|
|
Размножение ДНК (репликация)12 ДНК — МОЛЕКУЛЯРНАЯ ОСНОВА ГЕНОМА Сколько истин, признаваемых нами в настоящее время бесспорными, в момент провозглашения их казались лишь парадоксами или даже ересями! Екатерина II
Что мыслимо — то возможно, что возможно — то мыслимо. Г. Лейбниц Тонкое устройство ДНК Чтобы дальнейшее повествование было более ясным для читателя, рассмотрим сначала подробнее, как же устроена эта странная и загадочная молекула ДНК. Итак, ДНК состоит из 4-х азотистых оснований, а также сахара (дезоксирибозы) и фосфорной кислоты. Два азотистых основания (сокращенно называемых Ц и Т) относятся к классу так называемых пиримидиновых основания, а два других (А и Г) — к пуриновым основаниям. Такое разделение связано с особенностями их структур, которые показаны на рис. 1.
Рис. 1. Структура азотистых оснований (элементарных «букв»), из которых построена молекула ДНК Отдельные основания связаны в цепочке ДНК сахаро-фосфатными связями. Эти связи изображены на следующем рисунке (рис. 2).
Рис. 2. Химическая структура цепи ДНК Все это известно уже довольно давно. Но детальное устройство молекулы ДНК стало понятно лишь спустя почти 90 лет после знаменитых работ Менделя и открытия Мишера. 25 апреля 1953 г. в английском журнале «Nature» было опубликовано небольшое письмо молодых и тогда еще мало известных ученых Джеймса Уотсона и Френсиса Крика редактору журнала. Оно начиналось словами: «Мы хотели бы предложить свои соображения по поводу структуры соли ДНК. Эта структура имеет новые свойства, которые представляют большой биологический интерес». Статья содержала всего около 900 слов, но — и это не преувеличение — каждое из них оказалось на вес золота. А началось все так. В 1951 году на симпозиуме в Неаполе американец Джеймс Уотсон встретился с англичанином Морисом Уилкинсом. Конечно же, они тогда не могли себе даже представить, что в результате этой встречи они станут нобелевскими лауреатами. В то время Уилкинс со своей коллегой Розалиндой Франклин проводили в Кембриджском университете рентгеноструктурный анализ ДНК и определили, что молекула ДНК представляет собой, скорее всего, спираль. После разговора с Уилкинсом Уотсон «загорелся» и решил заняться исследованием структуры нуклеиновых кислот. Он перебрался в Кембридж, где познакомился с Френсисом Криком. Ученые решили совместными усилиями попытаться понять, как устроена ДНК. Работа началась не на пустом месте. Исследователи уже знали о существовании двух типов нуклеиновых кислот (ДНК и РНК), знали и то, из чего они состоят. В их распоряжении были фотографии рентгеноструктурного анализа, полученные Р. Франклин. Кроме того, Эрвин Чаргафф сформулировал к тому времени очень важное правило, согласно которому в ДНК число А всегда равно числу Т, а число Г равно числу Ц. А далее сработала «игра ума». Результатом этой «игры» и стала статья в журнале «Nature», в которой Дж. Уотсон и Ф. Крик описали созданную ими теоретически модель строения молекулы ДНК. (Уотсону к этому времени еще не исполнилось и 25 лет, а Крику было 37). Согласно их «научной фантазии», основанной тем не менее на определенных твердо установленных фактах, молекула ДНК должна состоять из двух гигантских полимерных цепочек. Звенья каждого полимера состоят из нуклеотидов: углевода дезоксирибозы, остатка фосфорной кислоты и одного из 4 азотистых оснований (А, Г, Т или Ц). Последовательность звеньев в цепочке может быть любой, но эта последовательность строго связана с последовательностью звеньев в другой (парной) полимерной цепочке: напротив А должно быть Т, напротив Т должно быть А, напротив Ц должно быть Г, а напротив Г должно быть Ц (правило комплементарности) (рис. 3).
Рис. 3. Схема взаимодействия двух комплементарных цепей в молекуле ДНК Две полимерные цепи закручены в правильную двойную спираль. Они удерживаются вместе посредством водородных связей между парами оснований (А–Т и Г–Ц) подобно ступенькам лестницы. По этой причине говорят, что две цепи ДНК комплементарны. Для природы это не удивительно. Известно множество примеров комплементарности. Комплементарны, например, древнекитайские символы «инь» и «янь», гнезда розетки и штырьки вилки. Двойная спираль ДНК схематически изображена на рис. 4. Внешне она напоминает веревочную лестницу, завитую в правую спираль. Ступенями в этой лестнице являются пары нуклеотидов, а связывающие их «боковинки» состоят из сахаро-фосфатного остова.
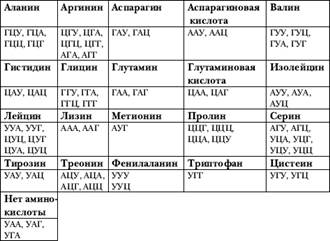
Рис. 4. Знаменитая двойная спираль ДНК а — Рентгенограмма ДНК, полученная Р. Франклин, которая помогла Уотсону и Крику найти ключ к двухспиральной структуре ДНК; б — Схематическое изображение двухспиральной молекулы ДНК Так была открыта знаменитая «двойная спираль». Если последовательность звеньев (нуклеотидов) в ДНК рассматривать как ее первичную структуру, то двойная спираль — это уже вторичная структура ДНК. Предложенная Уотсоном и Криком модель «двойной спирали» изящно решала не только проблему кодирования информации, но и удвоения (репликации) гена. В 1962 году Дж. Уотсон, Ф. Крик и Морис Уилкинс получили по достоинству за это достижение Нобелевскую премию. А ДНК была названа самой главной молекулой живой природы. Во всем этом, конечно же, сыграли свою роль точные сведения о строении ДНК, но не в меньшей мере и «провидческие» построения сложной пространственной структуры, что потребовало от исследователей не только логики, но и творческого воображения — качества, присущего художникам, писателям и поэтам. «Здесь, в Кембридже, произошло, быть может, самое выдающееся после книги Дарвина событие в биологии — Уотсон и Крик раскрыли структуру гена!» — писал в то время в Копенгаген Нильсу Бору его бывший ученик М. Дельбрюк. Известный испанский художник Сальвадор Дали после открытия двойной спирали сказал, что это для него явилось доказательством существования Бога, и изобразил ДНК на одной из своих картин. Итак, интенсивный мозговой штурм, предпринятый учеными, завершился полным успехом! В историческом масштабе открытие структуры ДНК сопоставимо с открытием структуры атома. Если выяснение строения атома привело к появлению квантовой физики, то открытие структуры ДНК дало начало молекулярной биологии. Каковыми же оказались главные физические параметры ДНК человека — этой главной его молекулы? Диаметр двойной спирали равен 2 нанометрам (1 нм = 10–9 м); расстояние между соседними парами оснований («ступеньками») составляет 0,34 нм; один поворот спирали состоит из 10 пар оснований. Последовательность пар нуклеотидов в ДНК нерегулярна, но сами пары уложены в молекуле как в кристалле. Это дало основание характеризовать молекулу ДНК как линейный апериодический кристалл. Число отдельных молекул ДНК в клетке равно числу хромосом. Длина такой молекулы в наибольшей по размеру хромосоме 1 человека составляет около 8 см. Подобных гигантских полимеров пока не выявлено ни в природе, ни среди искусственно синтезированных химических соединений. У человека длина всех молекул ДНК, содержащихся во всех хромосомах одной клетке, составляет примерно 2 метра. Следовательно, длина молекул ДНК в миллиард раз больше их толщины. Так как организм взрослого человека состоит примерно из 5х1013 – 1014 клеток, то общая длина всех молекул ДНК в организме равна 1011 км (это почти в тысячу раз больше расстояния от Земли до Солнца). Вот такая она, суммарная ДНК всего лишь одного человека! Когда говорят о размере генома, то подразумевают общее содержание ДНК в единичном наборе хромосом ядра. Такой набор хромосом называют гаплоидным. Дело в том, что большинство клеток нашего организма содержит двойной (диплоидный) набор совершенно одинаковых хромосом (только у мужчин 2 половые хромосомы отличаются). Измерения размера генома приводятся в дальтонах, парах нуклеотидов (п. н.) или пикограммах (пг). Соотношение между этими единицами измерения следующие: 1 пг = 10–9 мг = 0,6х1012 дальтон = 0,9х109 п. н. (далее мы будем использовать в основном п. н.). В гаплоидном геноме человека содержится около 3,2 млрд. п. н., что равно 3,5 пг ДНК. Таким образом, в ядре одной клетки человека содержится около 7 пг ДНК. Если учесть, что средний вес клетки человека равен примерно 1000 пг, то легко рассчитать, что ДНК составляет менее 1% от веса клетки. И тем не менее, чтобы воспроизвести самым мелким шрифтом (как в телефонных справочниках) ту огромную информацию, которая содержится в молекулах ДНК одной нашей клетки, понадобилось бы тысяча книг по 1000 страниц в каждой! Вот таков полный размер генома человека — Энциклопедии, написанной четырьмя буквами. Но не следует думать, что геном человека наибольший из всех существующих в природе. Например, у саламандры и лилии длина молекул ДНК, содержащихся в одной клетке, в тридцать раз больше, чем у человека. Поскольку молекулы ДНК имеют гигантский размер, их можно выделить и увидеть даже в домашних условиях. Вот как описывается эта простая процедура в рекомендации для кружка «Юный генетик». Во-первых, надо взять любые ткани животных или растительных организмов (например, яблоко или кусок курицы). Затем надо нарезать ткань на кусочки и положить 100 г в обычный миксер. После добавления 1/8 чайной ложки соли и 200 мл холодной воды вся смесь взбивается на миксере в течение 15 секунд. Далее взбитая смесь процеживается через ситечко. В полученную мякоть надо добавить 1/6 от ее количества (это будет примерно 2 столовые ложки) моющего средства (для посуды, например) и хорошо размешать. Через 5–10 минут жидкость разливается по пробиркам или любым другим стеклянным емкостям, чтобы в каждой из них было заполнено не больше трети объема. Затем к ней добавляется по чуть-чуть либо сок, выжатый из ананаса, либо раствор, используемый для хранения контактных линз. Все содержимое встряхивается. Делать это надо весьма осторожно, так как если трясти слишком сильно, то гигантские молекулы ДНК поломаются и после этого ничего нельзя будет увидеть глазами. Далее в пробирку медленно вливается равный объем этилового спирта, чтобы он образовал слой поверх смеси. Если после этого покрутить в пробирке стеклянной палочкой, на нее «намотается» вязкая и почти бесцветная масса, которая и представляет собой препарат ДНК. Генетическая грамматика После установления химического строения и пространственной структуры ДНК оставалось еще множество вопросов, основной из которых заключался в том, как же ДНК кодирует белки, то есть, что представляет из себя генетический код этой молекулы, какую «грамматику» она использует? На это в первую очередь и были направлены дальнейшие усилия исследователей. Итак, установлено, что «буквами» в ДНКовом тексте служат нуклеотиды — элементарные звенья полимерной молекулы ДНК. В ДНК всего 4 нуклеотида (А, Т, Г, Ц). Следовательно, если сравнить каждый из этих нуклеотидов с отдельной буквой, то алфавит ДНКового текста содержит всего 4 «буквы». Как же из этих «букв» формируются «слова» и «предложения»? Белковые молекулы всех существующих на земле организмов построены всего из 20 аминокислот. Сразу после создания модели ДНК стало ясно, что существует некий код, переводящий четырехбуквенный ДНКовый текст в двадцатибуквенный аминокислотный текст. Элементарные расчеты говорили о том, что число возможных сочетаний, в которых четыре нуклеотида могут быть по-разному расположены в «тексте», достигает астрономических значений. Так, молекула ДНК, состоящая, к примеру, всего из 100 пар нуклеотидов, может теоретически кодировать 4100 различных белковых «текстов». Какова же ситуация на самом деле? Одним из первых в этом пытался разобраться русский физик Г. Гамов, эмигрировавший в то время в Америку. Наслушавшись многочисленных разговоров о ДНК и узнав, что она содержит — как и карты — всего четыре «масти», Гамов решил «разложить пасьянс» с целью понять устройство генетического кода. Ему сразу стало ясно, что код не может быть «двоичным», то есть одну аминокислоту в белке должна кодировать не двойка нуклеотидов — «букв», а как минимум тройка. Дело в том, что сочетание из 4 по 2 дает всего 16 комбинаций, а этого недостаточно для кодирования всех 20 аминокислот. Следовательно, рассуждал Гамов, код должен быть по крайней мере трехбуквенным, то есть каждую аминокислоту должна кодировать тройка «букв» в любых сочетаниях. На этом он и остановился, поскольку далее возникало множество вопросов. В частности, такой: число сочетаний из 4 по 3 равно 64, а аминокислот всего 20. Зачем же такая избыточность в трехбуквенном коде? В то время уже существовал хорошо известный путь, который, в частности, был проделан в свое время французом Жаном Шампольоном при дешифровке иероглифов древнего Египта. В качестве основного подспорья для решения стоящей перед ним задачи он использовал базальтовую плиту, которую обнаружили во время военной компании Наполеона в Египет и которая получила название Розеттский камень. На плите одновременно присутствовали две надписи: одна была иероглифическая, а другая — сделанная греческими буквами на греческом языке. К счастью, и язык, и письмо древних греков были в то время уже хорошо известны ученым. В результате сравнение двух текстов Розеттского камня привело к расшифровке египетской иероглифики. Этим путем и двинулись ученые при расшифровке генетического кода. Надо было сравнить два текста: текст, записанный в ДНК, с текстом, записанным в белке. Однако первоначально ученые не умели «читать» ДНК, а одного известного в то время белкового текста было недостаточно. Пришлось искусственно синтезировать разнообразные короткие фрагменты РНК и синтезировать на них в искусственных системах фрагменты белка. Весной 1961 года в Москве на Международном биохимическом конгрессе М. Ниренберг сообщил, что ему удалось «прочесть» первое «слово» в ДНКовом тексте. Это была тройка букв — ААА (в РНК, соответственно, УУУ), то есть три аденина, стоящие друг за другом, — которая кодирует аминокислоту фенилаланин в белке. Так было положено начало расшифровке генетического кода. Такой путь в конечном итоге вскоре привел к полной расшифровке генетического кода. Подтвердилось предположение Гамова, что код триплетный: одной аминокислоте в белках соответствует последовательность из 3 нуклеотидов в ДНК и РНК. Такие кодирующие тройки нуклеотидов — «слова» — получили название кодонов. Напомним, что еще Гамов столкнулся с парадоксом: из четырех нуклеотидов может быть построено 64 разных кодонов, а для построения белков используется только 20 различных аминокислот. Решение этого парадокса оказалось в следующем. Большинство аминокислот может кодироваться несколькими кодонами. После выяснения этого обстоятельства генетический код назвали вырожденным. В таблице 1 приведены кодоны, но не в самой ДНК, а в РНК-посреднике (матричной РНК, или мРНК), образующейся на ДНК, и соответствующие им аминокислоты в белках. Кроме того, как видно из таблицы, реально для кодирования используются не все возможные кодоны. Три из этих «лишних» кодонов выполняют функцию стоп-сигналов, обеспечивая прекращение синтеза белковой цепи. Если внимательно посмотреть на таблицу 1, то видно, что вырожденность генетического кода носит не совсем случайный характер. Хотя код триплетный, основную нагрузку несут первые два нуклеотида в каждом кодоне. Чаще всего в разных кодонах, кодирующих одну и ту же аминокислоту, отличается лишь третий нуклеотид. Таблица 1. Генетический словарь. Указаны аминокислоты, встречающиеся в белках, и соответствующие им кодоны в комплементарной ДНК матричной РНК
Генетический код первоначально был расшифрован у таких простых организмов, как фаги и бактерии. В дальнейшем оказалось, что он универсален (за очень редким исключением) для геномов всех существующих ныне живых организмах (от бактерий до человека). Небольшие отличия, о которых мы поговорим далее, были выявлены при сравнении ядерного и митохондриального геномов. Итак, как в привычном нам тексте книги, вся информация записана в ДНК последовательностью расположения четырех составляющих ее «букв» — нуклеотидов. Таким образом, ДНКовый текст написан с помощью А, Т, Ц, Г-алфавита. При этом только текст одной из двух цепей ДНК обычно кодирующий, а другая цепь, как правило, некодирующая. Хотя известно, что в каждом правиле есть исключения. Если читатель попробует написать этими четырьмя буквами какие-нибудь русские слова, то у него ничего не получится. «Словом» в ДНКовом тексте, условно говоря, служит определенное сочетание трех нуклеотидов, которому соответствует конкретная аминокислота в белке, являющемся также полимером. Таким образом, в клетке четырьмя буквами записано два десятка «слов» (аминокислот — составных частей белков). И, наконец, как «предложение» в ДНКовом тексте можно рассматривать полный набор триплетов, кодирующих определенный белок, то есть ген. Таким образом, генетический алфавит состоит всего из 4 букв, а генетический словарь из 20 слов. В этой связи вспомним, что даже словарь Эллочки-людоедки из романа И. Ильфа и Е. Петрова «Двенадцать стульев» состоял из 30 слов, а «Словарь языка произведений А. С. Пушкина» насчитывает примерно 20 тыс. слов. Существует строгая закономерность: чем длиннее код (чем больше в нем знаков), тем короче тексты. Огромный по размерам код представляют собой, например, китайские иероглифы. В результате этого иероглифические тексты существенно более кратки по сравнению с другими системами письма, в том числе и нашей. Однако для создания генетического кода природа выбрала всего 4 «буквы». Такой код предполагает наличие длинных текстов, что и реализовалось природой в виде создания гигантских молекул ДНК. При написании полного «текста» генома человека потребовалось около 3,2 млрд. «букв». Для сравнения: в священной книге Бытия, написанной на древнееврейском языке, содержится всего 78100 букв. Размножение ДНК (репликация) Важно то, что структура ДНК, открытая Уотсоном и Криком, многое прояснила относительно разных механизмов функционирования этой молекулы в клетке. ДНК не только кодирует генетическую информацию, но и самовоспроизводится (удваивается) при каждом клеточном делении. И вскоре уже было экспериментально установлено, что одновременно с делением клетки ДНК снимает с самой себя точные копии в процессе удвоения, или репликации. Во время клеточного деления слабые связи между двумя цепями двойной спирали ДНК разрушаются, в результате чего нити разделяются. Затем на каждой из них строится вторая «дочерняя» (комплементарная) цепь ДНК. В результате этого молекула ДНК удваивается, как и клетка, и в обеих клетках оказывается по одной полной копии ДНК. Копии должны быть полностью идентичными, чтобы сохранить всю генетическую информацию. Процесс репликации играет ключевую роль в сохранении одной и той же генетической информации в разных клетках, образующихся при их делении. В общем виде художественно он изображен на рис. 5. Однако реальные механизмы репликации довольно сложны, и до настоящего времени еще не все тонкие детали этого процесса известны, особенно применительно к геномам высших животных организмов, включая человека.
Рис. 5. Схема репликации ДНК В общем виде этот процесс выглядит следующим образом. В каждой хромосоме ДНК удваивается не с начала до конца, а отдельными кусками (репликонами). Средний размер репликона составляет около 30 мкм. Тем самым в составе генома человека должно встречаться более 50 000 репликонов, участков ДНК, которые синтезируются в ядре как независимые единицы. И это имеет свой глубокий смысл. Если бы каждая из молекул ДНК удваивалась как один репликон от начала до конца молекулы, то при скорости синтеза 0,5 мкм в минуту (а она именно такова у человека) удвоение первой хромосомы, имеющей длину ДНК около 7 см, занимало бы 140 000 минут, или около трех месяцев. На самом деле благодаря полирепликонному строению молекул ДНК весь процесс занимает всего 7–12 часов. Отдельные относительно короткие репликоны соединяются друг с другом, обеспечивая этим процесс воспроизведения целой молекулы ДНК. 
12 Не нашли, что искали? Воспользуйтесь поиском по сайту: ©2015 - 2026 stydopedia.ru Все материалы защищены законодательством РФ.
|