|
|
Принятие решений с возможностью экспериментирования
Пусть имеется 1000 урн, на каждую из которых наклеен один из ярлыков θ1 или θ2. В каждую урну положены красные и черные шары. В урне типа θ1 - 4 красных и 6 черных шаров. В урне типа θ2 - 9 красных и 1 черный шар. Всего имеется 800 урн типа θ1 и 200 урн типа θ2.
Экспериментатор выбирает одну из урн случайным образом и сняв наклейку ставит перед Вами. Вам предлагается угадать тип урны. Если Вы угадываете, то выигрываете некоторое количество денег, а в противном случае - проигрываете. Итак, у Вас есть выбор из трех возможных действий: - сказать, что урна типа θ1 (действие а1); - сказать, что урна типа θ2 (действие а2); - отказаться играть (действие а3).
образом вынуть один шар из урны, стоящей перед Вами (эксперимент е1); - за плату в $12 Вы можете вынуть 2 шара из этой урны (эксперимент е2); - за плату $9 Вы можете вынуть один шар и, после того как посмотрите на него, решить, хотите ли Вы вынуть еще шар за дополнительную плату $4,5. Вы можете также без всякой дополнительной платы решить, вернете ли Вы первый вынутый шар в урну перед тем, как будете вынимать второй, или нет (эксперимент еs). Рассмотрим решение этой задачи. Назовем ожидаемой денежной оценкой (ОДО) игры с различными исходами величину, которая получается умножением полезности каждого возможного исхода (в $) на его вероятность и суммированием этих произведений по всем возможным исходам.
Например, решившись в своей задаче на а1 без всякого экспериментирования Вы получаете +$40 если θ1 истинно (вероятность этого 0,8) или -$20 если θ2 истинно (вероятность этого 0,2), поэтому цена такой игры есть 0,8⋅⋅40 - 0,2⋅20 = 28. Если Вы не экспериментируете, то наилучшим выбором будет а1, ОДО которого равно $28 (для а2 оно равно -$16).
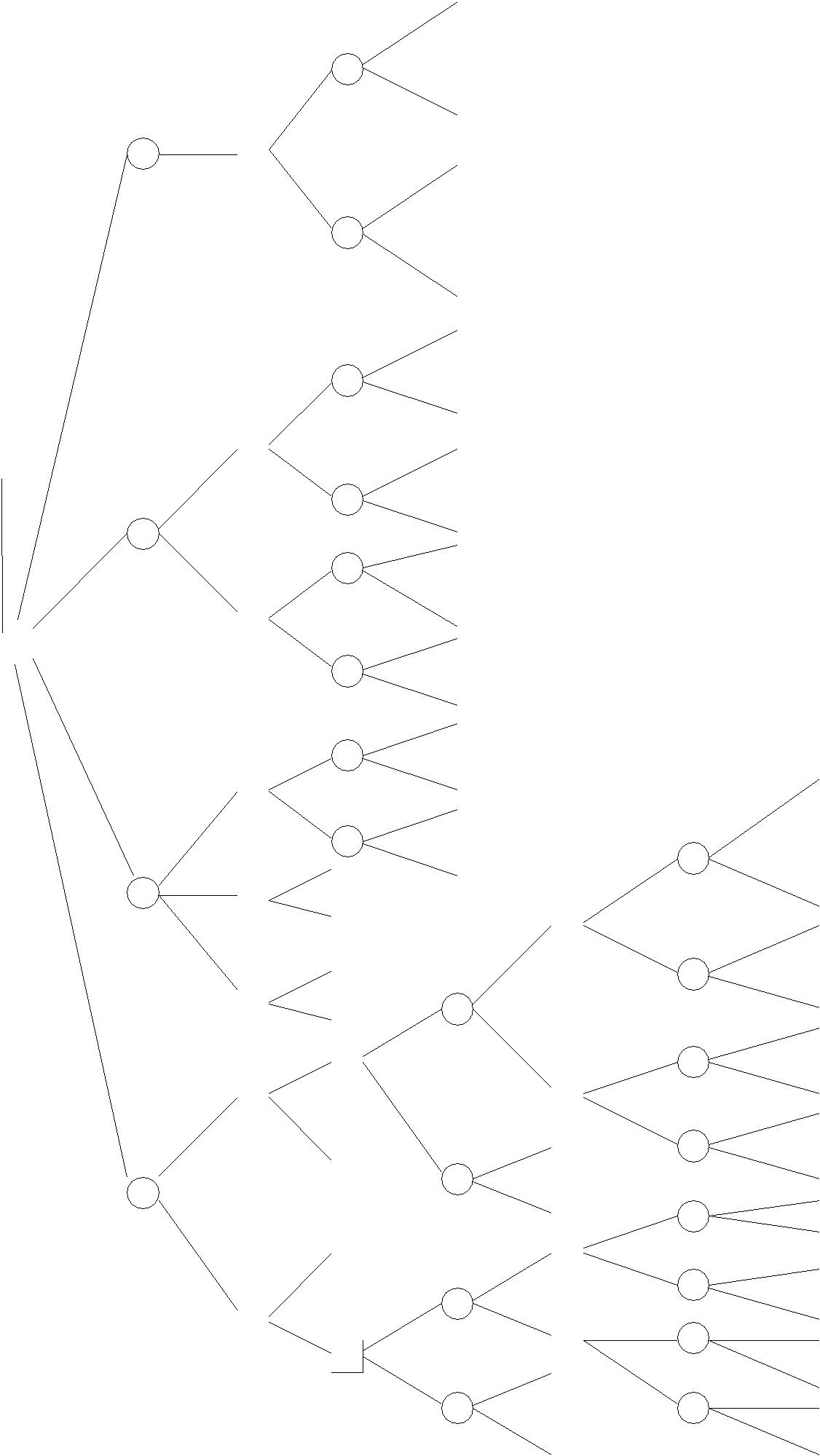
Рассмотрим теперь построение, так называемого, дерева решений.
На этом рисунке на некоторых разветвлениях (вершины- решения ) Вы решаете, что выбрать, а на других (вершины- случая) - правит случай. Взносы, которые Вы должны делать, нанесены на схему, а в конечных пунктах обозначены штрафы или премии, ожидающие Вас.
В каждой развилке, где правит случай, существенно знать вероятности, с которыми он выбирает те или иные альтернативы. Как они вычисляются? Для вершин (е0,а1) и (е0, а2) эти вероятности вычисляются непосредственно по исходным данным, как мы это уже сделали (е0- это отсутствие эксперимента).
Предположим, что Вы выбрали е1 и далее получили R (красный шар) или B (черный шар). Каковы вероятности в вершинах (е1,R,а1), (е1,B,а1) и др.? Для этого нам необходимо иметь следующие величины: условную вероятность θ1, если е1 привело к извлечению красного шара, т.е. p(θ1|R),
аналогично p(θ2|R), p(θ1|B), p(θ2|B), p(R|e1), p(B|e1). Но что мы знаем? 1). Вероятность появления θ1 до извлечения шара p(θ1)=0,8. 2). Вероятность появления θ2 , p(θ2)=0,2.
3). Условную вероятность того, что е1 приведет к извлечению красного шара, если θ1 истинно: p(R|θ1)=4/10=0,4. 4). Аналогично p(B|θ1)=0,6. 5). Аналогично p(R|θ2)=9/10=0,9. 6). Аналогично p(B|θ2)=0,1.
Чтобы из этих вероятностей получить те, которые нас интересуют, используем формулу Байеса:
p(E|S)=p(S|E)p(E)/( Σ p(S|A)p(A)). A
Теперь мы получаем:
p(θ1|R)=p(R|θ1)p(θ1)/(p(R|θ1)p(θ1)+p(R|θ2)p(θ2))=0,4 ×0,8/(0,4 ×0,8+0,9 ×0,2)=0,64 p(θ2|R)=p(R|θ2)p(θ2)/(p(R|θ2)p(θ2)+p(R|θ1)p(θ1))=0,9× 0,2/0,5=0,36 p(θ1|B)=p(B|θ1)p(θ1)/(p(B|θ1)p(θ1)+p(B|θ2)p(θ2))=0,6 ×0,8/(0,6× 0,8+0,1× 0,2)=0,96 p(θ2|B)=p(B|θ2)p(θ2)/(p(B|θ1)p(θ1)+p(B|θ2)p(θ2))=0,02/0,5=0,04. По формуле полной вероятности получаем: p(R)= p(R/θ1)p(θ1 )+p(R/θ2 )p(θ2 )=0,8 ×4/10+0,2 9/10=0,5 p(B)=0,5. Перейдем к анализу дерева решений. Проанализируем ветвь е0. Запишем ОДО(е0,а1)=0,8× 40+0,2 ×(-20)=28 ОДО(е0,а2)=0,8× (-5)+0,2× 100=16. Это есть операция усреднения. Вернемся немного назад и остановимся в (е0). Тут необходимо решить, выбрать а1 или а 2. Ясно, что нужно выбрать а 1 ($28), заблокировав а2 ($16). Это есть операция свертывания.В результате у (е0) записывается $28.
Таким образом, двигаясь от конца мы воспользовались двумя средствами:
1) операцией усреднения в каждой случайной развилке;
2) операцией свертывания, заключающейся в выборе пути, ведущего к максимальной оценке будущего в каждой вершине выбора. Приведенным способом можно вывести и объяснить все оценки. Например, развилке (е2,RR) приписана оценка в $58. Методом усреднения мы прежде всего уясняем, что ОДО(е2,RR,a1)=0,4
×40+0,6× (-20)=4 ОДО(e2,RR,a2)=0,4× (-5)+0,6×(100)=58. Поэтому,в соответствии с принципамисвертывания, путь а1 должен быть отброшен и, следовательно, ОДО(е2,RR)=58. Но какова наша оценка развилки (е2) после уплаты взноса в $12 ? После этой точки мы можем очутиться на 3-х различных путях: на пути RR с вероятностью (4/10)(3/9)0,8+(9/10)(8/9)0,2= 24/90, RB или BR с вероятностью 42/90 или на пути BB с вероятностью 24/90. Следовательно, оценка точки (е2) на дереве равна ОДО(е2)=58 ×24/90+34,86× 42/90+40× 24/90=42,4.
Из дерева решений видно, что если включить в свои подсчеты начальные взносы, то нужно считать путь еs лучшим , чем е2, который в свою очередь лучше чем е0, лучше чем е1, и все они лучше чем “отказаться играть”. С нашей точки зрения оценка решения участвовать в игре будет равна 40,15 - 9=31,15.Это наилучшая оценка по всем экспериментам.
Из дерева решений видно, что ожидаемая ценность в (е0) равна $28, в то время как ожидаемая ценность в (е1) равна $35,2. Разница $7,2- это ожидаемый рост ценности игры в результате того, что Вы взяли один шар на пробу и выбрали наилучшее действие на основе полученной информации. Будем это
называть ожидаемая ценность информации от выбора эксперимента е1. Таким образом, ОЦИВ(е1)=$7,2 и ОЦИВ(е2)=$14,441. 
Не нашли, что искали? Воспользуйтесь поиском по сайту: ©2015 - 2024 stydopedia.ru Все материалы защищены законодательством РФ.
|