|
|
Тема «Структурированные типы данных»
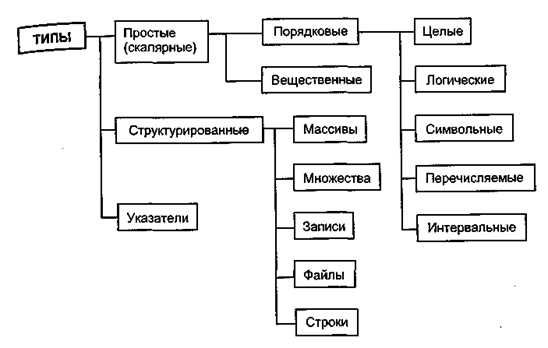
В начале изучения темы учащиеся должны осознать факт, что при обработке больших объемов данных без их организации (структурирования) не обойтись. На примерах использования таблиц покажите, сколь удобно иметь величину с одним именем и многими значениями (основной признак структурирования). Далее, покажите, что таблицами с однородными данными часто обойтись невозможно, поскольку приходится работать с таблицами, в колонках которых разнородные данные (различные кадровые анкеты). Наконец, не всегда число элементов в структуре можно заранее предвидеть; более того, оно может меняться «на ходу». Примеры: численность студенческой группы в процессе обучения, любая очередь (в магазине) и т.д. Соответственно, чем больше вариантов организации данных предлагает язык, тем он совершеннее. В этом смысле Паскаль устроен весьма удачно. Целесообразно предварить изучение отдельных структур данных их совокупным описанием. Дело в том, что о массивах учащиеся скорее всего имеют представление из базового курса и простое повторение может быть неинтересным. Рассмотрим схему типов данных Турбо Паскаля, позаимствованную из одного из приведенных в списке литературы руководств (рис. 15.5). Эта схема может служить определяющей при формировании порядка прохождения темы. На схеме не отражено, что в Турбо Паскале «вещественный» и «целый» — это группы типов; разговор о них должен состояться отдельно. Также надо заметить, что такие распространенные в приложениях динамические структуры данных, как очередь и стек, не являются стандартными типами Паскаля, но могут быть реализованы с помощью указателей.
Рис. 15.5. Типы данных Турбо Паскаля Массивы
Изучение структурированных типов начните с наиболее традиционного — массива. Подчеркните его групповые свойства: упорядоченная однородная статическая структура прямого доступа; приведите обоснование этих свойств. Способ, который принят для выделения элементов массива, — индексация — заслуживает отдельного разговора. Индексация не является единственно возможным способом выделения элементов структурированной величины и неразрывно связана с указанными свойствами. Неочевидно для учащихся, что границы изменения индексов назначаются произвольно, что тип индексов — интервальный — не обязательно базируется на типе integer (хотя чаще всего это так). Наконец, полезно соотнести представление о линейном (одномерном) массиве с цепочкой ячеек памяти ЭВМ, в которых хранятся элементы массива. Трактовка многомерного массива как одномерного массива, элементами которого являются массивы, верна и полезна для понимания возможности своего рода суперпозиции структур данных. Впоследствии этот взгляд обогатится рассмотрением массива записей и т.п. Однако при описании двумерных массивов (а именно ими практически данный курс в этой части ограничится) следует остановиться на более простом способе. Например:
Var A: array [1980..2000,1.. 15] of real
вместо альтернативного, явно отражающего фразу «массив массивов»:
Var A: array [1980 .. 2000] of array [1 .. 15] of real
Далее, на первом этапе изучения языка вносит путаницу наличие еще одной альтернативы — описание массива, сочетая type и var. На том же примере это выглядит так: ТуреВ = array [1980 .. 2000,1 .. 15] of real Var А:В
Подобная многовариантность украшает язык, но методически на первых порах неприемлема. Особо следует остановиться на том, что в Паскале массив не может быть динамической структурой. Учащиеся часто встают в тупик при необходимости, скажем, удалить элемент из массива. То, что между понятиями «удалить» и «вставить нуль» большая разница, понять легко. Удаление элемента со сдвигом остальных влево — операция технически несложная, но тогда получается «дырка» на правом конце массива. Убрать ее «на ходу» невозможно по самой природе массива, и если это действительно необходимо, то надо пользоваться иной структурой. Навыки использования массивов закрепляются с помощью решения типовых задач. К ним относятся: организация поэлементного ввода и вывод линейного массива (простой цикл), подсчет числа положительных элементов линейного числового массива, нахождение наибольшего элемента линейного числового массива (цикл с вложенной развилкой) и т.д. Затем переходят к задачам посложнее, требующим организации структур типа «цикл в цикле», и более сложным: упорядочить линейный числовой массив по возрастанию или по убыванию, найти наибольший элемент в двумерном массиве и т.д. Не следует ограничиваться задачами, в которых массивы имеют числовую природу. Примером задачи на использование символьного массива может служить следующая: на схеме кинозала звездочками помечены места, на которые билеты на сеанс показа проданы, черточками — не проданы. Подсчитать число проданных билетов. Примером более сложной задачи, решать которую целесообразно в классе с помощью учителя, служит известная задача о нахождении простых чисел при заданной верхней границе поиска — алгоритм Эрастофена. Ее можно решить несколькими способами. Весьма изящное решение связано с организацией булевского массива, который изначально заполнен элементами true, а по ходу чисел, не являющихся простыми, элементы с соответствующими номерами заменяются на false. Это решение можно найти в ряде пособий. Строки
Очень полезный тип данных, которого не было в базовой версии Паскаля. Вначале напомните учащимся, что в приложениях современной информатики обработка текстов является самым распространенным видом деятельности. Если вся задача состоит из обработки текста, то для этого существуют мощные специализированные программные средства — текстовые процессоры. Однако встречаются ситуации, когда обработка текста — часть задачи, решаемой алгоритмически, путем традиционного программирования. В этом случае нужны специальные структуры данных и средства их обработки. Покажите учащимся способ задания типа string. Нетривиально то, что хотя при задании строки ее максимальная длина часто указывается, величина является квазидинамической, т.е. ее реальный размер определяется текущим значением (хотя память все же резервируется по максимуму). Покажите автоматическую нумерацию элементов строки; подчеркните, что в нулевом элементе всегда находится число — автоматически определяемая длина строки. Введите немногие операции, возможные над строками, и особенно детально опишите нетривиальные операции сравнения строк (больше, меньше и т.д.). Важное преимущество строк над другими структурированными данными — возможность ввода-вывода полностью с помощью процедур writeln, readln. В принципе обсуждение этой возможности можно увязать с текстовыми файлами, но это загромождает основной материал. Введите функции Турбо Паскаля, ориентированные на работу со строками (length, concat, copy, delete, insert, pos), и полезные процедуры преобразования типов (str, val) и можно переходить к решению задач для закрепления навыков работы со строками. Типичные задачи, с которых целесообразно начать эту деятельность, таковы. 1. Определить, сколько раз в данном тексте встречается заданный символ. 2. Заменить в некотором тексте один фрагмент на другой ('Саша' на Маша'). Эту задачу можно решить, как минимум, двумя способами: а) с использованием функции сору и операции слияния строк; б) с использованием функций copy, delete и insert. 3. Определить, есть ли в некотором тексте одновременно два заданных слова. Множества
Этот тип данных иллюстрирует возможность существования неупорядоченных структур, достаточно редких для практики программирования. В познавательном плане ознакомление с этим типом данных весьма полезно. Итак, перед нами неупорядоченная однородная динамическая структура прямого доступа. При ее изучении и решении задач эти свойства будем подчеркивать. Начать изучение темы целесообразно с введения в математическую теорию множеств (если учащиеся с ней не знакомы). Понятия множество, подмножество, элемент, включение и др. не столь очевидны, как кажется. Затем введите и начните отрабатывать операции над множествами — объединение, пересечение, разность. Все эти понятия и операции реализованы в Паскале (разумеется, лишь над конечными множествами). После этого вводите способ описания множественного типа. Базировать его в первых примерах удобно на самостоятельно построенном перечислимом типе (фрукты, животные и т.п.). Тут же подчеркните, что, построив множество, мы потеряли возможность указать порядок следования элементов, так как его нет в принципе. Над элементами величин перечислимого типа можно произвести операции pred, succ, ord, а над множеством, построенном на базе этих величин — нет. Это не сразу осознается. Зато появляются принципиально новые операции, для отработки которых надо привести ряд примеров и решить несколько задач. Задания, в которых множествами пользоваться удобно, например, таковы. 1. Дана символьная строка. Подсчитать в ней все знаки препинания (. — , ; : ! ?). Образовав из указанного набора знаков множество, можно элементарно решить эту задачу, определяя в цикле, принадлежит ли текущий элемент строки этому множеству. 2. Выбрать все простые числа в диапазоне от 2 до N (соответствующий алгоритм «Решето Эрастофена» приводится в нескольких пособиях по Паскалю в разделе «Множества»). Все же задачи с использованием множеств лежат несколько в стороне от основных направлений программирования. Широкому практическому использованию множеств в программировании на Паскале препятствуют и ограничения языка (малый максимально возможный объем множеств, невозможность прямого ввода-вывода элементов). Записи
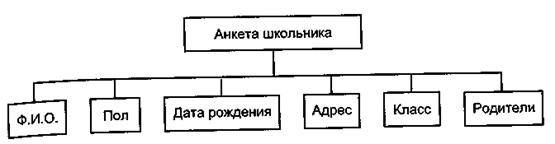
Вступлением в эту тему могут послужить примеры на обработку упорядоченных неоднородных структурированных величин. Еще раз напомните, что массив — структура однородная, что все элементы массива — величины одного типа, и тем самым обычную строчку анкетных сведений, в которой есть и числовые, и текстовые данные, записать в виде массива невозможно. Далее введите форму описания записи в языке Паскаль и соответствующую терминологию. Полезно иллюстрировать этот рассказ рисунками, не связанными нотациями Паскаля. Например, структура анкеты школьника, изображенная в виде двухуровневого дерева (рис. 15.6).
Рис. 15.6. Пример структуры типа «запись»
Обратите внимание учащихся на то, что поля записи могут иметь любой тип, в том числе сами могут быть записями. Последнее позволяет строить многоуровневое дерево-анкету. Например, на рис. 15.6 поле «Ф.И.О.» можно сделать записью, состоящей из трех полей: «фамилия», «имя», «отчество». Необычной конструкцией, связанной с записями, является составное имя поля. Приведите примеры составных имен, объясните, что в пределах действия описания записи ими можно пользоваться как обычными переменными. Обычно в программах обработки данных записи группируют в массивы или файлы. Если данная тема предшествует освоению работы с файлами, то ограничьтесь решением задач на массивы записей. Примеры таких задач: 1. Сформировать массив записей об учащихся своего класса. 2. В сформированном предварительно массиве записей отыскать всех юношей; вывести на экран записи о них. Обратите внимание учащихся, что любая обработка записей, в том числе ввод и вывод, производится поэлементно. По ходу разработки указанных программ достаточно легко вводится оператор присоединения with. Его назначение предельно просто — в пределах некоторого оператора (чаще всего цикла), один раз указав имя переменной типа «запись», работать с именами полей, как с обычными переменными, т.е. не писать громоздких составных имен. Обработка массивов записей может выглядеть не очень логично, в связи с чем возникает законный вопрос: неужели всякий раз этот массив надо формировать вводом данных с клавиатуры? В этом отношении гораздо логичнее использовать файлы записей, а к записям следует вернуться после изучения темы «файлы» (или изучать файлы до записей). Файлы
Перед нами — одна из центральных структур данных для всех языков программирования высокого уровня. Некоторые методические трудности при изучении файлов в Паскале возникают из-за многозначности самого термина «файл» в информатике. Между хорошо знакомым учащимся значением слова «файл» в его пользовательском смысле (как поименованной порции информации на внешнем носителе) и одноименной структурой данных Паскаля имеется существенное различие. Собственно говоря, переменные файлового типа в Паскале вовсе не имеют отношения к вопросу о носителе информации. Если не предпринять специальных (необязательных) усилий, то файловая переменная будет храниться в ОЗУ и при выходе из программы ее значение (как и всех остальных переменных) будет безвозвратно утеряно. Это не сразу осознается учащимися. Введите описание переменных файлового типа. Подчеркните, что элементами файла могут быть величины любого, в том числе и структурированного типа (кроме файлового). Возможен файл массивов, файл записей и т.д. Подчеркните, что перед нами динамическая структура, текущий размер которой может меняться. Методически удобна схема файла в виде последовательной цепочки элементов, пронумерованной от нуля и заканчивающейся специальным кодом — маркером конца. Стрелочка на рисунке отмечает позицию указателя (рис. 15.7).
Рис. 15.7. Иллюстрация файла
Введите операции «запись в файл» (write) и «чтение из файла» (read). При этом пользуйтесь средствами Турбо Паскаля, которые существенно удобнее операций put и get старых версий. Подчеркните, что запись происходит в текущее окно файла, на которое нацелен указатель, изображенный на рисунке стрелочкой. При записи указатель всегда нацелен на маркер конца (последний после записи передвигается во вновь открываемое окно). Подчеркните важную роль процедуры rewrite — открытие файла для записи, — устанавливающей указатель на начало файла и стирающей его содержимое (если таковое было). Аналогично обсуждают роль процедуры reset — открытие файла для чтения. В отличие от предыдущего, она не стирает файл, а указатель устанавливает на его начало. В Турбо Паскале нет барьера между файлами последовательного и прямого доступа; любую из приведенных выше процедур можно использовать для организации каждого из способов доступа. Обсудив идею того и другого и подчеркнув методические преимущества прямого доступа, вводят средства его организации. К ним относятся логическая функция eof и числовые функции filesize и filepos (но только отчасти, так как со всеми ими приходится работать и при прямом доступе), процедуры seek и truncate. Для демонстрации различий между последовательным и прямым доступом удобны следующие простейшие задачи: 1. Найти значение 10-го элемента некоторого уже существующего файла. 2. Вывести на экран последний элемент файла. 3. Вывести на экран элементы файла в обратном порядке. Каждую из подобных задач решают дважды: не используя и используя средства прямого доступа. Отработав операции с внутренними файлами, займитесь их привязкой к внешним. Необходимость этой операции очевидна — без нее созданный в программе файл исчезнет при выходе из нее. Объясните процедуру назначения assign и проиллюстрируйте ее работу на простейших примерах типа: написать две независимые программы, одна из которых создает некий файл (например, квадраты последовательно расположенных целых чисел от 1 до 100), а вторая производит простейшую обработку этого файла (например, находит сумму входящих в него элементов). Главная идея: первая программа отработала и закрылась, а ее результаты доступны другой программе. Наконец, не забудьте о процедуре close. Закрывать открытые в программе файлы следует непременно, даже если в простейших задачах кажется, что можно обойтись и без этого. Как показывает опыт, файловые переменные текстового типа (текстовые файлы) можно опустить без особого ущерба при изучении Паскаля (на том уровне, который целесообразен в школьном курсе). 
Не нашли, что искали? Воспользуйтесь поиском по сайту: ©2015 - 2024 stydopedia.ru Все материалы защищены законодательством РФ.
|