|
|
Кодирование текстовой информации12 Для кодирования символьной или текстовой информации применяются различные системы: при вводе информации с клавиатуры кодирование происходит при нажатии клавиши, на которой изображен требуемый символ, при этом в клавиатуре вырабатывается так называемый scan-код, представляющий собой двоичное число, равное порядковому номеру клавиши. 3.1 Кодировка ASCII Всего существует множество кодировочных таблиц. Рассмотрим сначала кодировочную таблицу ASCII (ASCII - American Standard Code for Information Interchange - Американский стандартный код для обмена информацией). Эта кодировка является наиболее известной. На практике обычно не бывает проблем с кодированием англоязычных текстов, поскольку первая половина кодировки стандартизована, но, к сожалению, для кодировки русских букв существует несколько кодировочных таблиц, что иногда создает проблемы при работе с текстами. Для кодировки одного символа из таблицы отводится 8 бит. При обработке текстовой информации один байт может содержать код некоторого символа - буквы, цифры, знака пунктуации, знака действия и т.д. Каждому символу соответствует свой код в виде целого числа. Один байт как набор восьми битов позволяет закодировать 256 символов, что вполне достаточно для работы сразу с двумя обычными языками, например английским и русским. При этом все коды собираются в специальные таблицы, называемые кодировочными. С их помощью производится преобразование кода символа в его видимое представление на экране монитора. В результате любой текст в памяти компьютера представляется как последовательность байтов с кодами символов. Таблица кодировки текстовой информации ASCII.
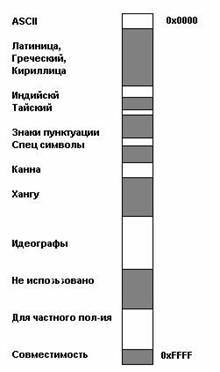
Первая половина таблицы ASCII стандартизована. Она содержит управляющие коды (от 0 до 31. Эти коды из таблицы изъяты, так как они не относятся к текстовым элементам. Данная кодировка решает пользовательские проблемы (см. выше), но создает новые, технические проблемы: как пересылать символы в формате Unicode, используя 8-битные байты? 8-битные единицы являются наименьшими передаваемыми единицами в большинстве компьютеров, а также являющимися минимальными единицами, используемыми при сетевых соединениях на основе протокола TCP/IP. Использование 1-го байта для представления 1-го символа стало эпизодом истории (факт появления такой кодировки обусловлен тем, что компьютеры зародились в Европе и США, где долгое время обходились 96 символами). Существует 4 основных способа кодировки байтами в формате Unicode: UTF-8: 128 символов кодируются одним байтом (формат ASCII), 1920 символов кодируются 2-мя байтами ((Roman, Greek, Cyrillic, Coptic, Armenian, Hebrew, Arabic символы), 63488 символов кодируются 3-мя байтами (Китайский, японский и др.) Оставшиеся 2 147 418 112 символы (еще не использованы) могут быть закодированы 4, 5 или 6-ю байтами. UCS-2: Каждый символ представлен 2-мя байтами. Данная кодировка включает лишь первые 65 535 символов из формата Unicode. UTF-16:Является расширением UCS-2, включает 1 114 112 символов формата Unicode. Первые 65 535 символов представлены 2-мя байтами, остальные - 4-мя байтами. USC-4: Каждый символ кодируется 4-мя байтами. Получается, что 8 бит используются для кодирования европейских языков, а для китайского, японского и корейского языков много больше. Это может повлиять на объем занимаемого дискового пространства и на скорость передачи по сети. Для основных кодировок картина следующая (K(%) - увеличение дискового пространства и снижение скорости передачи по сети): UTF-8: никаких изменений для американской ASCII, незначительное ухудшение (К = несколько %) для ISO-8859-1, К=50% для китайского, японского, корейского и К=100% для греческого и кириллицы. UCS-2 и UTF-16: никаких изменений для китайского, японского, корейского; К=100% для американской ASCII, ISO-8859-1, греческого и кириллицы. UCS-4: К=100% для китайского, японского, корейского; К=300% для американской ASCII, ISO-8859-1, греческого и кириллицы. В итоге получается, что UTF-8 кодировка занимает меньше дискового пространства и позволяется передавать данные по сети с большей скоростью [10]. Стандарт Unicode был разработан с целью создания единой кодировки символов всех современных и многих древних письменных языков. Каждый символ в этом стандарте кодируется 16 битами, что позволяет ему охватить несравненно большее количество символов, чем принятые ранее 7- и 8-битовые кодировки. Еще одним важным отличием Unicode от других систем кодировки является то, что он не только приписывает каждому символу уникальный код, но и определяет различные характеристики этого символа, например: тип символа (прописная буква, строчная буква, цифра, знак препинания и т.д.); атрибуты символа (отображение слева направо или справа налево, пробел, разрыв строки и т.д.); соответствующая прописная или строчная буква (для строчных и прописных букв соответственно); соответствующее числовое значение (для цифровых символов). Весь диапазон кодов от 0 до FFFF разбит на несколько стандартных подмножеств, каждое из которых соответствует либо алфавиту какого-то языка, либо группе специальных символов, сходных по своим функциям. На приведенной ниже схеме содержится общий перечень подмножеств Unicode 3.0. Формат UTF-8: Стандарт Unicode является основой для хранения и текста во многих современных компьютерных системах. Однако, он не совместим с большинством Интернет-протоколов, поскольку его коды могут содержать любые байтовые значения, а протоколы обычно используют байты 00 - 1F и FE - FF в качестве служебных. Для достижения совместимости были разработаны несколько форматов преобразования Unicode (UTFs, Unicode Transformation Formats), из которых на сегодня наиболее распространенным является UTF-8. Этот формат определяет следующие правила преобразования каждого кода Unicode в набор байтов (от одного до трех), пригодных для транспортировки Интернет-протоколами.
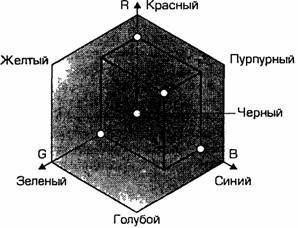
0000 - 007F 00000000 0zzzzzzz 0zzzzzzzz 0080 - 07FF 00000yyy yyzzzzzz 110yyyyy 10zzzzzz 0800 – FFFF xxxxyyyy yyzzzzzz 1110xxxx 10yyyyyy 10zzzzzz Здесь x,y,z обозначают биты исходного кода, которые должны извлекаться, начиная с младшего, и заноситься в байты результата справа налево, пока не будут заполнены все указанные позиции. Файл. Форматы файлов Основное назначение файлов – хранить информацию. Они предназначены также для передачи данных от программы к программе и от системы к системе. Другими словами, файл – это хранилище стабильных и мобильных данных. Но, файл – это нечто большее, чем просто хранилище данных. Обычно файл имеет имя, атрибуты, время модификации и время создания. Файловая структура представляет собой систему хранения файлов на запоминающем устройстве, например, на диске. Файлы организованы в каталоги (иногда называемые директориями или папками). Любой каталог может содержать произвольное число подкаталогов, в каждом из которых могут храниться файлы и другие каталоги. Способ, которым данные организованы в байты, называется форматом файла. Для того чтобы прочесть файл, например, электронной таблицы, нужно знать, каким образом байты представляют числа (формулы, текст) в каждой ячейке; чтобы прочесть файл текстового редактора, надо знать, какие байты представляют символы, а какие шрифты или поля, а также другую информацию. Такие языки, как китайский, содержат значительно больше 256 символов, поэтому для кодирования каждого из них используют несколько байтов. Двоичные файлы, в отличие от текстовых, не так просто просмотреть, и в них, обычно, нет знакомых слов – лишь множество непонятных символов. Эти файлы не предназначены непосредственно для чтения человеком. Примерами двоичных файлов являются исполняемые программы и файлы с графическими изображениями. Кодирование графической информации. Растровые изображения представляют собой однослойную сетку точек, называемых пикселами (pixel, от англ. picture element). Код пиксела содержит информации о его цвете. Для черно-белого изображения (без полутонов) пиксел может принимать только два значения: белый и черный (светится – не светится), а для его кодирования достаточно одного бита памяти: 1 – белый, 0 – черный. Пиксел на цветном дисплее может иметь различную окраску, поэтому одного бита на пиксел недостаточно. Для кодирования 4-цветного изображения требуются два бита на пиксел, поскольку два бита могут принимать 4 различных состояния. Может использоваться, например, такой вариант кодировки цветов: 00 – черный, 10 – зеленый, 01 – красный, 11 – коричневый. На RGB-мониторах все разнообразие цветов получается сочетанием базовых цветов – красного (Red), зеленого (Green), синего (Blue), из которых можно получить 8 основных комбинаций:
R R
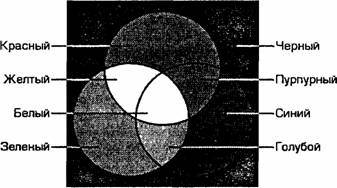
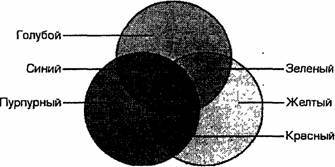
Разумеется, если иметь возможность управлять интенсивностью (яркостью) свечения базовых цветов, то количество различных вариантов их сочетаний, порождающих разнообразные оттенки, увеличивается. Количество различных цветов – К и количество битов для их кодировки – N связаны между собой простой формулой: 2^N = К. В противоположность растровой графике векторное изображение многослойно. Каждый элемент векторного изображения – линия, прямоугольник, окружность или фрагмент текста – располагается в своем собственном слое, пикселы которого устанавливаются независимо от других слоев. Каждый элемент векторного изображения является объектом, который описывается с помощью специального языка (математических уравнения линий, дуг, окружностей и т.д.) Сложные объекты (ломаные линии, различные геометрические фигуры) представляются в виде совокупности элементарных графических объектов. Объекты векторного изображения, в отличие от растровой графики, могут изменять свои размеры без потери качества (при увеличении растрового изображения увеличивается зернистость). Каждому пикселю присвоен код, хранящий информацию о цвете пикселя. Для получения черно-белого изображения (без полутонов) пиксель может принимать только два состояния: “белый” или “черный”. Тогда для его кодирования достаточно 1 бита: 1 – белый, 0 – черный. Пиксель на цветном дисплее может иметь различную окраску. Поэтому 1 бита на пиксель – недостаточно. Для кодирования 4-цветного изображения требуется два бита на пиксель, поскольку два бита могут принимать 4 различных состояния. Может использоваться, например, такой вариант кодировки цветов: 00 – черный 10 – зеленый 01 – красный 11 – коричневый. Цветное изображение на экране монитора формируется за счет смешивания трех базовых цветов: красного, зеленого, синего. Из трех цветов можно получить восемь комбинаций: Следовательно, для кодирования 8-цветного изображения требуется три бита памяти на один пиксель. Для получения богатой палитры цветов базовым цветам могут быть заданы различные интенсивности, тогда количество различных вариантов их сочетаний, дающих разные краски и оттенки, увеличивается. Шестнадцатицветная палитра получается при использовании 4-разрядной кодировки пикселя: к трем битам базовых цветов добавляется один бит интенсивности. Этот бит управляет яркостью всех трех цветов одновременно. Также графическая информация может быть представлена в виде векторного изображения. Цветовая модель RGB. Наиболее проста для понимания и очевидна цветовая модель RGB. В этой цветовой модели работают мониторы и бытовые телевизоры. Любой цвет считается состоящим из трех основных компонентов: красного (Red), зеленого (Green) и синего (Blue). Эти цвета цветовой модели называются основными. Считается также, что при наложении одного компонента на другой яркость суммарного цвета увеличивается. Совмещение трех компонентов дает нейтральный цвет (серый), который при большой яркости стремится к белому цвету. Так формируется цветовая модель RGB. Цветовая модель RGB соответствует тому, что мы наблюдаем на экране монитора, поэтому данную цветовую модель применяют всегда, когда готовится изображение, предназначенное для воспроизведения на экране. Если изображение проходит компьютерную обработку в графическом редакторе, то его тоже следует представить в цветовой модели RGB. В графических редакторах имеются средства для преобразования изображений из одной цветовой модели в другую цветовую модель. Метод получения нового оттенка суммированием яркостей составляющих компонентов называют аддитивным методом. Он применяется всюду, где цветное изображение рассматривается в проходящем свете («на просвет»): в мониторах, слайд-проекторах и т. п. Нетрудно догадаться, что чем меньше яркость, тем темнее оттенок. Поэтому в аддитивной модели центральная точка, имеющая нулевые значения компонентов (0,0,0), имеет черный цвет (отсутствие свечения экрана монитора). Белому цвету соответствуют максимальные значения составляющих (255, 255, 255). Модель RGB является аддитивной, а ее компоненты: красный, зеленый и синий — называют основными цветами. Цветовая модель CMYk. Цветовая модель CMYK скорее всего вам не понадобится, если вы будете печатать на принтере. Желательно знать, что такое цветовая модель CMYK. Цветовая модель CMYK используется для подготовки не экранных, а печатных изображений. Они отличаются тем, что их видят не в проходящем, а в отраженном свете. Чем больше краски положено на бумагу, тем больше света она поглощает и меньше отражает. Совмещение трех основных красок в цветовой модели CMYk поглощает почти весь падающий свет, и со стороны изображение выглядит почти черным. В отличие от модели RGB в цветовой модели CMYK увеличение количества краски приводит не к увеличению визуальной яркости, а наоборот к ее уменьшению. Поэтому для подготовки печатных изображений используется не аддитивная (суммирующая) модель, а субтрактивная (вычитающая) модель. Цветовыми компонентами этой модели являются не основные цвета, а те, которые получаются в результате вычитания основных цветов из белого: ГОЛУБОЙ (Суап)=БЕЛЫЙ-КРАСНЫЙ=ЗЕЛЕНЫЙ+СИНИЙ; ПУРПУРНЫЙ (Magenta)=БЕЛЫЙ-ЗЕЛЕНЫЙ=КРАСНЫЙ+СИНИЙ; ЖЕЛТЫЙ (Yellow)=БЕЛЫЙ-СИНИЙ=КРАСНЫЙ+ЗЕЛЕНЫЙ Эти три цвета называются дополнительными, потому что они дополняют основные цвета до белого. Существенную трудность в полиграфии представляет черный цвет. Теоретически его можно получить совмещением трех основных или дополнительных красок, но на практике результат оказывается негодным. Поэтому в цветовую модель CMYk добавлен четвертый компонент — черный. Ему эта система обязана буквой К в названии (black), Цветоделение в цветовой модели CMYk. В типографиях цветные изображения печатают в несколько приемов. Накладывая на бумагу по очереди голубой, пурпурный, желтый и черный отпечатки, получают полноцветную иллюстрацию. Поэтому готовое изображение, полученое на компьютере, перед печатью разделяют на четыре составляющих одноцветных изображения. Этот процесс называется цветоделением. Современные графические редакторы имеют средства для выполнения этой операции. Сложение цветов в цветовой модели CMYK каждый может проверить, взяв в руки голубой, розовый и желтый карандаши или фломастеры. Смесь голубого и желтого на бумаге дает зеленый цвет, розового с желтым — красный и т. д. При смешении всех трех цветов получается неопределенный темный цвет. Поэтому в этой модели черный цвет и понадобился дополнительно.
Цветовая модель HSB. По сути, цветовая модель HSB использует тот же набор основных цветов. Некоторые графические редакторы позволяют работать с цветовой моделью HSB. Если цветовая модель RGB наиболее удобна для компьютера, а цветовая модель CMYK — для типографий, то цветовая модель HSB наиболее удобна для человека. Цветовая модель HSB проста и интуитивно понятна. В цветовой модели HSB тоже три компонента: оттенок цвета (Hue), насыщенность цвета (Saturation) и яркость цвета (Brightness). Регулируя эти три компонента, можно получить столь же много произвольных цветов, как и при работе с другими цветовыми моделями. Цветовая модель HSB удобна для применения в тех графических редакторах, которые ориентированы не на обработку готовых изображений, а на их создание своими руками. Существуют такие программы, которые позволяют имитировать различные инструменты художника (кисти, перья, фломастеры, карандаши), материалы красок (акварель, гуашь, масло, тушь, уголь, пастель) и материалы полотна (холст, картон, рисовая бумага и пр.). Создавая собственное художественное произведение, удобно работать в цветовой модели HSB, а по окончании работы его можно преобразовать в цветовую модель RGB или CMYK, в зависимости от того, будет ли оно использоваться как экранная или печатная иллюстрация. Все алгоритмы сжатия оперируют входным потоком информации, минимальной единицей которой является бит, а максимальной - несколько бит, байт или несколько байт. Целью процесса сжатия, как правило, есть получение более компактного выходного потока информационных единиц из некоторого изначально некомпактного входного потока при помощи некоторого их преобразования.
Основными техническими характеристиками процессов сжатия и результатов их работы являются:
Все способы сжатия можно разделить на две категории: обратимое и необратимое сжатие. Под необратимым сжатием подразумевают такое преобразование входного потока данных, при котором выходной поток, основанный на определенном формате информации, представляет, с некоторой точки зрения, достаточно похожий по внешним характеристикам на входной поток объект, однако отличается от него объемом. Степень сходства входного и выходного потоков определяется степенью соответствия некоторых свойств объекта (т.е. сжатой и несжатой информации в соответствии с некоторым определенным форматом данных), представляемого данным потоком информации. Такие подходы и алгоритмы используются для сжатия, например данных растровых графических файлов с низкой степенью повторяемости байтов в потоке. При таком подходе используется свойство структуры формата графического файла и возможность представить графическую картинку приблизительно схожую по качеству отображения (для восприятия человеческим глазом) несколькими (а точнее n) способами. Поэтому, кроме степени или величины сжатия, в таких алгоритмах возникает понятие качества, т.к. исходное изображение в процессе сжатия изменяется, то под качеством можно понимать степень соответствия исходного и результирующего изображения, оцениваемая субъективно, исходя из формата информации. Для графических файлов такое соответствие определяется визуально, хотя имеются и соответствующие интеллектуальные алгоритмы и программы. Необратимое сжатие невозможно применять в областях, в которых необходимо иметь точное соответствие информационной структуры входного и выходного потоков. Данный подход реализован в популярных форматах представления видео и фото информации, известных как JPEG и JFIF алгоритмы и JPG и JIF форматы файлов. Обратимое сжатие всегда приводит к снижению объема выходного потока информации без изменения его информативности, т.е. - без потери информационной структуры. 
12 Не нашли, что искали? Воспользуйтесь поиском по сайту: ©2015 - 2026 stydopedia.ru Все материалы защищены законодательством РФ.
|