
|
|
Архитектура линейной сетиМодель нейрона.На рис. 5.1 показан линейный нейрон с двумя входами. Он имеет структуру, сходную со структурой персептрона; единственное отличие состоит в том, что используется линейная функция активации purelin.
Весовая матрица W в этом случае имеет только одну строку и выход сети определяется выражением
Векторы входа, расположенные выше этой линии, соответствуют положительным значениям выхода, а расположенные ниже – отрицательным. Это означает, что линейная сеть может быть применена для решения задач классификации. Однако такая классификация может быть выполнена только для класса линейно отделимых объектов. Таким образом, линейные сети имеют то же самое ограничение, что и персептрон. Архитектура сети.Линейная сеть, показанная на рис. 5.3, а, включает S нейронов,
Рис. 5.3 На рис. 5.3, б показана укрупненная структурная схема этой сети, вектор выхода a Создание модели линейной сети Линейную сеть с одним нейроном, показанную на рис. 5.1, можно создать следующим образом: net = newlin([–1 1; –1 1],1); Первый входной аргумент задает диапазон изменения элементов вектора входа; второй аргумент указывает, что сеть имеет единственный выход. Начальные веса и смещение по умолчанию равны 0. Присвоим весам и смещению следующие значения: net.IW{1,1} = [2 3]; net.b{1} =[–4]; Теперь можно промоделировать линейную сеть для следующего предъявленного p = [5;6]; a = sim(net,p) a = 24 Обучение линейной сети Для заданной линейной сети и соответствующего множества векторов входа и целей можно вычислить вектор выхода сети и сформировать разность между вектором выхода Как и для персептрона, применяется процедура обучения с учителем, которая использует обучающее множество вида:
где Требуется минимизировать следующую функцию средней квадратичной ошибки:
Процедура настройки В отличие от многих других сетей настройка линейной сети для заданного обучающего множества может быть выполнена посредством прямого расчета с использованием Предположим, что заданы следующие векторы, принадлежащие обучающему множеству: P = [1 –1.2]; T = [0.5 1]; Построим линейную сеть и промоделируем ее: net = newlind(P,T); Y = sim(net, P); Y = 0.5 1 net.IW{1,1} ans = –0.22727 net.b ns = [0.72727] Выход сети соответствует целевому вектору. Зададим следующий диапазон весов и смещений, рассчитаем критерий качества w_range=–1:0.1: 0; b_range=0.5:0.1:1; ES = errsurf(P,T, w_range, b_range, 'purelin'); contour(w_range, b_range,ES,20) hold on plot(–2.2727e–001,7.2727e–001, 'x') % Рис.5.4. hold off
На графике знаком x отмечены оптимальные значения веса и смещения для данной сети. Демонстрационный пример demolin1 поясняет структуру линейной сети, построение поверхности ошибок и выбор оптимальных настроек. Обучающее правило наименьших квадратов. Для линейной нейронной сети используется рекуррентное обучающее правило наименьших квадратов (LMS), которое является намного более мощным, чем обучающее правило персептрона. Правило наименьших квадратов, или правило обучения WH(Уидроу – Хоффа), минимизирует среднее значение суммы квадратов ошибок обучения [18]. Процесс обучения нейронной сети состоит в следующем. Авторы алгоритма предположили, что можно оценивать полную среднюю квадратичную погрешность, используя среднюю квадратичную погрешность на каждой итерации. Сформируем частную производную по весам и смещению от квадрата погрешности на k-й итерации:
Подставляя выражение для ошибки в форме
получим
Здесь pj(k) – j-й элемент вектора входа на k-й итерации. Эти соотношения лежат в основе обучающего алгоритма WH
Результат может быть обобщен на случай многих нейронов и представлен в следующей матричной форме:
Здесь ошибка e и смещение b – векторы и a – параметр скорости обучения. При больших значениях a обучение происходит быстро, однако при очень больших значениях может приводить к неустойчивости. Чтобы гарантировать устойчивость процесса обучения, параметр скорости обучения не должен превышать величины 1/max(|l|), где l – собственное значение матрицы корреляций p*pT векторов входа. Используя правило обучения WH и метод наискорейшего спуска, всегда можно обучить сеть так, чтобы ее погрешность была минимальной. М-функция learnwh предназначена для настройки параметров линейной сети и реализует следующее обучающее правило:
где lr – параметр скорости обучения. Максимальное значение параметра скорости обучения, которое гарантирует устойчивость процедуры настройки, вычисляется с помощью М-функции maxlinlr. С помощью демонстрационной программы demolin7 можно исследовать устойчивость процедуры настройки в зависимости от параметра скорости обучения. Процедура обучения Для обучения линейной нейронной сети может быть применена типовая процедура обучения с помощью М-функции train. Эта функция для каждого вектора входа выполняет настройку весов и смещений, используя М-функцию learnp. В результате сеть будет настраиваться по сумме всех коррекций. Будем называть каждый пересчет для набора входных векторов эпохой. Это и отличает процедуру обучения от процедуры адаптации adapt, когда настройка параметров реализуется при представлении каждого отдельного вектора входа. Затем процедура train моделирует настроенную сеть для имеющегося набора векторов, сравнивает результаты с набором целевых векторов и вычисляет среднеквадратичную ошибку. Как только значение ошибки становится меньше заданного или исчерпано предельное число эпох, обучение прекращается. Обратимся к тому же примеру, который использовался при рассмотрении процедуры адаптации, и выполним процедуру обучения. P = [1 –1.2];% Вектор входов T= [0.5, 1]; % Вектор целей % Максимальное значение параметра обучения maxlr = 0.40*maxlinlr(P,'bias'); % Создание линейной сети net = newlin([–2,2],1,[0],maxlr); % Расчет функции критерия качества w_range=–1:0.2:1; b_range=–1:0.2:1; % Диапазоны значений веса и смещения ES = errsurf(P,T, w_range, b_range, 'purelin'); % Построение поверхности функции критерия качества surfc(w_range, b_range, ES) % Рис.5.5,а На рис. 5.5, а построена поверхность функции критерия качества в пространстве параметров сети. В процессе обучения траектория обучения будет перемещаться из начальной точки в точку минимума критерия качества. Выполним расчет и построим траекторию обучения линейной сети для заданных начальных значений веса и смещения. % Расчет траектории обучении x = zeros(1,50); y = zeros(1,50); net.IW{1}=1; net.b{1}= –1; % Начальные значения весов и смещения x(1) = net.IW{1}; y(1) = net.b{1}; net.trainParam.goal = 0.001; % Пороговое значение критерия качества net.trainParam.epochs = 1; % Число эпох % Цикл вычисления весов и смещения для одной эпохи for i = 2:50, [net, tr] = train(net,P,T); x(i) = net.IW{1}; y(i) = net.b{1}; end % Построение линий уровня и траектории обучении clf, contour(w_range, b_range, ES, 20), hold on plot(x, y,'–*'), hold off, % Рис.5.5,б На рис. 5.5, б символом * отмечены значения веса и смещения на каждом шаге обучения; видно, что примерно за 10 шагов при заданной точности (пороговое значение критерия качества)0.001 получим w = –0.22893, b = 0.70519. Это согласуется с решением, полученным с использованием процедуры адаптации.
Рис. 5.5 Если не строить траектории процесса обучения, то можно выполнить обучение, обратившись к М-функции train только 1 раз: net.IW{1}=1; net.b{1}= –1; % Начальные значения веса и смещения net.trainParam.epochs = 50; % Число эпох обучения net.trainParam.goal = 0.001; % Пороговое значение критерия качества [net, tr] = train(net,P,T); TRAINWB, Epoch 0/50, MSE 5.245/0.001. TRAINWB, Epoch 11/50, MSE 0.000483544/0.001. TRAINWB, Performance goal met. net.IW, net.b ans = [–0.22893] ans = [0.70519] На рис. 5.6 показано, как изменяется критерий качества на каждом цикле обучения.
Если повысить точность обучения до значения 0.00001, то получим следующие net.trainParam.goal = 0.00001; [net, tr] = train(net,P,T); net.IW, net.b TRAINWB, Epoch 0/50, MSE 0.000483544/1e–005. TRAINWB, Epoch 6/50, MSE 5.55043e–006/1e–005. TRAINWB, Performance goal met. ans = [–0.22785] ans = [ 0.72495] Повышение точности на 2 порядка приводит к уточнению значений параметров 
Не нашли, что искали? Воспользуйтесь поиском по сайту: ©2015 - 2024 stydopedia.ru Все материалы защищены законодательством РФ.
|
 Рис. 5.1
Рис. 5.1
 Подобно персептрону, линейная сеть задает в пространстве входов разделяющую
Подобно персептрону, линейная сеть задает в пространстве входов разделяющую  Рис. 5.2
Рис. 5.2
 (5.1)
(5.1) – входы сети;
– входы сети;  – соответствующие целевые выходы.
– соответствующие целевые выходы. . (5.2)
. (5.2) Рис. 5.4
Рис. 5.4 (5.3)
(5.3) , (5.4)
, (5.4) (5.5)
(5.5) (5.6)
(5.6) (5.7)
(5.7)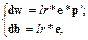 (5.8)
(5.8) а
а
 б
б
 Рис. 5.6
Рис. 5.6