|
|
Загрузочный блок(суперблок)и его содержимоеЗапасной блок и его назначение Кодировка в HPFS Структура раздела HPFS Каталог и его планирование. В-дерево. F-узел Способ хранения информации о занятых блоках файла. Экстенты «Ленивая» запись на диск и горячее исправление Многоуровневое кэширование Битовый массив вместо таблицы размещения файлов и повышенная отказоустойчивость Размер файлов в HPFS
HPFS - сокращенное название высокопроизводительной файловой системы (high performance file system), совместно разработанной в 1989 году корпорациями IBM и Microsoft. Эта система была разработана, чтобы преодолеть недостатки FAT, к числу которых относятся: - излишние затраты диска, вызванные большими размерами кластеров; - ограничения, налагаемые на размер файлов и дискового пространства; - ограничение длины имени файла; - фрагментация файлов и снижению быстродействия системы; - подверженность потерям данных. Проблема потерь дискового пространства связана с тем, что место на диске выделяется целыми блоками секторов - кластерами. Кластер - это единица дискового пространства, которыми оперирует файловая система при выделении места для файла. В среднем половина выделяемого кластера для каждого файла будет затрачиваться впустую. Например, при емкости диска 510 Мбайт и количестве размещенных файлов 1,5 тысячи использование FAT приведет к потере 6 Мбайт пространства, обусловленной только размером выделяемого блока. Переход на HPFS позволит сэкономить дисковое пространство. HPFS распределяет пространство, основываясь на физических 512-байтовых секторах, а не на кластерах, независимо от размера раздела. Система HPFS позволяет уменьшить и непроизводительные потери, так как в ней предусмотрено хранение до 300 байт расширенных атрибутов в F-узле файла, без захвата для этого дополнительного сектора. Другая проблема связана с фрагментацией файлов, которая наиболее характерна для емких дисков с большим числом файлов. Фрагментация существенно сказывается на времени доступа к файлу. Файловая система HPFS обеспечивает гораздо более низкий уровень фрагментации. Хотя избавиться полностью от нее не удается, снижение производительности, возникающее по этой причине, почти незаметно для пользователя. Первые 16 секторов раздела HPFS составляют загрузочный блок. Эта область содержит метку диска и код начальной загрузки системы. Сектор 16, известный под названием суперблок, содержит общую информацию о файловой системе в целом: - размер раздела, - указатель на корневой каталог, - счетчик элементов каталогов, - номер версии HPFS, - дату последней проверки и исправления раздела при помощи команды CHKDSK, - дату последнего выполнения процедуры дефрагментации раздела. - указатели на список испорченных блоков на диске, таблицу дефектных секторов и список доступных секторов. Сектор 17 носит название SpareBlock (запасной блок). Он содержит указатель на список секторов, которые можно использовать для "горячего" исправления ошибок, счетчик доступных секторов для "горячего" исправления ошибок, указатель на резерв свободных блоков, применяемых для управления деревьями каталогов, и информацию о языковых наборах символов. Система HPFS использует информацию о языковых наборах, чтобы дать возможность пересылать файлы, составленные на разных языках, даже в том случае, когда имена файлов содержат уникальные для какого-либо языка символы. SpareBlock также содержит так называемый "грязный" флаг. Этот новый флаг сообщает операционной системе о том, было ли завершение предыдущего сеанса работы нормальным, либо произошло в результате сбоя электропитания, либо файлы не были закрыты должным образом по какой-то другой причине. Если этот флаг обнаружен во время начальной загрузки, то операционная система автоматически запускает утилиту CHKDSK, пытаясь обнаружить и исправить все ошибки, внесенные в файловую систему из-за неправильного выключения системы.
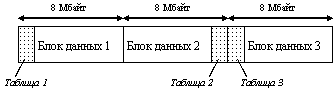
Рис. 9.3. Прием увеличения доступного непрерывного пространства Во время форматирования раздела HPFS делит его на полосы по 8 Мбайт каждая. Каждая полоса - ее можно представить себе как виртуальный "мини-диск" - имеет отдельную таблицу объемом 2 Кбайт, в которой указывается , какие секторы полосы доступны, а какие заняты. Чтобы максимально увеличить протяженность непрерывного пространства для размещения файлов, таблицы попеременно располагаются в начале и в конце полос (рисунок 9.3). Этот метод позволяет файлам размером до 16 Мбайт (минус 4 Кбайта, отводимые для размещения таблицы) храниться в одной непрерывной области. Затем файловая система HPFS оценивает размер каталога и резервирует необходимое пространство в полосе, расположенной ближе всего к середине диска. Сразу же после форматирования объем диска в HPFS кажется меньше, чем в FAT, так как заранее резервируется место для каталогов в центре диска. Место резервируется в середине диска для того, чтобы физические головки, считывающие данные, никогда не проходили более половины ширины диска. Это позволяет HPFS использовать специально оптимизированное программное обеспечение для более быстрой и эффективной работы с каталогами. В системе FAT головкам требуется пройти весь путь к началу диска и прочитать таблицу размещения файлов. И без того продолжительное время увеличивается при фрагментации. Число файлов в каждом блоке каталога - переменная величина, зависящая от длины имен файлов, которые содержатся в нем. Имена файлов в HPFS могут иметь длину до 254 символов, они сортируются в порядке, определяемом последовательностью символов в текущей кодовой странице системы. Скорость работы увеличивается также благодаря способу хранения элементов каталогов. Система FAT последовательно просматривает каждый элемент каталога, чтобы отыскать нужный файл.В HPFS использует для хранения элементов каталогов структуру данных, называемую В-деревом. Каждый элемент каталога начинается с числа, представляющего длину элемента, которая изменяется в зависимости от длины имени файла. Затем следуют время и дата создания файла, его размер и атрибуты (только для чтения, архивный, скрытый и системный), а также указатель на F-узел файла. Каждый файл (и каталог) имеет F-узел - структуру данных, занимающую один сектор и содержащую принципиально важную информацию о файле. F-узел содержит указатель на начало файла, первые 15 символов имени файла, дополнительные временные маркеры последней записи и последнего доступа, журнал, хранящий информацию о предыдущих обращениях к файлу, структуру распределения, описывающую размещение файла на диске, и первые 300 байт расширенных атрибутов файла. В F-узле может сохраняться информацию об управлении пользовательским доступом (Access Control). F-узлы хранятся в смежных с представляемыми ими файлами секторах, поэтому, когда файл открывается, то четыре автоматически считываемых в кэш сектора содержат F-узел и три первых сектора файла. Структура размещения HPFS имеет дополнительные преимущества по сравнению с FAT благодаря техническому приему, называемому кодированием по длине выполнения (Run Length Encoding, RLE). Вместо того, чтобы определять в таблице каждый используемый сектор, HPFS сохраняет указатель на первый сектор и число последовательно расположенных используемых секторов. (непрерывное хранение). Каждая область дискового пространства, описываемая парой (сектор, длина), называется экстентом. Хотя HPFS и сводит фрагментацию к минимуму, файлы все же могут быть в некоторой степени фрагментированными. В таких ситуациях пары, описывающие экстенты, добавляются к F-узлу файла. Один F-узел может хранить до 8 экстентов, обеспечивая достаточное пространство для большинства файлов. HPFS при открытии или создании файла интеллектуальный алгоритм выделяет наиболее подходящую полосу. Программный интерфейс, используемый для создания файла, позволяет программисту сообщить операционной системе предполагаемый размер файла. С помощью этой информации HPFS может заранее выбрать для размещения файла полосу, имеющую непрерывную область наибольшего размера. Именно поэтому HPFS наиболее эффективно работает в больших разделах - больше число полос предоставляет большие возможности выбора. Операции записи в кэш осуществляются особым образом, который называется "ленивой" записью. Когда программа посылает команду записи, HPFS помещает данные в кэш и немедленно сообщает программе, что операция выполнена, и только потом в фоновом режиме данные перемещаются из оперативной памяти на устройство. Это исключает длительную задержку, сопровождающую действительную операцию записи данных на устройство ввода-вывода.. Если попытка записи на диск заканчивается неудачно, то HPFS отыскивает в SpareBlock блок, который можно использовать для "горячего" исправления. Данные записываются в область "горячего" исправления, а таблицы неисправных блоков обновляются, указывая испорченный сектор и блок. HPFS будет автоматически перенаправлять запросы чтения по новому адресу. Во время очередного выполнения утилиты CHKDSK файл будет скопирован в новое место, где он может храниться в непрерывной области. При обращении к нему нет необходимости переходить к блоку "горячего" исправления и обратно. Блок будет освобожден для использования в случае возникновения другой подобной проблемы. Таким образом, проблема решается автоматически без участи пользователя. Для повышения эффективности система HPFS также предоставляет многоуровневые кэши. Поэтому при обращении к файлу, расположенному в глубоко вложенном каталоге, скорее всего будет возможен быстрый доступ сразу в нужный каталог из кэша, без поиска по дереву каталогов. HPFS обладает повышенной отказоустойчивостью по сравнению с FAT. Если на диске с FAT оказалась стертой таблица распределения файлов, то скорее всего окажутся потерянными все данные, которые находятся вне корневого каталога. В системе HPFS вместо таблицы размещения файлов применяется битовый массив, который содержит флаг, помечающий используемые секторы. Если область битового массива будет разрушена, пользователь этого не заметит, даже если это случится во время работы системы. F-узел файла также содержит информацию о размещении каждого файла. Поэтому область битового массива может быть восстановлена после поиска этой информации в F-узлах. Пользователь не увидит даже предупреждения - поиск выполняется автоматически. Этот процесс может быть запущен и с помощью утилиты CHKDSK, которая сравнивает битовый массив с информацией для файла о принадлежащих ему секторах. Если при чтении битового массива обнаруживается ошибка, то создается новый битовый массив. В системе FAT при порче каталогов теряются указатели на начало цепочки кластеров каждого файла. Можно соединить отдельные кластеры в файл, но многое придется делать в ручную. Так как утилиты, подобные CHKDSK, не знают имени файлов, то для того, чтобы восстановить их старые имена, придется загружать файлы в текстовый редактор и пытаться определить, что они из себя представляют. При работе с HPFS в случае потери каталога у каждого файла из этого каталога теряется лишь дата последней операции записи в файл и иных изменений, дата создания и длинное имя файла (символы, следующие за первыми пятнадцатью). Элемент каталога - это всего лишь указатель на F-узел. В F-узле хранятся первые 15 символов имени файла (плюс информация о том, имелись ли в имени файла другие символы, кроме первых 15) и прочая информация, нужная для доступа к файлу. Утилиты восстановления могут впоследствии найти в F- узле сведения о том или ином файле. Эта избыточность, обеспечиваемая каталогом и F-узлами, значительно увеличивает шансы на восстановление данных. CHKDSK в настоящее время - единственная утилита восстановления, поставляемая с OS/2, которая, к сожалению, пока не использует всю имеющуюся информацию. HPFS не налагает ограничений на максимальный размер файла, но OS/2 в настоящее время устанавливает предел в 2 Гбайта на один файл. Цель HPFS - доведение размера раздела до 2 Тбайт, но сегодня имеется ограничение в 64 Гбайта, поскольку некоторые части системы HPFS до сих пор остаются 16-разрядными.
Файловая система NTFS Появление NTFS NTFS, «родная» файловая система Windows NT, существенно превосходит FAT32 по производительности, абсолютно игнорируя степень фрагментированности диска. Надежность и удобство администрирования также выше, чем у FAT32. При этом NTFS критична к объему оперативной памяти и если в системе меньше 128 Mb, то NTFS к употреблению не рекомендуется – будет заметное снижение быстродействия. NTFS начала использоваться вместе с Windows NT 3.1 в 1993 году. Ее прародителем является система HPFS, разработанная совместно IBM и Microsoft для OS/2.
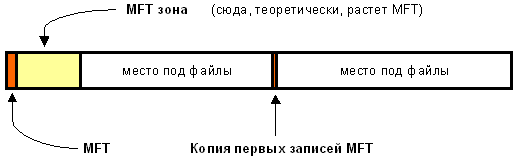
Как и любая другая система, NTFS делит все полезное место на кластеры - блоки данных. NTFS поддерживает размеры кластеров - от 512 байт до 64 Кбайт, неким стандартом же считается кластер размером 4 Кбайт. Диск NTFS условно делится на две части. Первые 12% диска отводятся под так называемую MFT зону - пространство, в которое растет метафайл MFT (об этом ниже). Запись каких-либо данных в эту область невозможна. MFT-зона всегда держится пустой - это делается для того, чтобы самый главный, служебный файл (MFT) не фрагментировался при своем росте. Остальные 88% диска представляют собой обычное пространство для хранения файлов.
Свободное место диска, однако, включает в себя всё физически свободное место - незаполненные куски MFT-зоны туда тоже включаются. Механизм использования MFT-зоны таков: когда файлы уже нельзя записывать в обычное пространство, MFT-зона просто сокращается (в текущих версиях операционных систем ровно в два раза), освобождая таким образом место для записи файлов. При освобождении места в обычной области MFT зона может снова расширится. При этом не исключена ситуация, когда в MFT зоне остались и обычные файлы: никакой аномалии тут нет. Система старается оставить её свободной. Метафайл MFT все-таки может фрагментироваться, хоть это и нежелательно. MFT и его структура. Файловая система NTFS представляет собой выдающееся достижение структуризации: каждый элемент системы представляет собой файл - даже служебная информация. Самый главный файл на NTFS называется MFT, или Master File Table - общая таблица файлов. Именно он размещается в MFT зоне и представляет собой централизованный каталог всех остальных файлов диска, и, как не парадоксально, себя самого. MFT поделен на записи фиксированного размера (1 Кбайт), и каждая запись соответствует, какому либо файлу (в общем смысле этого слова). Первые 16 файлов носят служебный характер и недоступны пользователю операционной системы - они называются метафайлами, причем самый первый метафайл - сам MFT. Эти первые 16 элементов MFT - единственная часть диска, имеющая фиксированное положение. Интересно, что вторая копия первых трех записей, для надежности (они очень важны) хранится ровно посередине диска. Остальной MFT-файл может располагаться, как и любой другой файл, в произвольных местах диска - восстановить его положение можно с помощью его самого, "зацепившись" за самую основу - за первый элемент MFT. Записи в MFT сортируются, что позволяет использовать индексированный поиск, существенно ускоряющий работу ФС. Для еще большей оптимизации диспетчером кэша используется алгоритм отложенной («ленивой») записи, когда данные не пишутся сразу на диск, а хранятся в памяти до тех пор, пока нагрузка на процессор не уменьшиться, а затем сбрасываются на диск фоновым процессом. Однако подобная практика чревата нехорошими последствиями в случае отказа питания. Журналирование не спасет пользовательских данных, хотя и обеспечит целостность структуры ФС. Метафайлы Первые 16 файлов NTFS (метафайлы) носят служебный характер. Каждый из них отвечает за какой-либо аспект работы системы. Преимущество настолько модульного подхода заключается в поразительной гибкости - например, на FAT-е физическое повреждение в самой области FAT фатально для функционирования всего диска, а NTFS может сместить, даже фрагментировать по диску, все свои служебные области, обойдя любые неисправности поверхности - кроме первых 16 элементов MFT. Метафайлы находятся корневом каталоге NTFS диска - они начинаются с символа имени "$", хотя получить какую-либо информацию о них стандартными средствами сложно. Любопытно, что и для этих файлов указан вполне реальный размер - можно узнать, например, сколько операционная система тратит на каталогизацию всего вашего диска, посмотрев размер файла $MFT. В следующей таблице приведены используемые в данный момент метафайлы и их назначение.
Файлы и потоки Итак, у системы есть файлы - и ничего кроме файлов. Что включает в себя это понятие на NTFS? · Прежде всего, обязательный элемент - запись в MFT, ведь, как было сказано ранее, все файлы диска упоминаются в MFT. В этом месте хранится вся информация о файле, за исключением собственно данных. Имя файла, размер, положение на диске отдельных фрагментов, и т.д. Если для информации не хватает одной записи MFT, то используются несколько, причем не обязательно подряд. · Опциональный элемент - потоки данных файла. Может показаться странным определение "опциональный", но, тем не менее, ничего странного тут нет. Во-первых, файл может не иметь данных - в таком случае на него не расходуется свободное место самого диска. Во-вторых, файл может иметь не очень большой размер. Тогда идет в ход довольно удачное решение: данные файла хранятся прямо в MFT, в оставшемся от основных данных месте в пределах одной записи MFT. Файлы, занимающие сотни байт, обычно не имеют своего "физического" воплощения в основной файловой области - все данные такого файла хранятся в одном месте - в MFT. Довольно интересно обстоит дело и с данными файла. Каждый файл на NTFS, в общем-то, имеет несколько абстрактное строение - у него нет как таковых данных, а есть потоки (streams). Один из потоков и носит привычный нам смысл - данные файла. Но большинство атрибутов файла - тоже потоки! Таким образом, получается, что базовая сущность у файла только одна - номер в MFT, а всё остальное опционально. Данная абстракция может использоваться для создания довольно удобных вещей - например, файлу можно "прилепить" еще один поток, записав в него любые данные - например, информацию об авторе и содержании файла, как это сделано в Windows 2000 (самая правая закладка в свойствах файла, просматриваемых из проводника). Интересно, что эти дополнительные потоки не видны стандартными средствами: наблюдаемый размер файла - это лишь размер основного потока, который содержит традиционные данные. Можно, к примеру, иметь файл нулевой длинны, при стирании которого освободится 1 Гбайт свободного места - просто потому, что какая-нибудь хитрая программа или технология прилепила в нему дополнительный поток (альтернативные данные) гигабайтового размера. Но на самом деле в текущий момент потоки практически не используются, так что опасаться подобных ситуаций не следует, хотя гипотетически они возможны. Просто имейте в виду, что файл на NTFS - это более глубокое и глобальное понятие, чем можно себе вообразить просто просматривая каталоги диска. Ну и напоследок: имя файла может содержать любые символы, включая полый набор национальных алфавитов, так как данные представлены в Unicode - 16-битном представлении, которое дает 65535 разных символов. Максимальная длина имени файла - 255 символов. Каталоги Каталог на NTFS представляет собой специфический файл, хранящий ссылки на другие файлы и каталоги, создавая иерархическое строение данных на диске. Файл каталога поделен на блоки, каждый из которых содержит имя файла, базовые атрибуты и ссылку на элемент MFT, который уже предоставляет полную информацию об элементе каталога. Внутренняя структура каталога представляет собой бинарное дерево. Вот что это означает: для поиска файла с данным именем в линейном каталоге, таком, например, как у FAT-а, операционной системе приходится просматривать все элементы каталога, пока она не найдет нужный. Бинарное же дерево располагает имена файлов таким образом, чтобы поиск файла осуществлялся более быстрым способом - с помощью получения двухзначных ответов на вопросы о положении файла. Вопрос, на который бинарное дерево способно дать ответ, таков: в какой группе, относительно данного элемента, находится искомое имя - выше или ниже? Мы начинаем с такого вопроса к среднему элементу, и каждый ответ сужает зону поиска в среднем в два раза. Файлы, скажем, просто отсортированы по алфавиту, и ответ на вопрос осуществляется очевидным способом - сравнением начальных букв. Область поиска, суженная в два раза, начинает исследоваться аналогичным образом, начиная опять же со среднего элемента.
Вывод - для поиска одного файла среди 1000, например, FAT придется осуществить в среднем 500 сравнений (наиболее вероятно, что файл будет найден на середине поиска), а системе на основе дерева - всего около 10-ти (2^10 = 1024). Экономия времени поиска налицо. Не стоит, однако думать, что в традиционных системах (FAT) всё так запущено: во-первых, поддержание списка файлов в виде бинарного дерева довольно трудоемко, а во-вторых - даже FAT в исполнении современной системы (Windows2000 или Windows98) использует сходную оптимизацию поиска. Это просто еще один факт в вашу копилку знаний. Хочется также развеять распространенное заблуждение (которое я сам разделял совсем еще недавно) о том, что добавлять файл в каталог в виде дерева труднее, чем в линейный каталог: это достаточно сравнимые по времени операции - дело в том, что для того, чтобы добавить файл в каталог, нужно сначала убедится, что файла с таким именем там еще нет :) - и вот тут-то в линейной системе у нас будут трудности с поиском файла, описанные выше, которые с лихвой компенсируют саму простоту добавления файла в каталог. Какую информацию можно получить, просто прочитав файл каталога? Ровно то, что выдает команда dir. Для выполнения простейшей навигации по диску не нужно лазить в MFT за каждым файлом, надо лишь читать самую общую информацию о файлах из файлов каталогов. Главный каталог диска - корневой - ничем не отличается об обычных каталогов, кроме специальной ссылки на него из начала метафайла MFT. Журналирование NTFS - отказоустойчивая система, которая вполне может привести себя в корректное состояние при практически любых реальных сбоях. Любая современная файловая система основана на таком понятии, как транзакция - действие, совершаемое целиком и корректно или не совершаемое вообще. У NTFS просто не бывает промежуточных (ошибочных или некорректных) состояний - квант изменения данных не может быть поделен на до и после сбоя, принося разрушения и путаницу - он либо совершен, либо отменен. Пример 1: осуществляется запись данных на диск. Вдруг выясняется, что в то место, куда мы только что решили записать очередную порцию данных, писать не удалось - физическое повреждение поверхности. Поведение NTFS в этом случае довольно логично: транзакция записи откатывается целиком - система осознает, что запись не произведена. Место помечается как сбойное, а данные записываются в другое место - начинается новая транзакция. Пример 2: более сложный случай - идет запись данных на диск. Вдруг, бах - отключается питание и система перезагружается. На какой фазе остановилась запись, где есть данные, а где чушь? На помощь приходит другой механизм системы - журнал транзакций. Дело в том, что система, осознав свое желание писать на диск, пометила в метафайле $LogFile это свое состояние. При перезагрузке это файл изучается на предмет наличия незавершенных транзакций, которые были прерваны аварией и результат которых непредсказуем - все эти транзакции отменяются: место, в которое осуществлялась запись, помечается снова как свободное, индексы и элементы MFT приводятся в с состояние, в котором они были до сбоя, и система в целом остается стабильна. Ну а если ошибка произошла при записи в журнал? Тоже ничего страшного: транзакция либо еще и не начиналась (идет только попытка записать намерения её произвести), либо уже закончилась - то есть идет попытка записать, что транзакция на самом деле уже выполнена. В последнем случае при следующей загрузке система сама вполне разберется, что на самом деле всё и так записано корректно, и не обратит внимания на "незаконченную" транзакцию. И все-таки помните, что журналирование - не абсолютная панацея, а лишь средство существенно сократить число ошибок и сбоев системы. Вряд ли рядовой пользователь NTFS хоть когда-нибудь заметит ошибку системы или вынужден будет запускать chkdsk - опыт показывает, что NTFS восстанавливается в полностью корректное состояние даже при сбоях в очень загруженные дисковой активностью моменты. Вы можете даже оптимизировать диск и в самый разгар этого процесса нажать reset - вероятность потерь данных даже в этом случае будет очень низка. Важно понимать, однако, что система восстановления NTFS гарантирует корректность файловой системы, а не ваших данных. Если вы производили запись на диск и получили аварию - ваши данные могут и не записаться. Чудес не бывает. Сжатие Файлы NTFS имеют один довольно полезный атрибут - "сжатый". Дело в том, что NTFS имеет встроенную поддержку сжатия дисков - то, для чего раньше приходилось использовать Stacker или DoubleSpace. Любой файл или каталог в индивидуальном порядке может хранится на диске в сжатом виде - этот процесс совершенно прозрачен для приложений. Сжатие файлов имеет очень высокую скорость и только одно большое отрицательное свойство - огромная виртуальная фрагментация сжатых файлов, которая, правда, никому особо не мешает. Сжатие осуществляется блоками по 16 кластеров и использует так называемые "виртуальные кластеры" - опять же предельно гибкое решение, позволяющее добиться интересных эффектов - например, половина файла может быть сжата, а половина - нет. Это достигается благодаря тому, что хранение информации о компрессированности определенных фрагментов очень похоже на обычную фрагментацию файлов: например, типичная запись физической раскладки для реального, несжатого, файла: Безопасность NTFS содержит множество средств разграничения прав объектов - есть мнение, что это самая совершенная файловая система из всех ныне существующих. В теории это, без сомнения, так, но в текущих реализациях, к сожалению, система прав достаточно далека от идеала и представляет собой хоть и жесткий, но не всегда логичный набор характеристик. Права, назначаемые любому объекту и однозначно соблюдаемые системой, эволюционируют - крупные изменения и дополнения прав осуществлялись уже несколько раз и к Windows 2000 все-таки они пришли к достаточно разумному набору. Права файловой системы NTFS неразрывно связаны с самой системой - то есть они, вообще говоря, необязательны к соблюдению другой системой, если ей дать физический доступ к диску. Для предотвращения физического доступа в Windows2000 (NT5) всё же ввели стандартную возможность - об этом см. ниже. Система прав в своем текущем состоянии достаточно сложна, и я сомневаюсь, что смогу сказать широкому читателю что-нибудь интересное и полезное ему в обычной жизни. Если вас интересует эта тема - вы найдете множество книг по сетевой архитектуре NT, в которых это описано более чем подробно. На этом описание строение файловой системы можно закончить, осталось описать лишь некоторое количество просто практичных или оригинальных вещей. Hard Links Эта штука была в NTFS с незапамятных времен, но использовалась очень редко - и тем не менее: Hard Link - это когда один и тот же файл имеет два имени (несколько указателей файла-каталога или разных каталогов указывают на одну и ту же MFT запись). Допустим, один и тот же файл имеет имена 1.txt и 2.txt: если пользователь сотрет файл 1, останется файл 2. Если сотрет 2 - останется файл 1, то есть оба имени, с момента создания, совершенно равноправны. Файл физически стирается лишь тогда, когда будет удалено его последнее имя. 
Не нашли, что искали? Воспользуйтесь поиском по сайту: ©2015 - 2026 stydopedia.ru Все материалы защищены законодательством РФ.
|