|
|
Постреляционная модель данныхЛекция Тема: «Банки и базы данных» По способу доступа к данным БД разделяются на БД с локальным доступом и БД с удаленным (сетевым) доступом. БД с сетевым доступом предполагают различные архитектуры систем: файл-сервер и клиент-сервер. Архитектура «файл-сервер». При такой архитектуре все компьютеры объединены в локальную сеть, в которой находится файл-сервер, содержащий общие БД. При такой архитектуре на каждом компьютере пользователя работает своя копия СУБД. Приложение, выполняемое на компьютере пользователя, может получить прозрачный доступ к файл-серверу, на котором хранятся совместно используемые файлы. Когда приложению, требуется получить данные из совместно используемого файла, сетевое программное обеспечение автоматически считывает требуемый блок данных с сервера. Наиболее популярные БД, включая Microsoft Access, Paradox и dBase, поддерживают архитектуру «файл-сервер» [1]:
При выполнении обычных запросов эта архитектура обеспечивает великолепную производительность, поскольку в распоряжении каждой копии СУБД находятся все ресурсы компьютера пользователя. При выполнении многочисленных запросов эта архитектура создает слишком большую нагрузку на сеть и уменьшает производительность работы. Архитектура «клиент-сервер». При такой архитектуре все компьютеры объединены в локальную сеть, в которой находится сервер баз данных, содержащий общие БД и СУБД. Функции СУБД разделены на две части. Пользовательские программы, такие, как приложения, для формирования интерактивных запросов на выполнение операций с данными и генераторы отчетов работают на клиентском компьютере. Хранение данных и управление ими обеспечиваются сервером базы данных. Запрос передается по сети на сервер БД в виде SQL-запроса. Ядро БД на сервере обрабатывает запрос и просматривает БД, которая также расположена на сервере. После вычисления результата ядро БД посылает его обратно по клиентскому приложению, которое отображает его на экране монитора пользователя [1]:
Архитектура «клиент-сервер» позволяет сократить трафик и распределить процесс загрузки базы данных. Эта архитектура используется в современных СУБД Oracle, Informix, Sybase и др. Модели представление данных в базах данных Элементы базы данных База данных является системой, то есть она состоит из некоторого числа элементов и отношений между ними. Наименьшим из них является элемент данных, который в ряде случаев называют также полемилиатрибутом, и который соответствует одному реквизиту. Элемент данных характеризуется следующими характеристиками: именем, типом, длиной и точностью. Элементы данных организуются в записи, называемые в некоторых БД кортежами. Запись в общем случае соответствует показателю и несет данные об одном из однородных объектов, например, одном счете, одном работнике и т.п. В ряде случаев применяют понятие агрегата данных, которое занимает промежуточное положение между элементом данных и записью. Агрегат данных может быть простым (состоящим только из элементов данных) и составным (состоящим из элементов и простых агрегатов данных). Набор из однотипных записей называют файлом базы данных, который в некоторых случаях называют таблицей и который обычно соответствует массиву информации. Следует отметить, что файл базы данных далеко не всегда соответствует физическому файлу в памяти компьютера.В одном физическом файле может быть несколько файлов базы данных, и наоборот, информация файла базы данных может размещаться в нескольких физических файлах. База данных, таким образом, предстает как совокупность взаимосвязанных файлов базы данных. Значение приведенных терминов можно пояснить на схеме:
Элемент данных содержит один реквизит, в данном случае, название города «Москва». Агрегат данных состоит из несколько реквизитов, совокупность которых можно рассматривать как одно целое. Запись состоит из одного или нескольких элементов данных и содержит информацию об одном объекте, в приведенном примере - об одном предприятии. Совокупность однотипных записей составляет файл базы данных, на схеме - это файл с информацией о предприятиях. Совокупность таких файлов, тем или иным способов взаимосвязанных между собой, представляет собой базу данных. На схеме показано три файла информации, связанной между собой следующим образом: «предприятия обслуживаются банками, у них открыты счета в этих банках». Если связи между файлами нет, то их совокупность нельзя считать базой данных. Взаимосвязи данных в БД могут быть в виде отношений: · «один к одному» - одна запись связана с одной записью · «один ко многим» - одна запись связана со многими записями · «многие ко многим» - многие записи связаны со многими записями. Выбор того или иного вида связей определило три основные модели представления данных: иерархические, сетевые, реляционные. Иерархическая модель представляется в виде древовидного графа, в котором объекты выделяются по уровням соподчиненности (иерархии) объектов [4]:
На верхнем, первом уровне находится информация об объекте "поставщики" (П), на втором - о конкретных поставщиках П1, П2, и П3, на нижнем, третьем, уровне - о товарах, которые могут поставлять конкретные поставщики. В иерархической модели должно соблюдаться правило: каждый порожденный узел не может иметь больше одного порождающего узла (только одна входящая стрелка); в структуре может быть только один непорожденный узел (без входящей стрелки) - корень. Узлы, не имеющие выходных стрелок, носят название листьев. Для поиска необходимой информации нужно двигаться от корня к листьям, т.е. сверху вниз, что значительно упрощает доступ к искомой информации. Перемещение по иерархической модели осуществляется с помощью ссылок. Например, определим какие поставщики связаны с товаром Т1. Для этого нужно сделать три прохода по дереву от корня к листьям (за один проход по дереву невозможно, получить информацию о том, какие поставщики поставляют товар Т1). В иерархической модели используется вид связи между элементами данных "один ко многим". Типичным представителем семейства баз данных, основанных на иерархической модели, является Information Management System (IMS) фирмы IBM, первая версия которой появилась в 1968 г. База данных с такой схемой могла бы выглядеть следующим образом:
Достоинство модели: высокая скорость выполнения операций над данными. Быстрота доступа к данным. Недостаток модели: 1) жесткость структуры БД (не может быть изменена после ввода данных, что препятсятвует модернизации и развитию БД) 2) трудность в понимании обычным пользователем.
Быстрота доступа к данным в иерархической модели достигнута за счет потери информационной гибкости. Указанные недостатки ограничивают применение иерархической структуры. Сетевая модель является более сложной и отличается от иерархической модели наличием горизонтальных связей, т.е. допускается подчиненность одного объекта многим объектам. В сетевой модели используется вид связи между данными "многие ко многим". Сетевая модель базы данных для поставленной задачи имеет вид:
На диаграмме указаны независимые (основные) типы данных П1, П2 и П3, т.е. информация о поставщиках, и зависимые - информация о товарах Т1,, Т2 и Т3. В сетевой модели допустимы любые виды связей между элементами информации и отсутствует ограничение на число обратных связей.
Перемещение по сетевой модели осуществляется с помощью ссылок. Например, за одно обращение к модели можно получить информацию о том, какие поставщики поставляют товар Т1. Примером системы управления данными с сетевой организацией является Integrated Database Management System (IDMS) компании Cullinet Software Inc., разработанная в середине 70-х годов. Она предназначена для использования на "больших" вычислительных машинах. Архитектура системы основана на предложениях Data Base Task Group (DBTG), Conference on Data Systems Languages (CODASYL), организации, ответственной за определение стандартов языка программирования Кобол. Достоинство сетевой модели БД - быстрота доступа к данным, большая информационная гибкость по сравнению с иерархической моделью. Однако сохраняется общий для двух моделей недостаток - достаточно жесткая, сложная структура, что препятствует модернизации и развитию БД. При необходимости частой реорганизации информационной базы применяют наиболее совершенную модель БД - реляционную, в которой отсутствуют различия между объектами и взаимосвязями. Реляционная модель БД. Концепция реляционной модели впервые были сформулированы в работах американского ученого, сотрудника фирмы IBM, Э. Ф. Кодда в 1970 –х г.г.. Откуда происходит ее второе название - модель Кодда. В реляционной модели данные представляются в виде двумерных таблиц, связанных между собой. Каждая таблица состоит из строк (однотипных записей или кортежей) и столбцов (полей или атрибутов). Слово «однотипных» означает, что все записи обладают одним и тем же набором атрибутов. Каждый столбец имеет уникальное для своей таблицы имя. Столбцы расположены в определенном порядке. Каждый атрибут может принимать множество значений из определенной области (домен). Строки в отличие от столбцов не имеют имен, порядок их следования не определен, а количество не ограничено. Рассмотрим таблицу, содержащую данные о сотрудниках предприятия:
Можно увидеть, что у всех трех записей атрибуты одинаковы, однако принимают разные значения. Так, для записи №1 атрибут «табельный №» принимает значение «008976», а для записи №2 – «008980» и т.д. Значения некоторых атрибутов у разных записей может совпадать, например, у записей №1 и №2 одинаковое значение атрибута «код отдела». Однако в каждой таблице должен быть атрибут (или совокупность атрибутов), значение которого никогда не повторяется и однозначно идентифицирует каждую ее строку таблицы. Это нужно для того, чтобы при работе с базой можно было отличать одну запись от другой. Такие атрибуты называют уникальными.
Уникальный атрибут таблицы или совокупность ее уникальных атрибутов называют первичным ключом или ключевым полем.
В данной таблице ключом является атрибут «табельный №». В том случае, когда запись однозначно определяется значениями нескольких полей (или совокупностью уникальных атрибутов) то имеет место составной ключ. В ряде случаев атрибут может не иметь никакого значения, например, у сотрудника №3 нет рабочего телефона, и соответствующий атрибут не заполнен. В этом случае говорят, что атрибут имеет нулевое значение. Ключ не может иметь нулевое значение. Но простая совокупность таблиц не может считаться базой данных, если между ними не существует определенных связей (отношений). В реляционных базах данных связи указывают на соответствие между записями двух таблиц. Рассмотрим вторую таблицу, содержащую информацию об отделах:
Между двумя приведенными таблицами можно установить отношение «СОТРУДНИК - работает в – ОТДЕЛЕ». Если требуется узнать информацию об отделе, в котором работает сотрудник, нужно взять значение атрибута "код отдела" в таблице "СОТРУДНИКИ" и найти соответствующий код в таблице "ОТДЕЛЫ". Таким образом, две записи из разных таблиц как бы объединятся в одну:
+
=
Можно увидеть, что отношения между двумя таблицами устанавливаются на основе соответствия значений атрибутов двух таблиц, в нашем случае это атрибут «код отдела» таблицы «СОТРУДНИКИ» и атрибут «код» таблицы «ОТДЕЛЫ». Такие атрибуты называют атрибутами связи.
Атрибуты, на основе которых устанавливаются отношения между таблицами, называются атрибутами связи.
Атрибут связи в одной таблице должен быть ключом. В приведенном примере атрибут «код» является ключом для таблицы «ОТДЕЛЫ». Если бы это было не так, и коды отделов в этой таблице повторялись, невозможно было бы определить, о каком из отделов говорится в первой таблице. Второй атрибут связи - в данном случае атрибут «код отдела» таблицы «СОТРУДНИКИ» - называют внешним ключом, так как он ссылается на ключ другой («внешней») таблицы. Атрибут связи с другой (внешней) таблицей называется внешним ключом таблицы.
Для поддержания целостности данных необходимо, чтобы внешний ключ всегда ссылался на существующий ключ. Например, если в таблице «СОТРУДНИКИ» указать код отдела со значением 028, а в таблице «ОТДЕЛЫ» отдела с таким кодом не будет, то целостность данных нарушится - сотрудник будет показан работником несуществующего отдела. Поэтому сама база данных или работающее с ней приложение должно запрещать ввод значений внешнего ключа, ссылающегося на несуществующий ключ. Подобное нарушение целостности может возникнуть и в том случае, когда удаляется одна из записей таблицы, содержащей ключевое поле. Например, при удалении из таблицы «ОТДЕЛЫ» записи №3, содержащей ключ 024, записи №1 и №2 таблицы «СОТРУДНИКИ» будут ссылаться на несуществующий отдел Для приведенной выше задачи о поставщиках и товарах логическая структура реляционной БД будет содержать три таблицы (отношения): R1, R2, R3 состоящие соответственно из записей о поставщиках, о товарах и о поставках товаров поставщиками: R1 (поставщики):
R2 (товары):
R3 (поставка товаров):
Преимуществами реляционной модели БД являются: 1) Простота модели (таблицы привычны для представления информации). Эта модель более понятна для конечного пользователя. 2) Более высокая гибкость при расширении БД, состава запросов к ней. Возможность изменения структуры БД после ввода данных. Недостаток: более медленный доступ к данным; сложность в описании иерархических и сетевых связей.
В настоящее время реляционные базы данных используются практически повсеместно. Во многом это связано с простотой и наглядностью реляционной базы данных - представление данных в виде таблиц вполне соответствует традиционным «некомпьютерным» технологиям обработки информации, оно достаточно понятно большинству пользователей. Отметим также, что реляционная модель данных наилучшим образом соответствует структуре экономической информации. На этой модели базируются практически все современные СУБД: Clipper, dBase, Paradox, FoxPro, Access, Oracle и др.. Постреляционная модель данных Постреляционные модели данных используются для иерархической информации, когда один и тот же объект приходится «раскладывать» на несколько таблиц. Постреляционные модели данных, в сущности, является развитием реляционной модели, в которых снято ограничение на неделимость атрибутов. Если в реляционной базе данных атрибут (поле) каждой записи может содержать только одно значение, то в постреляционной модели, напротив, поле может содержать несколько значений, или даже целую таблицу. Например, счет-фактура - многострочные документ. В каждом из таких документов есть общие реквизиты, например, номер, дата, наименование поставщика и получателя. В таблице «счета-фактуры» такие реквизиты составляют одну запись. Однако, счет-фактура - многострочный документ, и для хранения каждой из строк, содержащей наименование товара, его количество, цену, сумму также потребуется отдельная запись. Приходится, таким образом, создавать дополнительную таблицу «строки счетов-фактур», связанную с предыдущей. Данные каждого счета-фактуры будут содержаться в одной записи первой таблицы и в одной или нескольких записях второй:
Такой подход имеет недостатки: при использовании реляционной модели для описания иерархических данных увеличивается число таблиц и связей между ними, что приводит к замедлению выполнения запросов,усложняет структуру базы данных и ее понимание пользователями. Эти недостатки преодолеваются в постреляционной модели данных за счёт того, что появляется возможность «вложить» одну таблицу в другую и представить бизнес-объект всего одной записью:
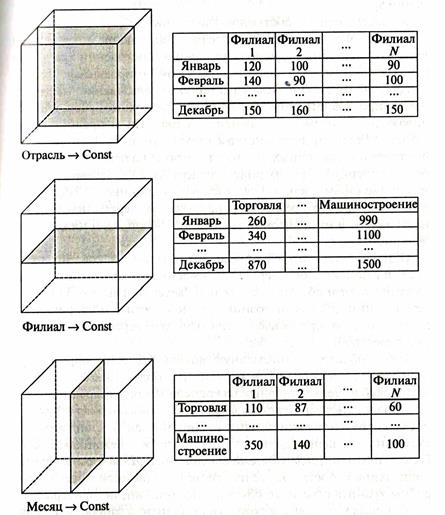
Как утверждают разработчики постреляционных СУБД, скорость выполнения запросов в них возрастает до 20 раз по сравнению с реляционными СУБД. Однако переход от реляционных баз данных, получивших повсеместное распространение, к постреляционным, связан со значительными затратами и носит пока ограниченный характер. Хранилища данных В последнее время современные ЭИС, предоставляющих своим пользователям помимо оперативных данных повседневной деятельности предприятий, банков и т.д., еще и аналитические данные, строится на основе хранилищ данных (Data Warehouse). (Основоположник данной технологии - Уильям Инмон) Если реляционные базы данных состоят из двумерных таблиц, связанных между собою, то хранилища данных - из многомерных (трех и более) таблиц данных (кубы, гиперкубы). В основе хранилища данных лежит понятие многомерного информационного пространства, или гиперкуба (многомерный куб). Величины, хранящиеся в ячейках этого куба и называемые фактами, представляют собой количественные показатели, характеризующие деятельность предприятия. Измерения куба представляют собой множество однотипных данных, предназначенных для описания фактов, например филиалы, товары; поставщики, клиенты, время и др Каждая ячейка данного куба «отвечает» за конкретный набор значений по его измерениям, например обороты балансовых счетов за день, квартал, год в разрезе филиалов..
На рис. Изображен трехмерный куб. в качестве измерений использованы время, отрасли, филиалы, в качестве фактов- сумма выданных кредитов.
В хранилище данных содержится не только первичные данные оперативной обработки, но и данные аналитической обработки (результаты вычислений в готовом виде): · полученные в результате расчетов (расчет производных показателей, таких как фактическое исполнение бюджета, ликвидность, маржа и др.). · агрегирования (расчет обобщенных показателей, например вычисление месячного, квартального и годового баланса). · Интеграции (консолидация данных), поступающих из разных источников (суммирование данных по организационной иерархии, например вычисление сводного баланса банка). · Кроме того, содержатся хронологические данные, накопленные за длительный период времени.
Это и отличает ХД от обычной БД.
Хранилища данных представляют собой предметно-ориентированный, интегрированный, неизменчивый, поддерживающий хронологию набор данных, обеспечивающий максимально быстрый и удобный доступ к информации, и необходимый для анализа и поддержки принятия решений.
Т.е. для решения двух классов задач: 1) обеспечения повседневной работы предприятия по вводу и оперативной обработке данных (решаются с помощью ОLTP (Online Transactional Processing)-систем и технологий, например – автоматизированные банковские системы (АБС), учетные системы и др.) 2) обеспечения комплексного многомерного анализа данных для выявления тенденций развития, прогнозирования состояния, оценки рисков и т.д. ( решаются с помощью ОLАP (Online Analytical Processing)-систем и технологий- систем оперативной аналитической обработки) Хранилище данных ориентировано на высшее и среднее руководство , ответственное за принятие решения и развитие бизнеса.
Сравнение систем обработки:
Вся работа с кубом сводтся к различным его поворотам, формированию среза, детализации и агрегации (т.е.информацию в ячейках куба можно рассматривать под разным углом зрения). Например:
Главное достоинство многомерной модели – быстрота поиска данных (на 1-2 порядка выше, чем в реляционных). Для их поиска не нужно организовывать связи между таблицами как в реляционных моделях. Однако гиперкуб требует больших объемов памяти, т.к. в нем необходимо заранее зарезервировать место для возможных данных аналитической обработки. Кроме того, возникают сложности с модификацией данных, поскольку добавление еще одного измерения, требует перестройки гиперкуба. Поэтому его целесообразно использовать, когда есть стабильный во времени набор измерений.
Витрины данных
Одним из вариантов реализации на практике хранилищ данных, является построение витрин данных (Data Marts).
Витрина данных – относительно небольшие тематические хранилища данных, создаваемые с целью информационного обеспечения аналитических задач конкретных подразделений в конкретной функциональной области. .
Например - это анализ рынков, анализ ресурсов, анализ денежных потоков, анализ клиентской базы, управление активами и пассивами и т.д.
В отличие от хранилищ данных: 1) Хранилище данных создается для решения корпоративных задач усилиями всей корпорации. Витрина данных создается для решения конкретного однородного круга задач. 2) В хранилище данных находятся максимально детализированные данные и агрегированные данные, в витрине данных – только агрегированные. 3) В отличие от хранилища витрина данных содержит незначительный объем исторической информации и значительный, привязанный к моменту времени, когда он отвечает требованиям решения задачи.
Витрины данных можно представить в виде логически и физически разделенных подмножеств хранилища данных:

Не нашли, что искали? Воспользуйтесь поиском по сайту: ©2015 - 2024 stydopedia.ru Все материалы защищены законодательством РФ.
|