для этого специально предназначенные для этого функции. Ниже приведены эти функции. Функции для работы с таблицами объектов
/*newob -функция занесения в TOB нового объекта */ void newob(char*nm, int wt, int vl) { odc*p,*pe; pe=out? TOB: ptol; for(p=pto-1: p>=pe; p - -) if(strcmp(nm,p→name)= =0) { puts(“Функция описана дважды”); exit(1); } if(pto>= TOB+100) { puts(“Переполнение ТОВ”); exit(1); } p→name = nm; p→what=wt; p→val=vl; pto++; return; } Если out=1, это означает, что переменная глобальная, а если out=0, то локальная. В зависимости от этого поиск происходит по условию p>=TOB или p>=ptol. Напомним, что ptol- указатель начала описания локальных данных. В случае, если объект с заданным именем nm в ТОВ не имеется и ТОВ не переполнена, происходит занесение данных о новом объекте. После этого указатель pto на первый свободный элемент в ТОВ увеличивается на единицу. Если этого не сделать, то в ТОВ будет присутствовать только один объект, который заносится последним. /*функция findob() поиска элемента в TOB */ odc *findob(char*nm) { odc*p; for(p=pto-1: p>=TOB; p - -) if(strcmp(nm,p→name)= =0) return p; printf(“Объект %s не описан \n”, nm); exit(1); return p; } В случае, если объект не описан, предусмотрено сообщение об этом и прекращение работы программы. Еще один return p; написан только для того, чтобы не было сообщения об ошибке из-за несоответствия возвращаемого результата.
Функции для работы с таблицей функций
Функция занесения в TFN нового элемента fnd*newfn(char*nm, int df, int cp, int ps) { if(ptf>=TFN+30) { puts(“Переполнение TFN”); exit(1); } ptf→name = nm; ptf→isd=df; ptf→cpt=cp; ptf→start=ps; return ptf + +; } Напомним, что ptf указывает на первый свободный элемент в массиве fnd TFN[30]. Вначале осуществляется проверка, что TFN не переполнена. Если это так, то происходит занесение данных о новой функции и увеличение ptf на единицу.
Поиск функции в TFN fnd*findfn(char*nm) { fnd*p; for(p=ptf-1: p>=TFN; p - -) if(strcmp(nm,p→name)= =0) return p; return NULL; } Осуществляется поиск в TFN функции с заданным именем char*nm. Если такая функция будет найдена, то возвращается ее адрес, находящийся в указателе fnd*p. Иначе- возвращается ноль.
Вызов функции fnd*eval(char*nm, int cp) Цель. Вызвать findfn() и убедиться, что требуемая функция описана. Если она не описана, то вызвать функцию newfn(nm,0,cp,-1). Если описана, то проверить совпадение количества параметров. Если совпадает, то вернуть адрес, по которому функция находится в TFN. Иначе - сообщить об ошибке и прекратить выполнение программы.
fnd*eval(char*nm, int cp) { fnd*p; if(!p=findfn(nm)) return newfn(nm,0,cp,-1); if(p→cpt= =cp) return p; printf(“У функции %s не совпадает количество параметров \n” , nm); exit(1); return p; } После exit(1) еще один return p стоит только для того, чтобы компилятор не выдавал сообщение об ошибке из-за несоответствия типа возвращаемого результата.
Описание функции void defin(char*nm, int cp, int ad) { fnd*p; int c1,c2; p=findfn(nm); if(p) { if(p→isd) { printf(“Функция %s уже описана \n”,nm); exit(1); } if(p→cpt!=cp) { printf(“У функции %s не совпадает количество параметров \n”,nm); exit(1); } p→isd=1; for(c1=p→start;c1!=-1;c1=c2) { c2=TCD[c1].opd; TCD[c1].opd=ad; } p→start=ad; }// Для if(p) else newfn(nm,1,cp,ad); return; } Здесь nm, cp, ad соответственно имя описываемой функции, количество параметров и точка выхода для нее. Вначале осуществляется поиск функции по ее имени nm в TFN. В случае если такая функция есть, проверяется, не была ли она уже описана и совпадает ли количество параметров. Если функция еще не была описана и количество параметров совпадает, то присваивается p→isd=1. Это означает, что функция теперь уже описана. В этом месте следует вспомнить, что компонента TFN[i].start задает адрес точки входа для описания функции или же , если функция неописана,, указатель цепочки вызовов для обратного заполнения. На рисунке 3 показана ситуация, когда есть три вызова неописанной функции с именем SUM, имеющей n параметров.
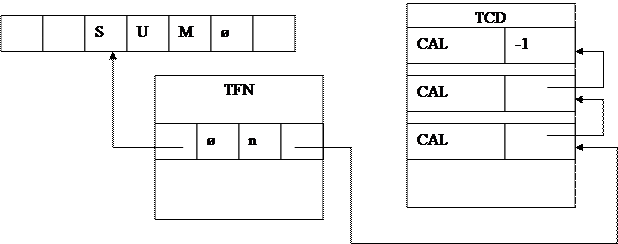 
Рисунок 3
В функции defin() обратное заполнение осуществляется в цикле for(). В самом начале в p→start находится адрес в TCD, откуда был последний вызов неописанной функции. По этому адресу находится команда gen(CAL, p→start). Он заносится в с1. До тех пор, пока с1≠-1 осуществляется последовательное обратное заполнение. В конце присваивается p→start=ad. В случае, если findfn(nm) не нашла в TFN функцию с именем nm, вызывается newfn(nm,1,cp,ad). То есть происходит занесение в TFN функции и сразу же ставится признак, что она описана.
Функция поиска функции main() и неописанных функций
fnd*fmain() { static сhar nm[]=”main”; fnd*pm=NULL; fnd*p; for(p=ptf-1;p>=TFN; p - -) { if(!p→isd) { printf(“Функция %s не описана \n”, p→name); exit(1); } if(strcmp(nm, p → name)= = 0) pm=p; }// закрыли цикл for() if(pm) return pm; puts(“Нет функции main”); exit(1); return pm; }
Второй раз return pm; после exit(1) написано только для того, чтобы компилятор не указывал на ошибку. Если функция main() не будет найдена, то после сообщения об этом выполнится exit(1); и до оператора return pm; выполнение программы не дойдет.
Лекция 11 Команды SPL
Программа, реализующая интерпретатор, должна осуществить перевод текста программы на языке SPL в последовательность некоторых команд, занесенных в таблицу команд TCD. Затем эта последовательность команд выполняется. Какие это промежуточные команды и сколько их - это решает программист. В рассматриваемом интерпретаторе используется 10 команд. Каждая из них представлена целым положительным числом. Для удобства все они описаны в виде перечня целых констант. Это позволяет промежуточную команду в программе-интерпретаторе описать в виде сокращенного слова на английском языке. При этом каждому такому сокращению соответствует целое число. Итак, имеется глобальное описание перечисленных констант. enum{OPR,LIT,LDE,LDI,STE,STI,CAL,INI,JMC, JMP}; Напомним, что по умолчанию OPR соответствует целое число ноль. Соответственно LIT-единица, LDE- два и т. д.
В команде с кодом OPR есть десять операций. 1) OPR 1-ввести в вершину стека число из файла stdin (с клавиатуры). OPR 2- число из вершины стека выводится на экран дисплея (в файл stdout). OPR 3, OPR 4, OPR 5, OPR 6, OPR 7- выполняют соответственно операции + , - ,* , / , % над двумя верхними числами в стеке. При этом первый операнд находится вt-1, а второй - в вершине стека t. Результат всегда будет в вершине стека. OPR 8- изменение знака на противоположный у числа в вершине стека . OPR 9- возвращение из функции (return). Возвращается число, находящееся в вершине стека. При возвращении из main(), если счетчик команд p=-1, печатается результат. О счетчике команд р более подробно будет рассказано позже. OPR 10 – остановка. 2) LIT а- загрузка константы а в вершину стека t. 3) LDE а- загрузка значения глобальной переменной в вершину стека. а- смещение этой переменной в стеке. 4) LDI а- загрузка значения локальной переменной со смещением а в вершину стека . 5) STE а-число из вершины стека заносится в качестве глобальной переменной, имеющей смещение а. Иными словами , глобальной переменной, которая находится в st[a], присваивается значение из вершины стека. 6) STI а-число из вершины стека заносится в качестве локальной переменной, у которой сдвиг в стеке равен а. Осуществляется занесение из вершины стека в st[sp+a], где sp- адрес в стеке, с которого заносятся локальные переменные. 7) CAL а-вызов функции с точкой входа а в таблице команд TCD. 8) INI а–увеличение адреса вершины стека на а (выделение памяти). 9) JMC а-безусловный переход на команду с номером а в таблице команд TCD. 10) JMP а-условный переход на команду с номером а. Если число в вершине стека меньше или равно нулю, то переход осуществляется. Иначе- нет. Важно помнить, что после проверки условия содержание вершины стека пропадает.
Создание SPL –программы
Выше уже говорилось о том, что во время синтаксического анализа с помощью расширенных функций для нетерминальных символов заполняются таблицы ТОВ, TFN, TCD. Таблица идентификаторов TNM заполняется при лексическом анализе. При заполнении таблицы команд TCD выражения переводятся в обратный польский вид, когда а+b выглядит как <а><b>+. Константа или число со значением val переводится в команду {LIT val}. Локальная или глобальная переменная d со смещением в стеке а переводится соответственно в {LDE a} или в{LDI a}. Эти команды соответствуют вызову глобальной или локальной переменных, то есть занесение их значений в вершину стека t. Вызов функции f(e1,e2,…en)с точкой входа а в TCD переводится в последовательность команд <e1><e2>…<en> {LIT n } {CAL a}, где <ei>- результат перевода выражения ei. {LIT n } заносит в стек количество параметров. Изменение знака у выражения переводится в <e>{OPR 8}. Выполнение одной из арифметических операций для двух операндов e1 и e2 переводится в последовательность < e1>< e2>{OPR Если в программе на языке SPL встречается присвоение глобальной переменной d значение e, где d имеет смещение в стеке, равное а, то оно будет заменено на последовательность <e>{STE a}. Присвоение для локальной переменной со смещением а выглядит как <e>{STI a}. Оператор ввода read d заменяется на {OPR 1}{STE a}для глобальной переменной d и на {OPR 1}{STI a} – для локальной. Здесьа-смещение в стеке. Операторы print e, return e переводятся соответственно в d <e>{OPR 2},<e>{OPR 9}. То есть число e, находящееся в вершине стека t, выводится на экран или возвращается из функции. Оператор условной передачи управления if e then s end проверяет значение e в вершине стека. Если это число больше нуля, то выполняется последовательность s команд, находящаяся между then и end. Затем выполняется следующий за if оператор. Если е≤0, то управление сразу передается этому оператору. Это реализуется с помощью следующей последовательности команд в TCD <e>{JMC l} <s> l, где l- номер первой команды после последовательности команд s в TCD.
Оператор цикла while e do s end переводится в последовательность промежуточных команд lb:<e>{JMC l}<s>{JMP lb} l. Здесь lb- номер команды в TCD, по которой было получено результат е в вершине стека. l- номер команд в TCD, следующий за командой {JMP lb}. В начале проверяется число ев вершине стека. Если оно больше нуля , то выполняется последовательность sкоманд, стоящих между do и end. Затем выполняется безусловная передача управления команде с номером lb в TCD. Вновь проверяется е и т.д. Если е≤0, происходит переход на команду номер lв TCD (выход из цикла.) Рассмотрим, как выглядит описание функции. На языке SPL оно имеет вид f(параметры) begin описание локальных переменных и констант; операторы end Это описание переводится в последовательность команд a:{INI m} <s> {OPR 10} Здесь a- точка входа в функцию (номер первой команды в TCD для этой функции); m- количество локальных переменных. s- последовательность команд, соответствующих операторам между begin и and. Пример. Имеется программа на языке SPL
main(x,y) begin int c; read c; c=x-y/c; if c then return c end
Рассмотрим, в какую последовательность промежуточных команд будет переведен этот текст. У функции main() имеются два параметра x и y и одна локальная переменная с. Смещение для параметров определяется в соответствии с ранее приведенным правилом через их количество n. Смещение для x равно –(n+2)=-4. Соответственно сдвиг для yравен -3. Для локальной переменной с сдвиг равен 1. Таким образом, переменные x ,y, c находятся в стеке по адресам st[sp-4], st[sp-3], st[sp+1]. После перевода текста программы в таблице команд появится последовательность промежуточных команд, приведенных в таблице.
Напомним, что таблица TCD представляет собой массив структур cmd TCD [300]. В каждой структуре описана команда (что делать) и операнд (над чем производить операцию). Таким образом, содержимое TCD в виде кодов имеет следующий вид.
Таким образом, в таблице команд находится последовательность промежуточных команд, полученных в результате перевода программы с алгоритмического языка SPL.
Лекция 12 Заполнение таблицы команд
Эта таблица заполняется расширенными функциями body(), stat(), expr(), term(), fact(). Заполнение осуществляется вызовом специально предназначенной для этого функцией gen()/. Предварительно нужно в программе интерпретатора добавить следующие глобальные переменные: int cgv=0, clv=0;//количество глобальных и количество локальных переменных int tc=0; //счетчик количества команд, занесенных в TCD int out=1 //если out=1, то переменная глобальная. Если out=0, то- локальная
Программа занесения команд в таблицу команд
int gen(int co, int op) { if (tc>=300) { puts(“Переполнение TCD”); exit(1); } TCD[tc].cod=co; TCD[tc].opd=op; return tc + +; } Следует обратить внимание на return tc + +. Возвращается адрес в TCD, куда будет заноситься следующая команда.
Расширенная функция body()
int body() { int st;//Адрес точки входа в функцию exam(BEGINL); clv=0;//Обнулить количество локальных переменных. while(lex = = INTL|| lex = = CONSTL) if (lex = = CONSTL) dconst(); else dvarb();//Возвращает значение clv st = gen(INI, clv);//Адрес команды в TCD является точкой входа в функцию stml(); exam(ENDL); gen(OPR, 10);//Генерация команды «останов» return st ;//Возвращает точку входа в функцию. } По сравнению с нерасширенной функцией body() имеет место определение точки входа в функцию и вызов функции gen() для занесения в TCD определенных команд.
Расширенная функция stat()
void stat() { int t1, t2; odc*p; switch(lex) { case IDEN: p= findob((char*)lval); get(); exam(‘=’); expr(); if(p→what = =1); { printf(“%s- константа. Нельзя присваивать \n”,p→name); exit(1) } gen (p->what == 2 ? STE : STI, p->val) ; break; case READL: get(); p = findob ((char *)lval); gen (OPR, 1); if (p->what == 1) { printf ("%s константа\n", p->name); exit(1); } gen (p->what == 2 ? STE : STI, p->val); exam (IDEN); break; case IFL: get(); expr(); exam (THENL); t1 = gen (JMC, 0); stml(); exam (ENDL); TCD[t1].opd = tc; break; case WHILEL: get(); t1 = tc; expr(); exam (DOL); t2 = gen (JMC, 0); stml(); gen (JMP, t1); TCD[t2].opd = tc; exam (ENDL); break; case PRITL: get(); expr(); gen (OPR, 2); break; case RETRL: get(); expr(); gen (OPR, 9); break; default: printf(“Недопустимая лексема lex=%i в строке nst=%i \n”, lex, nst); } return; }
По case IDEN вначале происходит поиск объекта в TOB по имени (char*) lval. Напомним, что lval- значение лексемы. Для константы это число, а для переменных – адрес в таблице идентификаторов TNM. Используется явное преобразование типа int lval на указатель (char*,) поскольку для функции findob(char*name) параметром является именно указатель char*. Эта функция возвращает указатель odc*p. Если р→what равен 1, то это означает , что найденный объект – константа, а значит присваивать нельзя. Программа по еxit(1) прекращает работу. Если р→what равен 2, то объект является глобальной переменной. Тогда генерируется команда занесения глобальной переменной gen ( STЕ, p->val). Иначе заносится локальная переменная gen (STI, p->val). Напомним, что p->val определяет смещение обьекта в стеке. Например, в рассмотренной выше программе смещение для локальной переменной c равно 1. Соответственно команда присваивания числа из вершины стека переменной c имеет вид gen (STI, 1). 
Не нашли, что искали? Воспользуйтесь поиском по сайту: ©2015 - 2026 stydopedia.ru Все материалы защищены законодательством РФ.
|
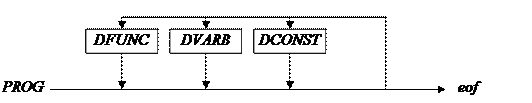




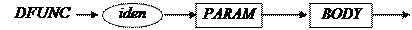

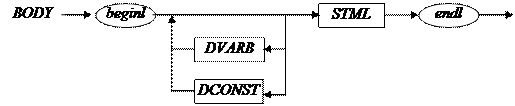
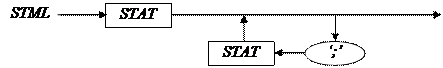

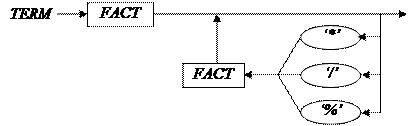
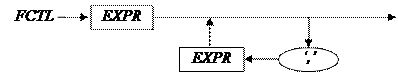
 }, где
}, где