|
|
Меры центральной тенденцииОБРАБОТКА ДАННЫХ После сбора данных исследователь приступает к их обработке и получает сведения более высокого уровня, называемые результатами. В научном исследовании: полученные на предыдущем этапе «сырые» данные путем их обработки приводят в определенную сбалансированную систему, которая становится базой для дальнейшего содержательного анализа, интерпретации и научных выводов и практических рекомендаций. Обработка данных направлена на решение следующих задач: 1) упорядочивание исходного материала, преобразование множества данных в целостную систему сведений, на основе которой возможно дальнейшее описание и объяснение изучаемых объекта и предмета; 2) обнаружение и ликвидация ошибок, недочетов, пробелов в сведениях; 3) выявление скрытых от непосредственного восприятия тенденций, закономерностей и связей; 4) обнаружение новых фактов, которые не ожидались и не были замечены в ходе эмпирического процесса; 5) выяснение уровня достоверности, надежности и точности собранных данных и получение на их базе научно обоснованных результатов. Рассматриваемый этап обычно связывается с обработкой количественного характера. Качественная сторона обработки эмпирического материала имеет два уровня: уровень обработки данных, где проводится организационно-подготовительная работа по первичному выявлению и упорядочиванию качественных характеристик изучаемого объекта, и уровень теоретического проникновения в сущность этого объекта. Работа первого типа характерна для стадии обработки данных, а второго – для этапа интерпретации результатов. Результат в данном случае понимается как итог и количественного, и качественного преобразования первичных данных. Количественная обработкаэтоманипуляция с измеренными характеристиками изучаемого объекта (объектов), с его «объективизированными» во внешнем проявлении свойствами. Качественная обработка – это способ предварительного проникновения в сущность объекта путем выявления его неизмеряемых свойств на базе количественных данных. Количественная обработка направлена в основном на формальное, внешнее изучение объекта, качественная – преимущественно, на содержательное, внутреннее его изучение. В количественном исследовании доминирует аналитическая составляющая познания, что отражено и в названиях количественных методов обработки эмпирического материала, включающих в себя категорию «анализ» корреляционный анализ, факторный анализ и т. д. Реализуется количественная обработка с помощью математико-статистических методов. В качественной обработке доминирует синтетическая составляющая познания, причем в этом синтезе превалирует компонент, объединения и в меньшей степени присутствует компонент обобщения. Обобщение – прерогатива последующего этапа исследовательского процесса – интерпретационного. В фазе качественной обработки данных главное заключается не в раскрытии сущности изучаемого явления, а пока лишь в соответствующем представлении сведений о нем, обеспечивающем дальнейшее его теоретическое изучение. Обычно результатом качественной обработки является интегрированное представление о множестве свойств объекта или множестве объектов в форме классификаций и типологий. Качественная обработка в значительной мере апеллирует к методам логики. Процесс количественной обработки данных имеет две фазы: первичную и вторичную. Первичная обработка На первой стадии «сырые» сведения группируются по тем или иным критериям, заносятся в сводные таблицы, а для наглядного представления данных строятся различные диаграммы и графики. Первично обработанные данные, представая в удобной для обозрения форме, дают исследователю представление о характере всей совокупности данных в целом: об их однородности–неоднородности, компактности-разбросанности, четкости–размытости и т. д. Эта информация хорошо читается на наглядных формах представления данных и связана с понятием «распределение данных». Под распределением данных понимается их разнесенность по категориям выраженности исследуемого качества (признака). Разнесенностьпо категориям показывает, как часто (или редко) в определенном массиве данных встречаются те или иные показатели изучаемого признака. Поэтому такой вид представления данных называют «распределением частот». Выраженность признака, как видели выше, может быть представлена в оценках: «есть – нет» или «равно – неравно» (номинативные данные), «больше – меньше» (порядковые данные), «настолько-то больше или меньше» (интервальные данные), «во столько-то раз больше или меньше» (пропорциональные данные). Первая категория оценок предполагает явную дискретность выраженности изучаемого признака, остальные – непрерывность (хотя бы теоретически). Проиллюстрируем это примерами. Пример для дискретных данных В трехтысячном трудовом коллективе были выбраны сто человек, которые давали ответ на вопрос: «какой цвет вы предпочитаете?». Предлагалось 6 вариантов: белый (Б), черный (Ч), красный (К), синий (С), зеленый (3), желтый (Ж). В данном случае каждый цвет – это самостоятельная категория выраженности признака «окраска». Допустим, цель – выбор дизайнером окраски рабочих помещений, где трудятся эти люди. Итоги опроса, зафиксированные в протоколе, подсчитали и занесли в таблицу 1 - табулировали. Уже табулирование и построение графиков тоже есть статистическая обработка, которая в совокупности с вычислением мер центральной тенденции и разброса включается в один из разделов статистики, а именно в описательную статистику. Таблица 1 Итоги опроса
Частота (абсолютная частота)– это число ответов данной категории в выборке, частость (относительная частота)– это отношение частоты ко всей выборке. Под выборкойпонимается все множество полученных в исследовании значений изучаемого признака (свойства, качества, состояния) объекта. В примере выборка равна 100. Понятие выборки связано с понятием генеральной совокупности(или популяции),которая представляет собой все возможное множество значений изучаемого признака. В нашем примере она равна 3000. Поскольку даже ограниченные популяции обычно весьма велики, то опыты проводятся только на выборках. Поэтому встает вопрос о репрезентативностивыборки, т. е. о том, можно ли результаты, полученные на выборке, переносить на всю совокупность. Для этого привлекают статистические методы доказательства репрезентативности. Таким образом, выборка есть часть генеральной совокупности. Краткое описание этих множеств производится с помощью так называемых описательных мер (мер центральной тенденции, разброса исвязи), вычисление которых производится при вторичной обработке данных. Значения мер, вычисленные для генеральных совокупностей, называются параметрами,для выборок – статистиками.Параметр описывает генеральную совокупность также, как статистика – выборку. Принято обозначать статистики латинскими буквами, а параметры – греческими. Правда, в психологических исследованиях этих правил не всегда строго придерживаются. На основании табличных данных можно построить диаграмму,где распределение представлено нагляднее:
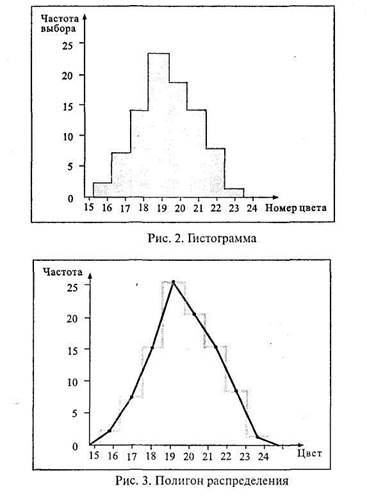
Пример для непрерывных данных Данные непрерывного характера можно представить веще более наглядной форме: в виде гистограмм, полигонов икривых. В опытах В. К. Гайды, описанных в учебном пособии для студентов-психологов, участвовало 96 испытуемых. Определялся цвет последовательного образа восприятия насыщенного красного цвета. С этой целью каждый испытуемый в течение одной минуты рассматривал окрашенный в красный цвет образец, а затем переносил взгляд на белый экран, где видел круг в дополнительных цветах. Рядом с ним находился цветовой круг с разноокрашенными секторами, на котором испытуемый должен был выбрать тот цвет, который соответствовал цвету возникшего у него последовательного образа. При этом испытуемый не называл цвет, а лишь его номер в цветовом круге. Цветовой круг нормирован таким образом, что соседние цвета отличаются в нем друг от друга на одинаково замечаемую величину. Следовательно, цветовой круг можно рассматривать как интервальную шкалу. Наряду с этим цветовой круг характеризуется и еще одним свойством. В частности, можно себе представить, что между двумя соседними цветами, например между зеленовато-голубым и голубовато-зеленым, имеется еще множество не замечаемых человеческим глазом цветовых переходов. В этом смысле цветовой круг представляет собой пример непрерывной переменной. Фактически же испытуемые всегда выделяют конечное число цветовых оттенков и поэтому свой выбор останавливают на конкретном номере (или названии) цвета. В рассматриваемом эксперименте испытуемые определяли свой последовательный образ в диапазоне от № 16 – зеленовато-голубой цвет до № 23 – желтовато-зеленый. Полученные данные можно табулировать, что и сделано в таблице 2. Таблица 2
Как видно, в построении таблиц 1 и 2 нет принципиального различия. Но разница в характере первичных данных, отображенных в обеих таблицах, все же есть, и она обнаруживается при их графическом изображении. В самом деле, рис. 2 представляет собой уже не столбиковую, а ступенчатую диаграмму, называемую гистограммой.Следует обратить внимание на то, что все участки (столбики) ступенчатой диаграммы расположены вплотную друг к другу (числовые переменные на оси абсцисс гистограммы пишут против центральной оси каждого участка). От гистограммы легко перейти к построению частотного полигона распределения,а от последнего – к кривой распределения. Частотный полигон строят, соединяя прямыми отрезками верхние точки центральных осей всех участков ступенчатой диаграммы (рис. 3). Если же вершины участков соединить с помощью плавных кривых линий, то получится кривая распределения первичных результатов (рис. 4).
Переход от гистограммы к кривой распределения позволяет путем интерполяции находить те величины исследуемой переменной, которые в опыте не были получены. Вторичная обработка Вторичная обработка завершает анализ данных и подготавливает их к синтезированию знаний на стадиях объяснения и выводов. В основном вторичная обработка заключается в статистическом анализе итогов первичной обработки. Как специфический вид вторичной обработки, выступает шкалирование, совмещающее математический, логический и эмпирический анализы данных, но в этом параграфе остановимся лишь на статистической обработке данных. Уже табулирование и построение графиков, строго говоря, тоже есть статистическая обработка, которая в совокупности с вычислением мер центральной тенденции и разброса включается в один из разделов статистики, а именно в описательную статистику. Другой раздел статистики – индуктивная статистика – осуществляет проверку соответствия данных выборки всей популяции, т. е. решает проблему репрезентативности результатов и возможности перехода от частного знания к общему. Третий большой раздел – корреляционная статистика – выявляет связи между явлениями. Всю совокупность полученных данных можно охарактеризовать в сжатом виде, если удается ответить на три главных вопроса: 1)какое значение наиболее характерно для выборки?; 2) велик ли разброс данных относительно этого характерного значения, т. е. какова «размытость» данных?; 3) существует ли взаимосвязь между отдельными данными в имеющейся совокупности и каковы характер и сила этих связей? Ответами на эти вопросы служат некоторые статистические показатели исследуемой выборки. Для решения первого вопроса вычисляются меры центральной тенденции(или локализации),второго – меры изменчивости(или рассеивания),третьего – меры связи(или корреляции).Эти статистические показатели приложимы к количественным данным (порядковым, интервальным, пропорциональным). Данные качественные (номинативные) поддаются математическому анализу с помощью дополнительных ухищрений, которые позволяют использовать элементы корреляционной статистики. Меры центральной тенденции Меры центральной тенденции (м. ц. т.) – это величины, вокруг которых группируются остальные данные. Эти величины являются как бы обобщающими всю выборку показателями, что, во-первых, позволяет по ним судить о всей выборке, а во-вторых, дает возможность сравнивать разные выборки, разные серии между собой. К мерам центральной тенденции относятся: среднее арифметическое, медиана, мода, среднее геометрическое, среднее гармоническое. В психологии обычно используются первые три. Среднее арифметическое (М)– это частное от деления всех значений (X) на их количество (N): М= SX/ N. Медиана (Me)– это значение, выше и ниже которого количество отличающихся значений одинаково, т. е. это центральное значение в последовательном ряду данных. Примеры: 3, 5, 7, 9, 11, 13, 15 Me = 9. 3,5,7,9,11,13,15,17 Me =10. Из примеров ясно, что медиана не обязательно должна совпадать с имеющимся замером, это точка на шкале. Совпадение происходит в случае нечетного числа значений (ответов) на шкале, несовпадение – при четном их числе. Мода (Мо) – это значение, наиболее часто встречающееся в выборке, т. е. значение с наибольшей частотой. Пример: 2, 6, 6, 8, 9, 9, 9, 10 Мо = 9. Если все значения в группе встречаются одинаково часто, то считается, что моды нет (например: 1, 1, 5, 5, 8, 8). Если два соседних значения имеют одинаковую частоту и они больше частоты любого другого значения, мода есть среднее этих двух значений (например: 1,2,2,2,4,4,4, 5,5,7 Мо = 3). Если то же самое относится к двум несмежным значениям, то существует две моды, а группа оценок является бимодальной (например: 0,1,1,1,2,3,4, 4, 4, 7 Мо = 1 и 4). При выборе м. ц. т. следует учесть, что: 1) в малых группах мода может быть нестабильна. Пример: 1,1,1,3,5,7,7,8 Мо = 1. Но стоит одной единице превратиться в нуль, а другой – в двойку, и Мо = 7; 2) на медиану не влияют величины «больших» и «малых» значений; 3) на среднее влияет каждое значение. Обычно среднее применяется при стремлении к наибольшей точности и когда впоследствии нужно будет вычислять стандартное отклонение. Медиана – когда в серии есть «нетипичные» данные, резко влияющие на среднее (например: 1, 3, 5, 7, 9, 26, 13). Мода – когда не нужна высокая точность, но важна быстрота определения м. ц. т. 
Не нашли, что искали? Воспользуйтесь поиском по сайту: ©2015 - 2026 stydopedia.ru Все материалы защищены законодательством РФ.
|