
|
|
Основные законы распределения случайных величин и их назначение.Идея вероятностных рассуждений. Первый, самый естественный шаг вероятностных рассуждений заключается в следующем: если вы имеете некоторую переменную, принимающую значения случайным образом, то вам хотелось бы знать, с какими вероятностями эта переменная принимает определенные значения. Совокупность этих вероятностей как раз и задает распределение вероятностей. Фактически, законы распределения случайных величин служат математическими моделями для реальных объектов и явлений, что позволяет в некоторых случаях применять их для расчетов и анализа ситуации. Рассмотрим несколько основных законов распределения случайных величин, и какие ситуации ими моделируются. Нормальное распределение. Нормальное распределение вероятностей особенно часто используется при анализе данных. Нормальное распределение дает хорошую модель для реальных явлений, в которых: 1) имеется сильная тенденция данных группироваться вокруг центра; 2) положительные и отрицательные отклонения от центра равновероятны; 3) частота отклонений быстро падает, когда отклонения от центра становятся большими. Функция распределения (1.5.1) и функция плотности (1.5.2) нормального распределения и их графики (рис. 1.5.1):
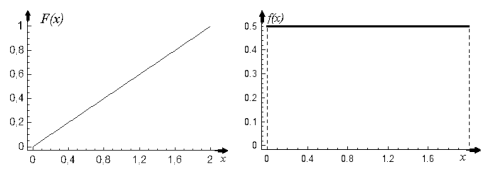
Рис. 1.5.1. Графики функции распределения и функции плотности нормального закона распределения. Основные характеристики нормального закона: ·Среднее, мода, медиана: M (X) = xmod= xmed = m . ·Дисперсия: D(X ) =σ2 . ·Асимметрия: β1 =0 . ·Эксцесс: β2 =0 . Равномерное распределение. Равномерное распределение полезно при описании переменных, у которых каждое значение равновероятно, иными словами, значения переменной равномерно распределены в некоторой области. Ниже приведены формулы для функции распределения (1.5.3) и для функции плотности (1.5.4) равномерной случайной величины, принимающей значения на отрезке [a ,b ] и их графики (рис. 1.5.2).
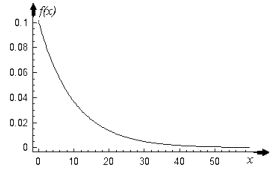
Рис. 1.5.2. Графики функции распределения и функции плотности равномерного закона распределения. Числовые характеристики равномерного закона: Среднее, медиана: M(X )= xmed =(a+ b)/2 Дисперсия: D (X)= (b-a)2/12 Асимметрия: β1 = 0 Эксцесс: β2 = -1.2 . Экспоненциальное распределение. Имеют место события, которые на обыденном языке можно назвать редкими. Если T –время между наступлениями редких событий, происходящих в среднем с интенсивностью λ , то величина T имеет экспоненциальное распределение с параметром λ. Экспоненциальное распределение часто используется для описания интервалов между последовательными случайными событиями, например интервалов между заходами на непопулярный сайт, так как эти посещения являются редкими событиями. Это распределение обладает очень интересным свойством отсутствия последействия, или, как еще говорят, марковским свойством, в честь знаменитого русского математика Маркова А. А., которое можно объяснить следующим образом. Если распределение между моментами наступления некоторых событий является показательным, то распределение, отсчитанное от любого момента t до следующего события, также имеет показательное распределение (с тем же самым параметром). Иными словами, для потока редких событий время ожидания следующего посетителя всегда распределено показательно независимо от того, сколько времени вы его уже ждали. Функция плотности и ее график представлены ниже. f (x) = λ e- λ x , x ≥0 (1.5.5)
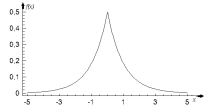
Рис. 1.5.3. График функции плотности экспоненциального распределения. Числовые характеристики экспоненциального закона: Среднее: M(X ) = 1/λ ·Мода: xmod= 0 ·Медиана: xmed =(1/λ) ln2 ·Дисперсия:D(X) =1/λ2 . ·Асимметрия: β1 =2 . ·Эксцесс: β2 =6 Распределение Лапласа. Функция плотности распределения Лапласа, или, как его еще называют, двойного экспоненциального, используется, например, для описания распределения ошибок в моделях регрессии. Взглянув на график этого распределения, вы увидите, что оно состоит из двух экспоненциальных распределений, симметричных относительно оси OY Если параметр положения равен 0, то функция плотности распределения Лапласа имеет вид:
Рис. 1.5.4. График функции плотности распределения Лапласа.
Числовые характеристики распределения Лапласа: Среднее: M(X ) = 0 . Мода: xmod =0 Медиана: xmed = 0 Дисперсия: D(X)=2/λ2 . Асимметрия: β1= 0 Эксцесс: β2= 3 Логнормальное распределение. Случайная величина h называется логарифмически нормальной, или логнормальной, если ее натуральный логарифм ( ln h ) подчинен нормальному закону распределения. Логнормальное распределение используется, например, при моделировании таких переменных, как доходы, возраст новобрачных или допустимое отклонение от стандарта вредных веществ в продуктах питания. Итак, если величина x имеет нормальное распределение, то величина y = ex имеет логнормальное распределение. Если вы подставите нормальную величину в степень экспоненты, то легко поймете, что логнормальная величина получается в результате многократных умножений независимых величин, так же как нормальная случайная величина есть результат многократного суммирования. Плотность логнормального распределения имеет вид:
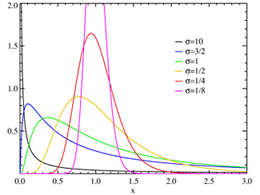
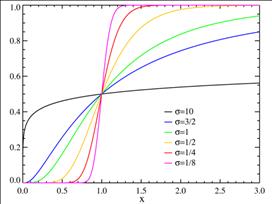
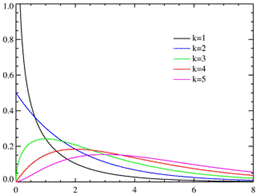
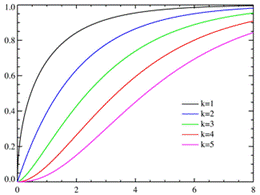
Рис. 1.5.5. График функции плотности логнормального распределения при 𝜇=0. Числовые характеристики логнормального закона: Среднее: M( X) = me1/2𝜎2 . Мода: xmod= me-σ2 Медиана: xmed = m Дисперсия: D( X) = m2e𝜎2 (eσ2 -1) Асимметрия: β1= (eσ2 -1)1/2 (eσ2 +2) Эксцесс: β2 =(eσ2 -1)(e3𝜎2 +3e2σ2 +6eσ2 +6) Распределение Хи -квадрат. Сумма квадратов m независимых нормальных величин со средним 0 и дисперсией 1 имеет хи-квадрат распределение с m степенями свободы. Это распределение наиболее часто используется при анализе данных. Число степеней свободы m определяет число независимых, или "свободных", квадратов, входящих в сумму. Плотность вероятности хи-квадрат распределение имеет вид (1.5.8):
При отрицательных x плотность обращается в ноль.
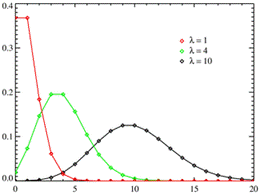
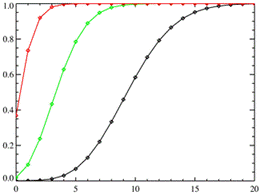
Рис. 1.5.6. Графики функции плотности распределения хи-квадрат при разных степенях свободы k=m. Следует отметить несколько особенностей хи-квадрат распределения. Во-первых, хи-квадрат распределение фактически является частным случаем более общего гамма-распределения. Во-вторых, важную роль играет распределение случайной величины, равной квадратному корню из случайной величины, имеющей хи-квадрат распределение с двумя степенями свободы которое называется распределением Рэлея. Распределение Рэлея широко применяется при решении задач, связанных с попаданием в двумерную мишень; кроме того, оно служит предельным распределением экстремальных значений узкополосного гауссова случайного сигнала при стремлении ширины полосы сигнала к нулю. В-третьих, с ним связано еще одно важное распределение, отвечающее случайной величине, равной квадратному корню из хи-квадрат случайной величины с тремя степенями свободы, называемое распределением Максвелла. Распределение Максвелла применяется при решении задач, связанных с попаданием в трехмерные мишени. В-четвертых, хи-квадрат распределение приближается к нормальному по мере увеличения числа степеней свободы. Числовые характеристики квадрат распределения: Среднее: M(X ) = m. Мода: xmod = m -2 . Дисперсия: D(X ) = 2m. Асимметрия:𝛽1=23/2 /m0.5. Эксцесс:β2 =12/m . Распределение Пуассона. Распределение Пуассона иногда называют распределением редких событий. Примерами переменных, распределенных по закону Пуассона, могут служить: число несчастных случаев, число дефектов в производственном процессе и т д. Распределение Пуассона определяется формулой:
Рис. 1.5.7. График функции плотности распределения Пуассона.
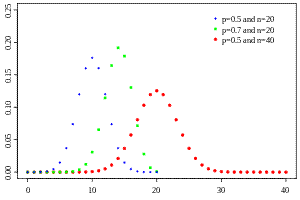
Биномиальное распределение. Биномиальное распределение является наиболее важным дискретным распределением, которое сосредоточено всего лишь в нескольких точках. Этим точкам биномиальное распределение приписывает положительные вероятности. Таким образом, биномиальное распределение отличается от непрерывных распределений (нормального, хи-квадрат и др.), которые приписывают путевые вероятности отдельно выбранным точкам и называются непрерывными. Параметрами биномиального распределения являются вероятность успеха p (q =1- p) и число испытаний n . Биномиальное распределение полезно для описания распределения биномиальных событий, таких, например, как количество мужчин и женщин в случайно выбранных компаниях. Особую важность имеет применение биномиального распределения в игровых задачах. Комбинаторная формула (3.7) для вероятности m успехов в n испытаниях записывается так:
p –вероятность успеха; q = 1- p ; n –число испытаний; m = 0, 1, ..., m.
Рис. 1.5.8. График биномиального распределения. Числовые характеристики биномиального распределения: ·Среднее: M(X ) = np . ·Мода: xmod : p(n+1)-1≤ xmod ≤ p(n+1) ·Дисперсия: D(X ) = np(1- p) . ·Асимметрия:
·Эксцесс:
Существует еще множество других законов распределений, более детально с ними можно познакомиться в специальной литературе. Распределение Стьюдента Распределение Стьюдента (t-распределение, предложено в 1908 г. английским статистиком В. Госсетом, публиковавшим научные труды под псевдонимом Student) характеризует распределение случайной величины
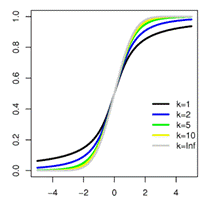
(3.5) Величина k характеризует количество степеней свободы. Плотность распределения – унимодальная и симметричная функция, похожая на нормальное распределение, рис. 3.7.
Область изменения аргумента t от –∞ до ∞ . Математическое ожидание и дисперсия равны 0 и k/(k–2) соответственно, при k>2. По сравнению с нормальным распределение Стьюдента более пологое, оно имеет меньшую дисперсию. Это отличие заметно при небольших значениях k, что следует учитывать при проверке статистических гипотез (критические значения аргумента распределения Стьюдента превышают аналогичные показатели нормального распределения). Таблицы распределения содержат значения для односторонней Распределение Стьюдента применяется для описания ошибок выборки при k <30. При k >100 данное распределение практически соответствует нормальному, для 30 < k < 100 различия между распределением Стьюдента и нормальным распределением составляют несколько процентов. Поэтому относительно оценки ошибок малыми считаются выборки объемом не более 30 единиц, большими – объемом более 100 единиц. 
Не нашли, что искали? Воспользуйтесь поиском по сайту: ©2015 - 2024 stydopedia.ru Все материалы защищены законодательством РФ.
|
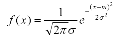
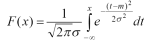

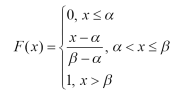
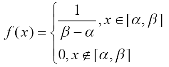
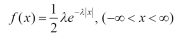
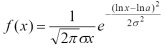
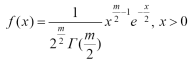
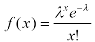
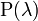
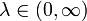

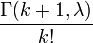

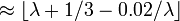

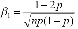
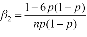
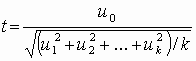 , где u0, u1, …, uk взаимно независимые нормально распределенные случайные величины с нулевым средним и конечной дисперсией. Аргумент t не зависит от дисперсии слагаемых. Функция плотности распределения Стьюдента
, где u0, u1, …, uk взаимно независимые нормально распределенные случайные величины с нулевым средним и конечной дисперсией. Аргумент t не зависит от дисперсии слагаемых. Функция плотности распределения Стьюдента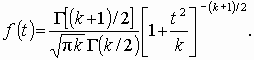

 — число степеней свободы
— число степеней свободы
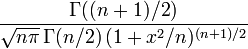

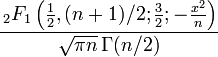 где
где  — гипергеометрическая функция
— гипергеометрическая функция
 , если
, если 
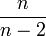 , если
, если 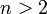
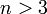
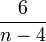 , если
, если 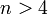
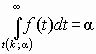 или двусторонней
или двусторонней 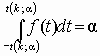 критической области.
критической области.