
|
|
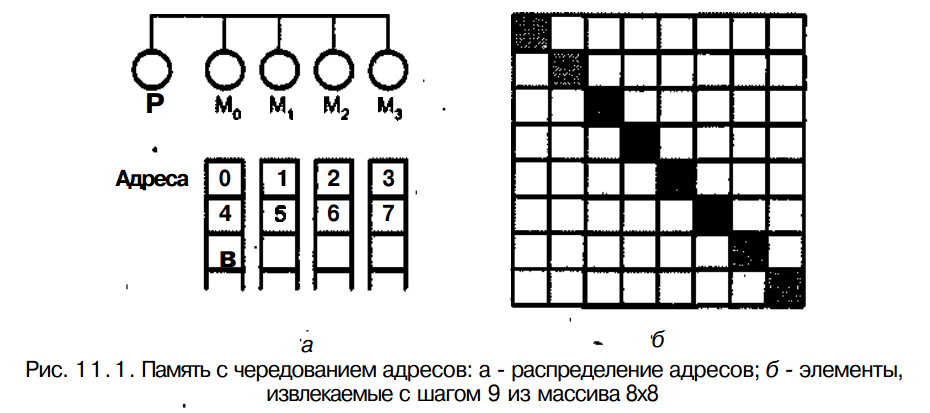
Память с чередованием адресовОрганизация памяти вычислительных систем В вычислительных системах, объединяющих множество параллельно работающих процессоров или машин, задача правильной организации памяти является одной из важнейших. Различие между быстродействием процессора и памяти всегда было камнем преткновения в однопроцессорных ВМ. Многопроцессорность ВС приводит еще к одной проблеме - проблеме одновременного доступа к памяти со сторо-ны нескольких процессоров. В зависимости от того, каким образом организована память многопроцессорных (многомашинных) систем, различают вычислительные системы с общей памятью (shared memory) и ВС с распределенной памятью (distributed memory). В системах с общей памятью (ее часто называют также совместно используемой или разделяемой памятью) память ВС рассматривается как общий ресурс, и каждый из процессоров имеет полный доступ ко всему адресному пространству. Системы с общей памятью называют сильно связанными (closely coupled systems). Подобное построение вычислительных систем имеет место как в классе SIMD, так и в массе MIMD. Иногда, чтобы подчеркнуть это обстоятельство, вводят специальные подклассы, используя для их обозначения аббревиатуры SM-SIMD (Shared Memory SIMD) и SM-MIMD (Shared Memory MIMD). В варианте с распределенной памятью каждому из процессоров придается собственная память. Процессоры объединяются в сеть и могут при необходимости обмениваться данными, хранящимися в их памяти, передавая друг другу так называемые сообщения. Такой вид ВС называют слабо связанными (loosely coupled systems). Слабо связанные системы также встречаются как в классе SIMD, так и в классе MIMD, и иной раз, чтобы подчеркнуть данную особенность, вводят подклассы DM-SIMD (Distributed Memory SIMD) и DM-MIMD (Distributed Memory MIMD). В некоторых случаях вычислительные системы с общей памятью называют мультипроцессорами, а системы с распределенной памятью — мулътикомпьютерами. Различие между общей и распределенной памятью - это разница в структуре виртуальной памяти, то есть в том, как память выгладит со стороны процессора Физически почти каждая система памяти разделена на автономные компоненты, доступ к которым может производиться независимо. Общую память от распределенной отличает то, каким образом подсистема памяти интерпретирует поступивший от процессора адрес ячейки. Для примера положим, что процессор выполняет команду Load RO, i, означающую "Загрузить регистр R0 с содержимым ячейки i ". В случае общей памяти i - это глобальный адрес, и для любого процессора указывает на одну и ту же ячейку. В распределенной системе памяти i - это локальный адрес. Если два процессора выполняют команду load RO, i, то каждый из них обращается к i-й ячейке в своей локальной памяти, то есть к разным ячейкам, и в регистры R0 могут быть загружены неодинаковые значения. Различие между двумя системами памяти должно учитываться программистом, поскольку оно определяет способ взаимодействия частей распараллеленной программы. В варианте с общей памятью достаточно создать в памяти структуру данных и передавать в параллельно используемые подпрограммы ссылки на эту структуру. В системе с распределенной памятью необходимо в каждой локальной памяти иметь копию совместно используемых данных. Эти копии создаются путем вкладывания разделяемых данных в сообщения, посылаемые другим процессорам. Память с чередованием адресов Физически память вычислительной системы состоит из нескольких модулей (банков), при этом существенным вопросом является то, как в этом случае распределено адресное пространство (набор всех адресов, которые может сформировать процессор). Один из способов распределения виртуальных адресов по модулям памяти состоит в разбиении адресного пространства на последовательные блоки. Если память состоит из п банков, то ячейка с адресом i при поблочном разбиении будет находиться в банке с номером i/п. В системе памяти с чередованием адресов (interleaved memory) последовательные адреса располагаются в различных банках: ячейка с адресом i находится в банке с номером i mod п. Пусть, например, память состоит из четырех банков, по 256 байт в каждом. В схеме, ориентированной на блочную адресацию, первому банку будут выделены виртуальные адреса 0-255, второму -256-511 и т. д. В схеме с чередованием адресов последовательные ячейки в первом банке будут иметь виртуальные адреса 0, 4, 8, ..„ во втором банке — 1, 5, 9 и т. д. (рис. 11.1, а). Распределение адресного пространства по модулям дает возможность одновременной обработки запросов на доступ к памяти, если соответствующие адреса относятся к разным банкам. Процессор может в одном из циклов затребовать доступ к ячейке i, а в следующем цикле - к ячейке j Если i и j находятся в разных банках, информация будет передана в последовательных циклах.. Здесь под циклом понимается цикл процессора, в то время как полный цикл памяти занимает несколько циклов процессора. Таким образом, в данном случае процессор не должен ждать, пока будет завершен полный цикл обращения к ячейке i. Рассмотренный прием позволяет повысить пропускную способность: если система памяти состоит из Решение о том, какой вариант распределения адресов выбрать (поблочный или с расслоением), зависит от ожидаемого порядка доступа к информации. Программы компилируются так, что последовательные команды располагаются в ячейках с последовательными адресами, поэтому высока вероятность, что после команды, извлеченной из ячейки с адресом i, будет выполняться команда из ячейки i + 1. Элементы векторов компилятор также помещает в последовательные ячейки, поэтому в операциях с векторами можно использовать преимущества метода чередования. По этой причине в векторных процессорах обычно применяется какой-либо вариант чередования адресов. В мультипроцессорах с совместно используемой памятью тем не менее используется поблочная адресация, поскольку схемы обращения к памяти в MIMD-системах могут сильно различаться. В таких системах целью является соединить процессор с блоком памяти и задействовать максимум находящейся в нем информации, прежде чем переключиться на другой блок памяти. Системы памяти зачастую обеспечивают дополнительную гибкость при извлечении элементов векторов. В некоторых системах возможна одновременная загрузка каждого n-го элемента вектора, например, при извлечении элементов вектора v1 хранящегося в последовательных ячейках памяти при и - 4, память возвратит vО, v4, v8. Интервал между элементами называют шагом по индексу или «страй-Ъомъ (stride). Одним из интересных применений этого свойства может служить доступ к матрицам. Если шаг по индексу на единицу больше числа строк в матрице, одиночный запрос на доступ к памяти возвратит все диагональные элементы матрицы (рис. 11.1, б). Ответственность за то, чтобы все извлекаемые элементы матрицы располагались в разных банках, ложится на программиста. 
Не нашли, что искали? Воспользуйтесь поиском по сайту: ©2015 - 2026 stydopedia.ru Все материалы защищены законодательством РФ.
|
 достаточного числа банков, имеется возможность обмена информацией между процессором и памятью со скоростью одно слово за цикл процессора, независимо от длительности цикла памяти.
достаточного числа банков, имеется возможность обмена информацией между процессором и памятью со скоростью одно слово за цикл процессора, независимо от длительности цикла памяти.