|
|
Разработка текстового редактора
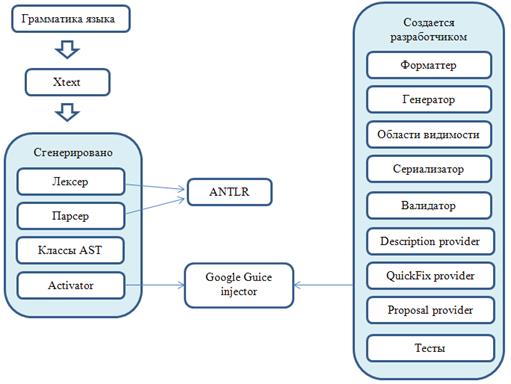
Для разработки языка была выбрана платформа разработки языков Xtext, встраиваемая в интегрируемую среду Eclipse. Платформа представляет собой инструментарий, включающий специальные языки и программные компоненты для описания различных аспектов предметно-ориентированного языка и реализации следующих основных компонентов: синтаксического и семантического анализаторов, абстрактного синтаксического дерева, сериализатора, форматирования кода, компонента сворачивания кода, линковщика, генератора и интерпретатора. Данные компоненты основаны и интегрируются с Eclipse Modelling Framework (EMF – платформа моделирования Eclipse) [41]. Гибкость архитектуры Xtext позволяет заменять часть готовых компонентов инструментария на собственные за счет использования технологии встраивания зависимостей (dependency injection) Google Guice [42]. Процесс построения транслятора в рамках технологии Xtext предполагает проведение следующих этапов работ: 1) разработка грамматики языка и реализация синтаксического анализатора; 2) наложение семантических ограничений на синтаксические конструкции языка как валидации синтаксически корректной программы на разрабатываемом языке; 3) разработка генератора кода целевого языка по синтаксическому дереву, полученному на первых двух этапах; 4) доработка необходимых графических компонентов инструментария. Общая схема разработки текстового редактора при помощи технологии Xtext приведена на рисунке 2.7.
Рисунок 2.7 - Схема разработки текстового редактора при помощи технологии Xtext
Описание языка
Синтаксис языка описывается в виде грамматики на языке Xtext. Язык Xtext специализирован для описания грамматик текстовых языков; позволяет описать синтаксис и семантику LL(*)-языка. Платформа предоставляет возможность получить синтаксический анализатор автоматизировано по описанной грамматике языка. Xtext можно считать оберткой над другим инструментом автоматизированной разработки трансляторов – ANTLR [43], который непосредственно генерирует парсер, производящий лексический, синтаксический анализ и частично семантический. В качестве алгоритма разбора сгенерированного парсера используется алгоритм рекурсивного спуска с откатами. Результатом прохождения лексического, синтаксического и семантического анализа является синтаксическое дерево (AST), описывающее структуру языка. Грамматика в Xtext состоит из набора терминальных (лексических), синтаксических правил (правил вывода) и правил типов данных. Терминальные правила описываются в текстовой форме, подобной расширенной форме Бекуса-Наура, и используются для описания терминальных символов. На вход синтаксическому анализатору подается последовательность терминальных символов, которые он обрабатывает в соответствии с правилами вывода, в результате чего выдает синтаксическое дерево. Грамматика разработанного языка приведена в приложении Б. В качестве особенностей описания синтаксиса в Xtext можно отметить возможность описывать скрытые терминальные символы, которые могут встречаться в любых местах пользовательской программы (между другими терминальными символами). Это позволяет, к примеру, реализовать возможность вставки комментариев пользователем в любую часть своей программы, также это формализует описание грамматики в отношении пробелов и отступов, позволяя абстрагироваться от этих деталей реализации. Также особенностью нотации Xtext является возможность описания действий по созданию узлов AST-дерева в грамматике, возможность использования синтаксических предикатов. Рассмотрим подробно все виды правил в грамматике Xtext. 1) Правила терминалов (лексем) Каждое терминальное правило на языке Xtext имеет так называемый возвращаемый тип, объект которого будет создан на этапе построения дерева разбора. Каждый такой тип наследуется от типа EDataType из пакета Ecore платформы моделирования Eclipse. По умолчанию возвращаемый правилом тип определяется как String, однако можно установить любой наследуемый от EDataType тип, зарегистрировав при этом свой конвертер значения в этот тип из стандартного строкового типа. 2) Правила данных Также как и терминальные правила, правила данных имеют тип возвращаемого экземпляра EDataType, однако в отличие от них эти правила фактически являются правилами разбора и поэтому они контекстно-зависимы и могут включать в себя скрытые терминалы. В данных правилах не может быть операторов создания объектов синтаксического дерева и вызовов других правил в отличие от правил разбора. 3) Правила разбора По умолчанию возвращаемый тип объекта дерева совпадает с именем правила и наследуется от EClass. Создание объектов определенных типов при разборе по определенному правилу производится за счет действий (actions). В частности, создание экземпляра определенного типа производится за счет использования простого действия. В теле терминального правила описываются свойства создаваемого объекта, которые должны быть встречены во входном тексте. Возможно описывать правила без действий и без свойств, в таком случае возвращаемое значение правила должно быть одним из возвращаемых значений описанных в нем правил-альтернатив, в данном объекта, соответствующего этому правилу, в дереве разбора создаваться не будет. При этом для перечисленных в таком правиле альтернатив создается супертип.

Не нашли, что искали? Воспользуйтесь поиском по сайту: ©2015 - 2026 stydopedia.ru Все материалы защищены законодательством РФ.
|