|
|
Порядок выполнения работыМИНИСТЕРСТВО НАУКИ И ОБРАЗОВАНИЯ РОССИЙСКОЙ ФЕДЕРАЦИИ ФГБОУ ВПО «ИРКУТСКИЙ ГОСУДАРСТВЕННЫЙ УНИВЕРСИТЕТ» ФИЛИАЛ В Г. БРАТСКЕ Базы данных Методические указания и контрольные задания для студентов заочной формы обучения направления «Прикладная информатика» Братск, 2015 Контрольная работа состоит из двух частей (задания типа А и В). В каждой части студент выполняет только те задания, которые соответствуют его варианту (см. таблицу в заключительной части контрольного задания). Вариант для контрольного задания выдается студенту преподавателем. Цель работы: изучить принципы работы с базой данных и спецификации запроса языка баз данных SQL, получить практические навыки составления и содержательной интерпретации запросов выборки данных (операторов SELECT), а также их выполнения с использованием реляционной системы управления базами данных (СУБД). При выполнении контрольной работы надо строго придерживаться требований к ее оформлению. Работы, выполненные без соблюдения указанных правил, а также не содержащие всех выполненных заданий, не зачитываются и возвращаются студентам для переработки.
Порядок выполнения работы
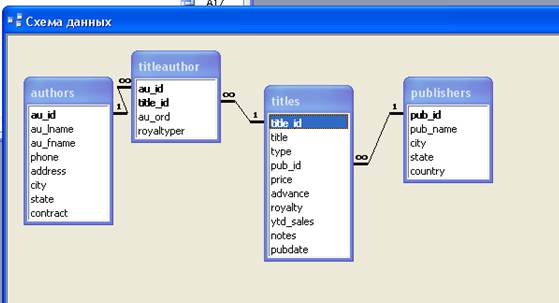
1. Изучить структуру и элементы SQL-запроса выборки, в том числе разделы FROM, WHERE, GROUP BY, HAVING, ORDER BY, а также предикаты условия поиска и агрегатные функции (см. приложение 1). 2. Изучить состав базы данных книготорговой компании (база данных pubs), структуру и семантику ее таблиц. 3. Создать базу данных книготорговой компании указанной ниже структуры средствами реляционной СУБД. В приложении 2 приведен полный пример базы данных pubs, из которого можно импортировать таблицы в создаваемую базу (предварительно скопировав таблицы в книгу табличного процессора), а затем настроить все необходимые параметры полей в режиме конструктора. 5. Создать индексы и ключевые поля. 6. Создать схему данных (см. рис 2). 7. Получить у преподавателя номер варианта. 8. В соответствии с вариантом задания типа А произвести содержательную интерпретацию заданных SQL-запросов, выполнить их средствами реляционной СУБД, проинтерпретировать результаты выполнения запросов. 9. В соответствии с вариантом задания В составить SQL-запросы по их заданному содержательному описанию, выполнить SQL-запросы в СУБД, проинтерпретировать результаты выполнения запросов. 10. Оформить отчет, включающий следующие разделы: титульный лист (с указанием варианта задания), цель работы, распечатка исходных таблиц БД, распечатку результатов выполнения запросов по заданиям типа А и В (и их словесную интерпретацию), выводы по итогам выполнения контрольной работы. Описание задания Рассмотрим простую предметную область жизнедеятельности, связанную с книгоизданием и маркетингом. В рамках данной предметной области существуют издатели, которые публикуют книги, авторы, которые книги пишут, и издания (сами книги). Разработана база данных pubs, определяющая описанную выше предметную область. Инфологическая модель предметной области представлена на рис. 1. На данном рисунке прямоугольниками обозначены типы сущностей (объектов), а ромбами - типы связей между сущностями. Атрибуты сущностей указаны мелким шрифтом в том же прямоугольнике, который отображает типы сущностей. Имя типа сущности отмечено в верхней части прямоугольника жирным шрифтом. Атрибуты связей в данном случае обозначены овалами. Как видно из рис. 1, у связи “Написана” имеется два атрибута: первый атрибут определяет порядок автора в названии книги, второй атрибут - гонорар автора книги.
Рис. 1. Структура предметной области «Номенклатура товара книготорговой компании». База данных книготорговой компании (база данных pubs) включает три таблицы, определяющие сущности: таблица authors определяет авторов, таблица publishers - издателей, а таблица titles - сами книги. Четвертая таблица titleauthor задает отношение между таблицами titles и authors. Она показывает, какие авторы написали какие книги. Связь между таблицами titiles и publishers определяется столбцом pub_id в данных таблицах. Ниже представлена структура используемых таблиц. Структура таблицы authors (от англ. «авторы»)
* В столбцах state таблиц authors и publishers используются следующие обозначения административных единиц США: CA - штат Калифорния, DC - округ Колумбия, IL - штат Иллинойс, IN - штат Индиана, KS -штат Канзас, MD - штат Мэриленд, MA - штат Массачусетс, MI - штат Мичиган, NY - штат Нью-Йорк, OR - штат Орегон, TN - штат Теннесси, TX - штатТехас, UT - штат Юта. ****Домен городов, используемый в таблицах authors и publishers, включает города Ann Arbor, Berkeley, Boston, Chicago, Corvallis, Colevo, Dallas, Gary, Lawrence, Menlo Park, Munchen, Nashville, New York, Oakland, Palo Alto, Paris, Rockville, Salt Lake City, San Francisco, San Jose, Vacaville, Walnul Creek, Washington. Структура таблицы publishers(от англ. «издатели»)
* В столбцах state таблиц authors и publishers используются следующие обозначения административных единиц США: CA - штат Калифорния, DC - округ Колумбия, IL - штат Иллинойс, IN - штат Индиана, KS -штат Канзас, MD - штат Мэриленд, MA - штат Массачусетс, MI - штат Мичиган, NY - штат Нью-Йорк, OR - штат Орегон, TN - штат Теннесси, TX – штат Техас, UT - штат Юта. ** В столбце country таблицы publishers используются следующие обозначения стран: France - Франция, Germany - Германия, USA - США. ****Домен городов, используемый в таблицах authors и publishers, включает города Ann Arbor, Berkeley, Boston, Chicago, Corvallis, Colevo, Dallas, Gary, Lawrence, Menlo Park, Munchen, Nashville, New York, Oakland, Palo Alto, Paris, Rockville, Salt Lake City, San Francisco, San Jose, Vacaville, Walnul Creek, Washington. Структура таблицы titles (от англю «заглавие, название, наименование, библиографические сведения ( о книге, монографии и т.п. )»)
*** В столбце type таблицы titles используются следующие типы книг: business - книги по бизнесу, mod_cook - книги по современной кулинарии, popular_comp - книги по компьютерной тематике, psychology - книги по психологии, trad_cook - книги по традиционной кулинарии, UNDECIDED - неопределенный тип книги. Структура таблицы titleauthor (от англ. «Заглавие-Автор(ы)»)
Если Вы импортировали последнюю таблицу, то создайте в ней 2 недостающих поля, заполните их подходящими значениями.
Рис 2. Схема данных. Необходимо дать содержательную интерпретацию SQL-запросам, выполнить их с помощью СУБД MS Access, дать содержательную интерпретацию результатам выполнения SQL-запросов. 1) SELECT au_lname, au_fname FROM authors
2) SELECT au_lname, au_fname FROM authors ORDER BY au_lname
3) SELECT au_lname, au_fname FROM authors ORDER BY au_lname, au_fname
4) SELECT title_id, price, ytd_sales, price*ytd_sales as "Доход от продажи" FROM titles ORDER BY price*ytd_sales
5) SELECT title_id, price, ytd_sales, price*ytd_sales as "Доход от продажи" FROM titles ORDER BY price*ytd_sales DESC
6) SELECT title_id, type, ytd_sales FROM titles ORDER BY type ASC, ytd_sales DESC
7) SELECT AVG(price) FROM titles
8) SELECT DISTINCT type FROM titles ORDER BY type ASC
9) SELECT DISTINCT city FROM authors ORDER BY city DESC
10) SELECT DISTINCT state FROM authors ORDER BY state
11) SELECT DISTINCT country FROM publishers ORDER BY country DESC
12) SELECT AVG(price), AVG(DISTINCT price) FROM titles
13) SELECT * FROM titles
14) SELECT au_lname, au_fname FROM authors WHERE state= "CA"
15) SELECT type, title_id, price FROM titles WHERE price*ytd_sales < advance
16) SELECT au_id, city, state FROM authors WHERE state= "CA" OR city= "Palo Alto"
17) SELECT title_id, price FROM titles WHERE price between 8 AND 15
18) SELECT title_id, price FROM titles WHERE type IN ("mod_cook", "trad_cook", "business")
19) SELECT au_lname, au_fname, city, state FROM authors WHERE city like "San*"
20) SELECT type, title_id, price FROM titles WHERE title_id like "PC8888"
21) SELECT type, title_id, price FROM titles WHERE title_id like "B*" 22) SELECT AVG(price) as "Средняя цена" FROM titles WHERE type= "business"
23) SELECT AVG(price) as "среднее" ,SUM(price) as "сумма" FROM titles WHERE type IN ("business", "mod_cook")
24) SELECT COUNT(*) FROM authors WHERE state= "CA"
25) SELECT COUNT(*) FROM titles WHERE title LIKE "Co*s"
26) SELECT title FROM titles WHERE ytd_sales IS NULL
27) SELECT au_lname, au_fname FROM authors WHERE contract=1 AND phone LIKE "408????-??2?"
28) SELECT phone FROM authors WHERE address LIKE "*Broadway Av.*"
29) SELECT title, pubdate FROM titles WHERE (((pubdate)>#01/01/1991#) and ((pubdate)<#6/12/1991#))
30) SELECT type, AVG(price) as "avg", SUM(price) as "sum" FROM titles WHERE type IN ("business", "psychology") GROUP BY type
31) SELECT type, pub_id, AVG(price) as "avg", SUM(price) as "sum" FROM titles WHERE type IN ("business", "mod_cook") GROUP BY type, pub_id
32) SELECT type, AVG(price) FROM titles WHERE price>4 GROUP BY type HAVING AVG(price)>50 33) SELECT au_id, COUNT(*) FROM authors GROUP BY au_id HAVING COUNT(*)>=1
34) SELECT type, MIN(price), MAX(price) FROM titles GROUP BY type ORDER BY type
35) SELECT type, MIN(price), MAX(price) FROM titles GROUP BY type HAVING MAX(price)-MIN(price)>=3
36) SELECT state, COUNT(pub_id) FROM publishers GROUP BY state
37) SELECT pub_name, AVG(price) as "avg", COUNT( title_id) as "count" FROM titles t INNER JOIN publishers p ON t.pub_id=p.pub_id GROUP BY pub_name
38) SELECT type, (MIN(price)+MIN(price))/2, AVG(price) FROM titles GROUP BY type HAVING type<> "UNDECIDED" ORDER BY 2 DESC
39) SELECT type, MIN(pubdate), MAX(pubdate) FROM titles GROUP BY type
41) SELECT * FROM titles, publishers
42) SELECT title, pub_name FROM titles, publishers WHERE titles.pub_id=publishers.pub_id
43) SELECT title, pub_name FROM titles INNER JOIN publishers ON titles.pub_id=publishers.pub_id
44) SELECT * FROM titles t, publishers p WHERE t.pub_id=p.pub_id
45) SELECT t.*, pub_name FROM titles t, publishers p WHERE t.pub_id=p.pub_id
46) SELECT a.city, a.state FROM authors a, publishers p WHERE a.city=p.city AND a.state=p.state
48) SELECT title, type FROM authors a, titles t, titleauthor ta, publishers p WHERE ta.title_id=t.title_id AND a.au_id=ta.au_id AND t.pub_id=p.pub_id AND p.city=a.city
49) SELECT au_lname, au_fname, title FROM authors a, titles t, titleauthor ta, publishers p WHERE ta.title_id=t.title_id AND a.au_id=ta.au_id AND t.pub_id=p.pub_id AND ((p.country= ‘USA’ AND t.type=’popular_comp’) OR (p.country=’France’ AND t.type=’psychology’))
50) SELECT au_lname, au_fname, city FROM authors a, titles t, titleauthor ta WHERE ta.title_id=t.title_id AND a.au_id=ta.au_id AND (city LIKE "*San*") AND (title LIKE "* the *" OR title LIKE "The *" OR title LIKE "* a *" OR title LIKE "A *")
52) SELECT pub_name FROM publishers p INNER JOIN titles t ON p.pub_id=t.pub_id WHERE $15>price AND type= "psychology" ORDER BY pub_name
53) SELECT pub_name, AVG(price) FROM titles t, publishers p WHERE t.pub_id=p.pub_id GROUP BY pub_name 54) SELECT pub_name, AVG(price) FROM titles t INNER JOIN publishers p ON t.pub_id=p.pub_id GROUP BY pub_name
55) SELECT au_lname, au_fname, title FROM authors a, titles t, titleauthor ta WHERE ta.title_id=t.title_id AND a.au_id=ta.au_id AND type= "popular_comp"
57) SELECT au_lname, au_fname, pub_name, COUNT(*) FROM authors a, titles t, titleauthor ta, publishers p WHERE ta.title_id=t.title_id AND a.au_id=ta.au_id AND t.pub_id=p.pub_id GROUP BY au_lname, au_fname, pub_name
58) SELECT MIN(price) FROM titles t, publishers p WHERE t.pub_id=p.pub_id GROUP BY country HAVING country= "USA"
59) SELECT pub_name, COUNT(*) FROM titles t, publishers p WHERE t.pub_id=p.pub_id AND (type= "mod_cook" OR type="trad_cook") GROUP BY pub_name
60) SELECT pub_name, COUNT(*) FROM publishers p, titles t WHERE p.pub_id=t.pub_id AND price>15000 GROUP BY pub_name ORDER BY pub_name DESC
62) SELECT state, COUNT(DISTINCT p.pub_id) FROM publishers p INNER JOIN titles t ON p.pub_id=t.pub_id GROUP BY state
63) SELECT title FROM titles WHERE pub_id= (SELECT pub_id FROM publishers WHERE pub_name= "Binnet & Hardley")
64) SELECT pub_name FROM publishers WHERE pub_id IN (SELECT pub_id FROM titles WHERE type= "business")
65) SELECT pub_name FROM publishers p WHERE EXISTS (SELECT * FROM titles t WHERE p.pub_id=t.pub_id AND type="popular_comp")
66) SELECT pub_name FROM publishers p WHERE NOT EXISTS (SELECT * FROM titles t WHERE p.pub_id=t.pub_id AND type="mod_cook")
67) SELECT pub_name FROM publishers WHERE pub_id NOT IN (SELECT pub_id FROM titles WHERE type="psychology")
68) SELECT type, price FROM titles WHERE price < (SELECT AVG(price) FROM titles)
69) SELECT type, AVG(price) FROM titles GROUP BY type HAVING AVG(price) < (SELECT AVG(price) FROM titles)
70) SELECT DISTINCT a.city, a.state FROM authors a WHERE NOT EXISTS (SELECT * FROM publishers p WHERE a.city=p.city AND a.state=p.state)
71) SELECT DISTINCT p.city, p.state FROM publishers p WHERE NOT EXISTS (SELECT * FROM authors a WHERE p.city=a.city AND p.state=a.state)
72) SELECT MIN(price) FROM titles t WHERE t.pub_id IN (SELECT pub_id FROM publishers WHERE country="USA")
73) SELECT title, type, price FROM titles WHERE price>ALL (SELECT price FROM titles WHERE type= "psychology")
74) SELECT COUNT(city) FROM publishers WHERE pub_id IN (SELECT pub_id FROM titles WHERE type= "psychology")
76) SELECT pub_name, state FROM publishers WHERE pub_id NOT IN (SELECT pub_id FROM titles)
77) SELECT title FROM titles WHERE pub_id NOT IN (SELECT pub_id FROM publishers)
79) SELECT au_lname, au_fname, price FROM authors a, titles t, titleauthor ta, publishers p WHERE ta.title_id=t.title_id AND a.au_id=ta.au_id AND t.pub_id=p.pub_id AND country="USA" AND price= (SELECT MIN(price) FROM titles tt, publishers pp WHERE tt.pub_id=pp.pub_id GROUP BY country HAVING country="USA")
80) SELECT DISTINCT au_lname, au_fname FROM authors a, titles t, titleauthor ta WHERE a.au_id=ta.au_id AND ta.title_id IN (SELECT title_id FROM titles WHERE ytd_sales= (SELECT MAX(ytd_sales) FROM titles))
81) SELECT DISTINCT a.city, a.state FROM authors a WHERE NOT EXISTS (SELECT * FROM publishers p WHERE a.city=p.city AND a.state=p.state) UNION SELECT DISTINCT p.city, p.state FROM publishers p WHERE NOT EXISTS (SELECT * FROM authors a WHERE p.city=a.city AND p.state=a.state)
84) SELECT pub_name, city, state, country FROM publishers p WHERE EXISTS (SELECT * FROM titles t WHERE t.pub_id=p.pub_id) AND 20>ALL (SELECT price FROM titles t WHERE t.pub_id=p.pub_id AND price IS NOT NULL)
88) SELECT au_lname, au_fname FROM authors a WHERE a.au_id IN (SELECT au_id FROM titleauthor ta WHERE ta.title_id IN (SELECT title_id FROM titles t WHERE "CA"=SOME (SELECT state FROM publishers p WHERE p.pub_id=t.pub_id))) ORDER BY au_lname, au_fname
92) SELECT city, state FROM authors UNION SELECT city, state FROM publishers ORDER BY state, city
93) SELECT city FROM authors UNION SELECT city FROM publishers
94) SELECT state FROM authors UNION SELECT state FROM publishers
95) SELECT city, state FROM authors WHERE state IS NOT NULL UNION SELECT city, state FROM publishers WHERE state IS NOT NULL ORDER BY city DESC, state ASC
96) SELECT state, MIN(price), MAX(price), AVG(price) FROM authors a, titles t, titleauthor ta WHERE ta.title_id=t.title_id AND a.au_id=ta.au_id GROUP BY state HAVING state<> "CA"
Задания типа B Необходимо составить SQL-запросы по их заданному содержательному описанию, выполнить SQL-запросы на SQL-сервере с использованием клиентских утилит ISQL/w или SQL-EM, проинтерпретировать результаты выполнения запросов. 1) Выбрать имена и фамилии авторов книг. 2) Выбрать имена и фамилии авторов, проживающих в Калифорнии. 3) Выбрать информацию о книгах, объем (стоимость) продаж которых в текущем году меньше стоимости предварительной продажи. Информация о книгах должна включать тип книги, идентификатор и цену книги. 4) Выбрать информацию об авторах, проживающих в штате Калифорния или в городе Salt Lake City. Информация об авторах должна включать идентификатор автора, город и штат проживания. 5) Выбрать все идентификаторы и цены книг, причем цена книги должна лежать в диапазоне от 100 до 150. В SQL запросе использовать предикат BETWEEN. 6) Выбрать все идентификаторы и цены книг по современной и традиционной кулинарии и по бизнесу. В запросе использовать предикат IN. 7) Выбрать информацию об авторах, проживающих в городах, название которых начинается со строки "san". Информация об авторах должна включать имя и фамилию автора, а также штат и город проживания. 8) Выбрать информацию о книгах, идентификаторы которых начинаются буквой "B", а кончаются строкой "1342". Информация о книгах должна включать тип, идентификатор и цену книги. 9) Выбрать информацию о книгах, идентификаторы которых начинаются буквой "B", заканчиваются строкой "1342", а вторым символом идентификатора являются буквы "A", "U" или "N". Информация о книгах должна включать тип, идентификатор и цену книги. 10) Выбрать имена и фамилии всех авторов, упорядоченные по возрастанию фамилий авторов. 11) Выбрать имена и фамилии всех авторов, упорядоченные в первую очередь по возрастанию фамилий и, во вторую очередь, по возрастанию имен. 12) Выбрать информацию о книгах, упорядоченную по возрастанию объема продаж (по стоимости). Информация о книгах должна включать идентификатор, цену, объем продаж (по количеству) и объем продаж (по стоимости). 13) То же, что 12, но использовать упорядочение по убыванию. 14) Выбрать информацию о всех книгах, упорядоченную по убыванию типа книги и числа проданных книг. Информация о книгах должна включать идентификатор и тип книги, а также число проданных книг. 15) Определить среднюю цену книги. 16) Определить среднюю цену книг по бизнесу. 17) Определить среднюю цену и стоимость всех книг по бизнесу и современной кулинарии 18) Определить число авторов, проживающих в Калифорнии. 19) Определить среднюю цену и сумму цен на книги по бизнесу и современной кулинарии отдельно для каждого типа книги. 20) Определить среднюю цену и сумму цен на книги по бизнесу и современной кулинарии для каждой комбинации типа книги и идентификатора издателя. 21) Выбрать те типы книг, средняя цена дорогих экземпляров (стоимостью более 30000) которых превышает 40000. В выбираемые данные помимо типа книги включить и среднюю цену дорогих экземпляров. 22) Подсчитать число строк в таблице authors, включающих одинаковые идентификаторы авторов. В выбираемые данные включить идентификатор автора и соответствующее ему число повторяющихся строк. 23) Выбрать названия книг и имена выпустивших их издателей. 24) То же, что и 23, но в разделе FROM запроса использовать операцию соединения INNER JOIN. 26) Определить среднюю цену выпускаемых каждым издателем книг. В выбираемые данные включить имя издателя и среднюю цену книги. 27) То же, что и 26, но в разделе FROM запроса использовать операцию соединения INNER JOIN. 28) Определить, кто из авторов написал какую книгу по психологии. В выбираемые данные включить имя и фамилию автора, а также название книги. 30) Выбрать все столбцы результата эквисоединения таблиц titles publishers по идентификатору издателя. 31) Выбрать все столбцы таблицы titles и столбец pub_name таблицы publishers результата эквисоединения данных таблиц по идентификатору издателя. 32) Выбрать все книги издательства Algodata Infosytems. В запросе использовать подзапрос для определения нужного идентификатора издателя. В условии поиска использовать предикат "=". В выбираемые данные включить название книги. 33) Выбрать всех издателей литературы по бизнесу. В запросе использовать подзапрос для выборки нужных идентификаторов издателей. В условии поиска использовать предикат IN. В выбираемые данные включить имя издателя. 34) Выбрать всех издателей литературы по бизнесу. В запросе использовать подзапрос, формирующий промежуточную таблицу, в которую включаются те строки из таблицы titles, которые могут “экви-соединиться” по идентификатору издателя со строками из таблицы publishers и которые представляют тип книг по бизнесу. В условии поиска основного запроса использовать предикат EXISTS. В выбираемые данные включить имя издателя. 35) Выбрать издателей, не выпускающих книг по бизнесу. Дополнительные условия формирования запроса взять из варианта 34 . 36) Выбрать издателей, не выпускающих книг по бизнесу. Дополнительные условия формирования запроса взять из варианта 33. 37) Выбрать тип и цену для всех книг, цена которых не превышает средней. В запросе использовать подзапрос, определяющий среднюю цену книг. 38) Выбрать тип и среднюю цену книг данного типа, причем эта средняя цена должна быть меньше средней цены всех книг. В запросе использовать подзапрос, определяющий среднюю цену всех книг. 39) Определить города и штаты проживания каждого из авторов и издателей в виде одной результирующей таблицы. 40) Определить все типы книг. Типы книг в результирующей таблице не должны повторяться. Вывести типы книг в порядке возрастания. 41) Определить все города, в которых проживают авторы. Названия городов в результирующей таблице не должны повторяться. Вывести названия городов в порядке убывания. 42) Определить все штаты, в которых проживают авторы. Названия штатов в результирующей таблице не должны повторяться. Вывести названия штатов в порядке возрастания. 43) Определить страны, в которых расположены издательства книг. Названия стран в результирующей таблице не должны повторяться. Вывести названия стран в порядке убывания. 44) Определить все города, в которых проживают авторы и находятся издательства. Названия городов в результирующей таблице не должны повторяться. Вывести названия городов в порядке возрастания. 45) Определить все штаты, в которых проживают авторы и находятся издательства. Названия штатов в результирующей таблице не должны повторяться. Вывести названия штатов в порядке убывания. 46) Определить города и штаты совместного проживания авторов и издателей. (В запросе использовать операцию INNER JOIN). 47) Определить города и штаты проживания авторов, в которых нет издательств. (В запросе использовать операцию NOT EXISTS). 48) Определить города и штаты нахождения издательств, в которых не проживают авторы. (В запросе неявно реализуется операция разности). 49) Определить, какой город в каком штате находится. Вывести названия городов в порядке возрастания (см задание 44). 50) Определить число книг, название которых начинается со строки "The" и заканчивается буквой "e". 51) Определить авторов на букву "G", проживающих в штатах Теннесси, Иллинойс, Канзас, Орегон или Калифорния, которые опубликовали книги, в которых есть слово из трех букв, причем средней буквой является буква "a". 52) Определить минимальную, максимальную и среднюю цену для каждого из типов книг. Выводимые данные должны быть упорядочены по убыванию типа книг. 53) Определить минимальную и максимальную цену для каждого из типов книг. В результирующую таблицу не включать те типы книг, для которых разность между максимальной и средней ценой меньше 7 долларов. 54) Вычислить среднюю цену всех книг и медиану цены. Под медианой понимается среднее значение всех различных цен всех книг (сумма цен поддеть на количество цен). 57) Определить для каждого штата минимальную, максимальную и среднюю цену книг авторов, проживающих в одном штате (использовать в за просе таблицы authors , titles, titleauthor ). 59) Найти цену самой дешевой книги (книг), вышедшей в США. В запросе использовать операцию группирования. 60) Найти авторов самых дорогих книг, вышедших в США. В запросе использовать подзапрос и операцию группирования. 62) Найти цену самой дорогой книги (книг), вышедшей в США. В запросе использовать подзапрос. 63) Определить число книг по компьютерам, выпущенных каждым издательством. 66) Определить названия и цену самых дешевых книг, вышедших в США. (Самые дешевые книги имеют минимальную цену). 68) Найти книги, цена которых меньше цены каждой из книг по традиционной кулинарии (использовать подзапрос, который находит миниальную цену книг по традиционной кулинарии). 69) Определить местонахождение издательств, цена каждой книги которых меньше заданной величины. 74) Определить для каждого штата число находящихся в нем издательств. 75) Определить число городов, в которых выпускается литература по компьютерам. В запросе использовать подзапрос. 77) Найти издательства, среди изданных книг которых найдется хоть одна книга по компьютерам стоимостью более двух долларов. В запросе использовать подзапрос. 78) Определить штаты, в издательства которых издали книги ценой более 10 долларов. В запросе использовать подзапрос. 80) Выбрать все столбцы таблицы titles. 82) Определить книги, число продаж для которых не указано. 83) Определить минимальную и максимальную цену книг, выпущенных издательствами. 85) Найти издательства, среди изданных книг которых найдется хоть одна книга по традиционной кулинарии стоимостью от 10000 до 40000. Можно использовать подзапрос 87) Определить для штатов число издательств, в которых выпускаются только книги ценой более 7 долларов. В запросе использовать подзапросы и предикат с квантором. 90) Определить издательства, не выпустившие книг. 91) Определить неопубликованные в издательствах книги. 92) Определить авторов, работающих по контракту и имеющих телефон с кодом города 415 (первые три цифры номера телефона). 93) Определить номера телефонов авторов, проживающих на Седьмой Авеню (Seventh Av.) 94) Определить книги, выпущенные в период с 1 июля 1991 г. по 30 октября 1991 г. (По умолчанию СУБД работает с датами в формате xx/yy/zz как с последовательностями месяц/день/год). 95) Вычислить для каждого типа книг среднее арифметическое минимальной и максимальной цены. Результат упорядочить по убыванию значений. 96) Определить временные интервалы, в рамках которых опубликованы книги разных типов.
Примечания: 1. При упорядочении фамилий и имен авторов, городов, штатов, типов книг используется лексикографический порядок.2. “Издатель” и “издательство” являются в данном случае синонимами. Соответственно этому синонимами являются “имя издателя” и “название издательства”.
ПРИЛОЖЕНИЕ 1 Язык SQL. Основные сведения и операторы Первый международный стандарт языка SQL был принят в 1989 г. (SQL/89). В конце 1992 г. Был принят новый международный стандарт SQL/92. “Родным” языком Microsoft SQL Server является язык Transact-SQL (T-SQL), являющийся диалектом стандартного языка SQL. T-SQL поддерживает большинство возможностей языков SQL/89 и SQL/92, а также ряд расширений, увеличивающих возможность программирования и гибкость языка. В частности, в язык T-SQL добавлены конструкции для задания последовательности операций управления в программе (например, if и while), локальных переменных и других конструкций, позволяющих писать более сложные запросы и строить программные объекты, хранящиеся на сервере, в том числе процедуры и триггеры. Язык SQL включает следующие языки:
В синтаксических конструкциях при описании языка будут использоваться следующие соглашения. Нетерминальные элементы заключаются в угловые скобки <>. Необязательная конструкция заключается в квадратные скобки []. Запись вида {A}… означает повторение конструкции А произвольное число раз (включая нулевое). Вертикальные разделители | читаются как “ИЛИ” и служат для выбора одной из конструкций, заключенных в скобки.
Оператор SELECT Оператор SELECT используется для запросов к базе данных и выборки результатов. Синтаксис оператора SELECT следующий: <оператор SELECT>::= SELECT [ALL | DISTINCT] <список выборки> <табличное выражение> ORDER BY <спецификация сортировки>] <табличное выражение>::= FROM <имя таблицы>[{,<имя таблицы>}…] [WHERE <условие поиска>] [GROUP BY <имя столбца> [{,<имя столбца>}…] [HAVING <условие поиска>] Если задано ключевое слово DISTINCT, то из результирующей таблицы удаляются повторяющиеся строки. Список выборки определяет, какие столбцы должны быть возвращены в результирующую таблицу. Данный список представляет список арифметических выражений над значениями столбцов таблиц из раздела FROM и констант. В простейшем случае он может быть, например, списком имен некоторых столбцов таблиц из раздела FROM. В случае, если вместо списка выборки стоит звездочка (*), то выбираются все столбцы таблиц из раздела FROM. В разделе FROM определяются таблицы, из которых будут извлекаться данные. Следует отметить, что рядом с именем таблицы можно указывать еще одно имя - синоним имени таблицы, который можно использовать в других разделах табличного выражения. Раздел WHERE служит своего рода фильтром при отборе данных. Выполнение раздела GROUP BY оператора выборки сводится к разбиению результирующей таблицы на множество групп строк, которое состоит из минимального числа таких групп, в которых для каждого столбца из списка столбцов раздела GROUP BY во всех строках каждой группы, включающей более одной строки, значения этого столбца совпадают. Результатом выполнения раздела HAVING является сгруппированная таблица, содержащая только те группы строк, для которых результат вычисления условия поиска является истинным. Условие поиска раздела HAVING задает условие на целую группу, а не на индивидуальные строки, поэтому в данном случае прямо можно использовать только столбцы, указанные в качестве столбцов группирования в разделе GROUP BY. Раздел ORDER BY позволяет установить желаемый порядок просмотра результирующей таблицы. Спецификация сортировки имеет следующий синтаксис: <спецификация сортировки>::= {<целое без знака> | <имя столбца>} [ASC | DESC] Как видно, фактически задается список столбцов, и для каждого столбца указывается порядок просмотра строк результирующей таблицы в зависимости от значений этого столбца (ASC - по возрастанию (умолчание), DESC - по убыванию). Указывать сортируемый столбец можно по имени или по порядковому номеру в результирующей таблице.
Предикаты условия поиска В условии поиска могут использоваться следующие предикаты: предикат сравнения, предикат BETWEEN , предикат IN, предикат LIKE, предикат NULL, предикат с квантором и предикат EXISTS. Предикат IN определяется следующим образом: <предикат IN>::= <выражение> [NOT] IN (<значение> [,<значение>...] | .<подзапрос>) Значение предиката является истинным, когда значение левого операнда совпадает хотя бы с одним значением списка правого операнда. Использование ключевого слова NOT осуществляет отрицание результата. Подзапрос- это запрос, используемый в предикате условия поиска. Результатом выполнения подзапроса является единственный столбец. Предикат BETWEEN определяется следующим образом: <предикат BETWEEN>::= <выражение> [NOT] BETWEEN <выражение> AND <выражение> По определению результат x BETWEEN y AND z тот же самый, что результат логического выражения x>=y AND x<=z. Предикат LIKE имеет следующий синтаксис: <предикат LIKE>::= <имя столбца> [NOT] LIKE <шаблон>[ESCAPE <escape-символ>] Значение предиката LIKE является истинным, если шаблон является подстрокой заданного столбца. При этом, если раздел ESCAPE отсутствует, то при составлении шаблона со строкой производится специальная интерпретация символов-заместителей шаблона: символ подчеркивания ("_") обозначает любой одиночный символ, символ процента ("%") обозначает последовательность произвольных символов произвольной длины (может быть нулевой), парные квадратные скобки представляют любой символ, записанный в скобках. Если же раздел ESCAPE присутствует и специфицирует некоторый одиночный символ x, то пары символов "x_" и "x%" представляют одиночные символы "_" и "%" соответственно. Предикат NULL описывается синтаксическим правилом: <предикат NULL>::= <имя столбца> IS [NOT] NULL Значение "x IS NULL" является истинным, когда значение x неопределено. Предикат EXISTS имеет следующий синтаксис: <предикат EXISTS>::= EXISTS <подзапрос> Значение предиката является истинным, когда результат вычисления подзапроса не пуст. Агрегатные функции Агрегатные функции (функции множества) в запросе предназначены для вычисления некоторого значения для заданного множества строк. Таким множеством строк может быть группа строк, если агрегатная функция применяется к сгруппированной таблице, или вся таблица. В языке SQL определены следующие агрегатные функции:
Грамматика агрегатных функций следующая: <агрегатная функция>::= COUNT(*) | <distinct-функция> | <all-функция> <distinct-функция>::= {AVG | COUNT | MAX | MIN | SUM} (DISTINCT <имя столбца>) <all-функция>::= {AVG | MAX | MIN | SUM} ([ALL]<выражение>) Вычисление функции COUNT(*) производится путем подсчета числа строк в заданном множестве. Функция типа distinct выполняет вычисления только над одним столбцом, а в вычислениях используются только уникальные значения столбца. При использовании функции типа all список значений формируется из значений арифметического выражения, вычисляемого для каждой строки заданного множества. 
Не нашли, что искали? Воспользуйтесь поиском по сайту: ©2015 - 2024 stydopedia.ru Все материалы защищены законодательством РФ.
|