
|
|
Процедуры настройки параметровОпределим процесс обучения персептрона как процедуру настройки весов и смещений с целью уменьшить разность между желаемым (целевым) и истинным сигналами При обучении с учителем задается множество примеров требуемого поведения сети, которое называется обучающим множеством
Здесь p1, p2, …, pQ – входы персептрона, а t1, t2, …, tQ – требуемые (целевые) выходы. При подаче входов выходы персептрона сравниваются с целями. Правило обучения используется для настройки весов и смещений персептрона так, чтобы приблизить значение выхода к целевому значению. Алгоритмы, использующие такие правила обучения, называются алгоритмами обучения с учителем. Для их успешной реализации необходимы эксперты, которые должны предварительно сформировать обучающие множества. Разработка таких алгоритмов рассматривается как первый шаг в создании систем искусственного интеллекта. В этой связи ученые не прекращают спора на тему, можно ли считать алгоритмы обучения с учителем естественными и свойственными природе, или они созданы искусственны. Например, обучение человеческого мозга на первый взгляд происходит без учителя: на зрительные, слуховые, тактильные и прочие рецепторы поступает информация извне и внутри мозга происходит некая самоорганизация. Однако нельзя отрицать и того, что в жизни человека немало учителей – и в буквальном, и в переносном смысле, – которые координируют реакции на внешние воздействия. Вместе с тем, как бы ни развивался спор приверженцев этих двух концепций обучения, представляется, что обе они имеют право на существование. И рассматриваемое нами правило обучения персептрона относится к правилу обучения с учителем. При обучении без учителя веса и смещения изменяются только в связи с изменениями входов сети. В этом случае целевые выходы в явном виде не задаются. Главная черта, делающая обучение без учителя привлекательным, – это его самоорганизация, обусловленная, как правило, использованием обратных связей. Что касается процесса настройки параметров сети, то он организуется с использованием одних и тех же процедур. Большинство алгоритмов обучения без учителя применяется при решении задач кластеризации данных, когда необходимо разделить входы на конечное число классов. Что касается персептронов, рассматриваемых в этой главе, то хотелось бы надеяться, что в результате обучения может быть построена такая сеть, которая обеспечит правильное решение, когда на вход будет подан сигнал, который отличается от тех, которые Правила настройки Настройка параметров (обучение) персептрона осуществляется с использованием обучающего множества. Обозначим через pвектор входов персептрона, а через t– вектор соответствующих желаемых выходов. Цель обучения – уменьшить погрешность e = a – t, которая равна разности между реакцией нейрона a и вектором цели t. Правило настройки (обучения) персептрона должно зависеть от величины погрешности e. Вектор цели t может включать только значения 0 и 1, поскольку персептрон При настройке параметров персептрона без смещения и с единственным нейроном возможны только 3 ситуации: 1. Для данного вектора входа выход персептрона правильный (a = t и e = t – а = 0) и тогда вектор весов w не претерпевает изменений. 2. Выход персептрона равен 0, а должен быть равен 1 (a = 0, t = 1 и e = t – 0 = 1). В этом случае вход функции активацииwТp отрицательный и его необходимо скорректировать. Добавим к вектору весов w вектор входа p, и тогда произведение (wT + pT) p = 3. Выход нейрона равен 1, а должен быть равен 0 (а = 0, t = 1 и e = t – a= –1). В этом случае вход функции активации wТpположительный и его необходимо скорректировать. Вычтем из вектора весов w вектор входа p, и тогда произведение (wT – pT) p = Теперь правило настройки (обучения) персептрона можно записать, связав изменение вектора весов Dwс погрешностью e = t – a:
Все 3 случая можно описать одним соотношением:
Можно получить аналогичное выражение для изменения смещения, учитывая, что смещение можно рассматривать как вес для единичного входа:
В случае нескольких нейронов эти соотношения обобщаются следующим образом:
Тогда правило настройки (обучения) персептрона можно записать в следующей форме:
Описанные соотношения положены в основу алгоритма настройки параметров персептрона, который реализован в ППП Neural Network Toolbox в виде М-функции learnp. Каждый раз при выполнении функции learnp будет происходить перенастройка параметров персептрона. Доказано, что если решение существует, то процесс обучения персептрона сходится за конечное число итераций. Если смещение не используется, функция learnp ищет решение, изменяя только вектор весов w. Это приводит к нахождению разделяющей линии, перпендикулярной вектору w и которая должным образом разделяет векторы входа. Рассмотрим простой пример персептрона с единственным нейроном и двухэлементным вектором входа: net = newp([–2 2;–2 2],1); Определим смещение b равным 0, а вектор весов w равным [1 –0.8]: net.b{1} = 0; w = [1 –0.8]; net.IW{1,1} = w; Обучающее множество зададим следующим образом: p = [1; 2]; t = [1]; Моделируя персептрон, рассчитаем выход и ошибку на первом шаге настройки (обучения): a = sim(net,p) a = 0 e = t–a e = 1 Наконец, используя М-функцию настройки параметров learnp, найдем требуемое dw = learnp(w,p,[ ],[ ],[ ],[ ],e,[ ],[ ],[ ]) dw = 1 2 Тогда новый вектор весов примет вид: w = w + dw w = 2.0000 1.2000 Заметим, что описанные выше правило и алгоритм настройки (обучения) персептрона гарантируют сходимость за конечное число шагов для всех задач, которые могут быть решены с использованием персептрона. Это в первую очередь задачи классификации векторов, которые относятся к классу линейно отделимых,когда все пространство входов можно разделить на 2 области некоторой прямой линией, в многомерном случае – гиперплоскостью. Демонстрационный пример nnd4pr позволяет выполнить многочисленные эксперименты по настройке (обучению) персептрона для решения задачи классификации входных векторов. Процедура адаптации Многократно используя М-функции sim и learnp для изменения весов и смещения персептрона, можно в конечном счете построить разделяющую линию, которая решит задачу классификации, при условии, что персептрон может решать ее. Каждая реализация процесса настройки с использованием всего обучающего множества называется проходом или циклом. Такой цикл может быть выполнен с помощью специальной функции адаптации adapt. При каждом проходе функция adapt использует обучающее множество, вычисляет выход, погрешность и выполняет подстройку параметров персептрона. Заметим, что процедура адаптации не гарантирует, что синтезированная сеть выполнит классификацию нового вектора входа. Возможно, потребуется новая настройка матрицы весов W и вектора смещений b с использованием функции adapt. Чтобы пояснять процедуру адаптации, рассмотрим простой пример. Выберем персептрон с одним нейроном и двухэлементным вектором входа (рис. 4.5).
Эта сеть и задача, которую мы собираемся рассматривать, достаточно просты, так что можно все расчеты выполнить вручную. Предположим, что требуется с помощью персептрона решить задачу классификации векторов, если задано следующее обучающее множество:
Используем нулевые начальные веса и смещение. Для обозначения переменных на каждом шаге используем индекс в круглых скобках. Таким образом, начальные значения вектора весов wT(0) и смещения b(0) равны соответственно wT(0) = [0 0] и b(0) = 0. Вычислим выход персептрона для первого вектора входа p1, используя начальные
Выход не совпадает с целевым значением t1, и необходимо применить правило настройки (обучения) персептрона, чтобы вычислить требуемые изменения весов и смещений:
Вычислим новые веса и смещение, используя введенные ранее правила обучения персептрона.
Обратимся к новому вектору входа p2, тогда
В этом случае выход персептрона совпадает с целевым выходом, так что погрешность равна 0 и не требуется изменений в весах или смещении. Таким образом,
Продолжим этот процесс и убедимся, что после третьего шага настройки не изменились:
а после четвертого приняли значение
Чтобы определить, получено ли удовлетворительное решение, требуется сделать один проход через все векторы входа, чтобы проверить, соответствуют ли решения обучающему множеству. Вновь используем первый член обучающей последовательности и получаем:
Переходя ко второму члену, получим следующий результат:
Этим заканчиваются ручные вычисления. Теперь выполним аналогичные расчеты, используя М-функцию adapt. Вновь сформируем модель персептрона, изображенного на рис. 4.5: net = newp([–2 2;–2 2],1); Введем первый элемент обучающего множества p = {[2; 2]}; t = {0}; Установим параметр passes (число проходов) равным 1 и выполним 1 шаг настройки: net.adaptParam.passes = 1; [net,a,e] = adapt(net,p,t); a a = [1] e e = [–1] Скорректированные вектор весов и смещение равны twts = net.IW{1,1} twts = –2 –2 tbiase = net.b{1} tbiase = –1 Это совпадает с результатами, полученными при ручном расчете. Теперь можно ввести второй элемент обучающего множества и т. д., т. е. повторить всю процедуру ручного счета и получить те же результаты. Но можно эту работу выполнить автоматически, задав сразу все обучающее множество net = newp([–2 2;–2 2],1); net.trainParam.passes = 1; p = {[2;2] [1;–2] [–2;2] [–1;1]}; t = {0 1 0 1}; Теперь обучим сеть: [net,a,e] = adapt(net,p,t); Возвращаются выход и ошибка: a a = [1] [1] [0] [0] e e = [–1] [0] [0] [1] Скорректированные вектор весов и смещение равны twts = net.IW{1,1} twts = –3 –1 tbiase = net.b{1} tbiase = 0 Моделируя полученную сеть по каждому входу, получим: a1 = sim(net,p) a1 = [0] [0] [1] [1] Можно убедиться, что не все выходы равны целевым значениям обучающего множества. Это означает, что следует продолжить настройку персептрона. Выполним еще 1 цикл настройки: [net,a,e] = adapt(net,p,t); a a = [0] [0] [0] [1] e e = [0] [1] [0] [0] twts = net.IW{1,1} twts = 2 –3 tbiase = net.b{1} tbiase = 1 a1 = sim(net,p) a1 = [0] [1] [0] [1] Теперь решение совпадает с целевыми выходами обучающего множества и все входы классифицированы правильно. Если бы рассчитанные выходы персептрона не совпали с целевыми значениями, то необходимо было бы выполнить еще несколько циклов настройки, применяя М-функцию adapt и проверяя правильность получаемых результатов. Для усвоения изложенного материала можно обратиться к демонстрационным программам, в частности к программе demop1, которая решает задачу классификации с помощью простого персептрона. Как следует из сказанного выше, для настройки (обучения) персептрона применяется процедура адаптации, которая корректирует параметры персептрона по результатам обработки каждого входного вектора. Применение М-функции adapt гарантирует, что любая задача классификации с линейно отделимыми векторами будет решена за конечное число циклов настройки. Для настройки (обучения) персептрона можно было бы воспользоваться также Нейронные сети на основе персептрона имеют ряд ограничений. Во-первых, выход персептрона может принимать только одно из двух значений (0 или 1); во-вторых, персептроны могут решать задачи классификации только для линейно отделимых наборов векторов. Если с помощью прямой линии или гиперплоскости в многомерном случае можно разделить пространство входов на 2 области, в которых будут расположены векторы входа, относящиеся к различным классам, то векторы входа считаются линейно отделимыми. Если векторы входа линейно отделимы, то доказано, что при использовании процедуры адаптации задача классификации будет решена за конечное время. Если векторы входа линейно неотделимы, то процедура адаптации не в состоянии классифицировать все векторы должным образом. Демонстрационная программа demop6 иллюстрирует тщетность попытки классифицировать векторы входа, которые линейно неотделимы. Для решения более сложных задач можно использовать сети с несколькими персептронами. Например, для классификации четырех векторов на 4 группы можно построить сеть с двумя персептронами, чтобы сформировать 2 разделяющие линии и таким образом приписать каждому вектору свою область. Отметим еще одну особенность процесса обучения персептрона. Если длина некоторого вектора входа намного больше или меньше длины других векторов, то для обучения может потребоваться значительное время. Это обусловлено тем, что алгоритм настройки связан с добавлением или вычитанием входного вектора из текущего вектора весов. Можно сделать время обучения нечувствительным к большим или малым выбросам векторов входа, если несколько видоизменить исходное правило обучения персептрона:
Действительно, из этого соотношения следует, что чем больше компоненты вектора входа p, тем большее воздействие он оказывает на изменение элементов вектора w. Можно уравновесить влияние больших или малых компонент, если ввести масштабирование вектора входа. Решение состоит в том, чтобы нормировать входные данные так, чтобы воздействие любого вектора входа имело примерно равный вклад:
Нормированное правило обучения персептрона реализуется М-функцией learnpn. Этот алгоритм требует несколько большего времени, но значительно сокращает количество циклов обучения, когда встречаются выбросы векторов входа. Демонстрационная программа demop5 иллюстрирует это правило обучения. В заключение следует отметить, что основное назначение персептронов – решать задачи классификации. Они великолепно справляются с задачей классификации линейно отделимых векторов; сходимость гарантируется за конечное число шагов. Длительность обучения чувствительна к выбросам длины отдельных векторов, но и в этом случае решение может быть построено. Однослойный персептрон может классифицировать только линейно отделимые векторы. Возможные способы преодолеть эту трудность предполагают либо предварительную обработку с целью сформировать линейно отделимое множество входных векторов, либо использование многослойных персептронов. Можно также применить другие типы нейронных сетей, например линейные сети или сети с обратным распространением, которые могут выполнять классификацию линейно неотделимых векторов входа. Линейные сети Обсуждаемые в этой главе линейные нейронные сети по своей структуре аналогичны персептрону и отличаются лишь функцией активации, которая является линейной. Выход линейной сети может принимать любое значение, в то время как выход персептрона ограничен значениями 0 или 1. Линейные сети, как и персептроны, способны решать только линейно отделимые задачи классификации, однако в них используется другое правило обучения, основанное на методе наименьших квадратов, которое является более мощным, чем правило обучения персептрона. Настройка параметров выполняется таким образом, чтобы обеспечить минимум ошибки. Поверхность ошибки как функция входов имеет единственный минимум, и определение этого минимума не вызывает трудностей. В отличие от персептрона настройка линейной сети может быть выполнена с помощью как процедуры адаптации, так и процедуры обучения; в последнем случае используется правило обучения WH (Widrow – Hoff). Кроме того, в главе рассматриваются адаптируемые линейные нейронные сети ADALINE (ADAptive Linear Neuron networks), которые позволяют корректировать веса По команде help linnet можно получить следующую информацию об М-функциях, входящих в состав ППП Neural Network Toolbox и относящихся к построению линейных нейронных сетей:
Следует обратить внимание, что в версии ППП Neural Network Version 3.0.1 (R11) 
Не нашли, что искали? Воспользуйтесь поиском по сайту: ©2015 - 2024 stydopedia.ru Все материалы защищены законодательством РФ.
|
 (4.3)
(4.3)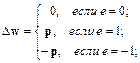 (4.4а)
(4.4а) . (4.4б)
. (4.4б) (4.5)
(4.5) (4.6)
(4.6) (4.7)
(4.7)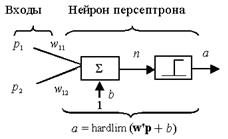 Рис. 4.5
Рис. 4.5 (4.8)
(4.8) (4.9)
(4.9)
 (4.10)
(4.10) (4.11)
(4.11) (4.12)
(4.12) (4.13)
(4.13) (4.14)
(4.14) (4.15)
(4.15) (4.16)
(4.16) (4.17)
(4.17) (4.18)
(4.18) . (4.19)
. (4.19)